ProLU: A Nonlinearity for Sparse Autoencoders
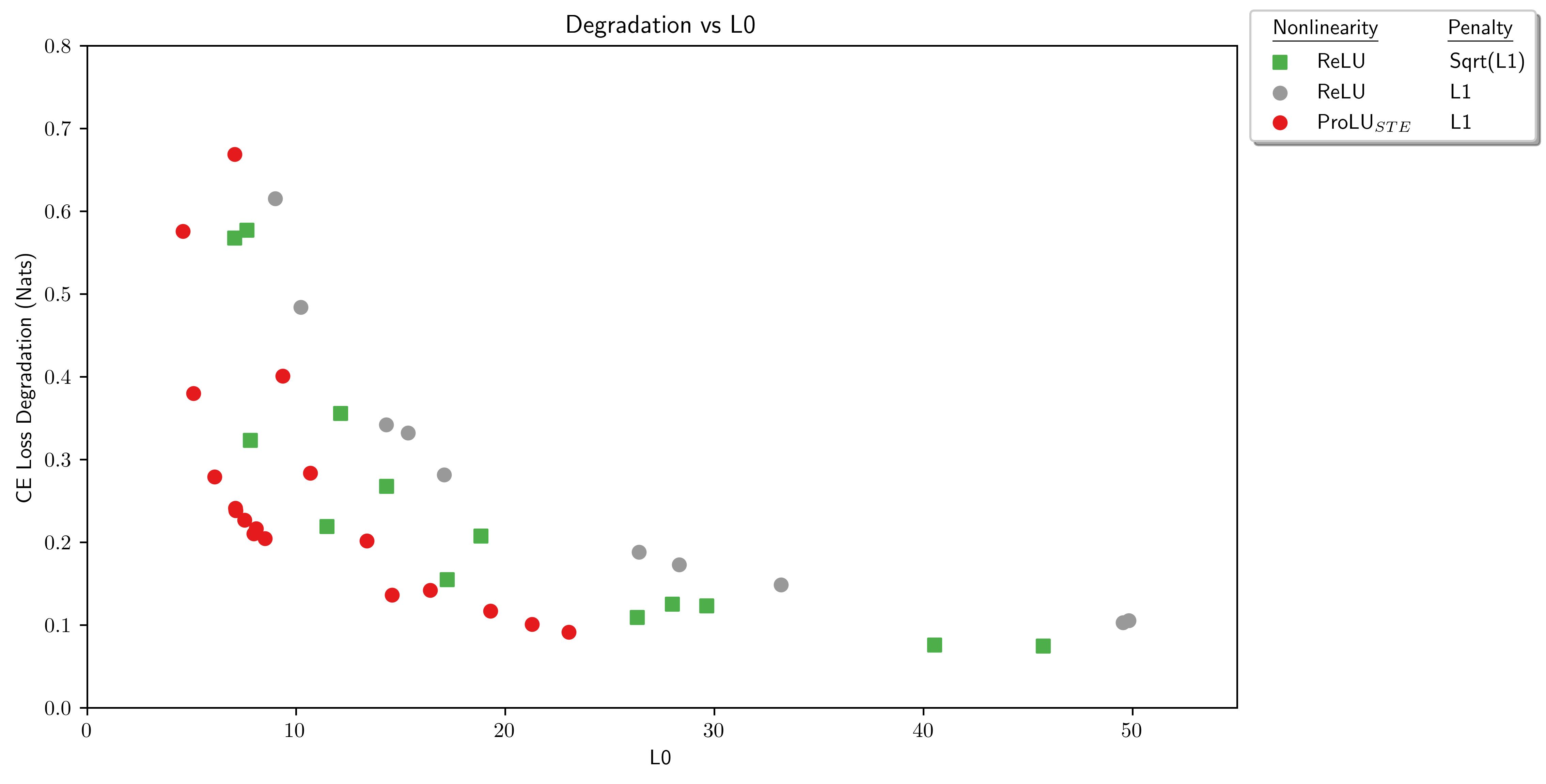
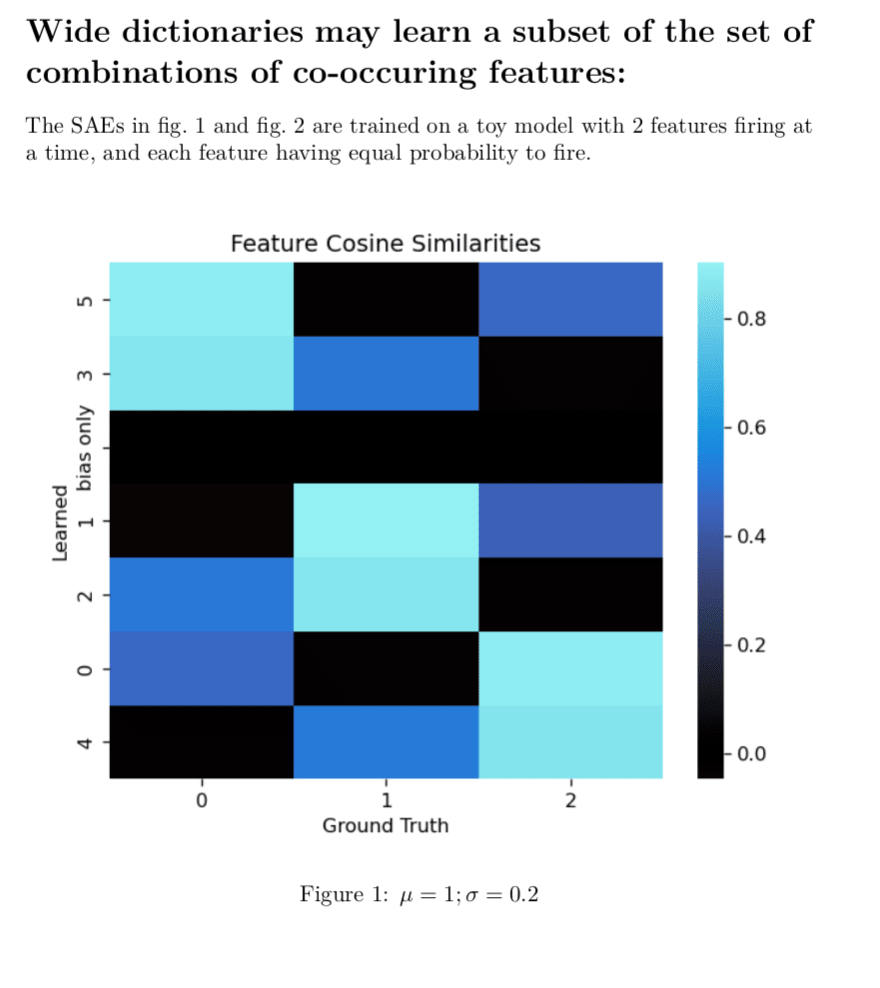
Abstract This paper presents ProLU, an alternative to ReLU for the activation function in sparse autoencoders that produces a pareto improvement over both standard sparse autoencoders trained with an L1 penalty and sparse autoencoders trained with a Sqrt(L1) penalty. ProLU(mi,bi)={miif mi+bi>0 and mi>00otherwiseSAEProLU(x)=ProLU((x−bdec)Wenc,benc)Wdec+bdec The gradient wrt. b is zero, so...
Apr 23, 202444
You specify glucose. Have you tried small doses of sucrose/fructose/fruit and found it to not work in the same way?
Have you tried larger doses?
This is very interesting. I'm very curious to hear how the self-blinded experiment goes.