All of Gurkenglas's Comments + Replies
I just meant the "guts of the category theory" part. I'm concerned that anyone says that it should be contained (aka used but not shown), and hope it's merely that you'd expect to lose half the readers if you showed it. I didn't mean to add to your pile of work and if there is no available action like snapping a photo that takes less time than writing the reply I'm replying to did, then disregard me.
What if you say that when it was fully accurate?
give me the guts!!1
don't polish them, just take a picture of your notes or something.
Congratulations on changing your mind!
It’s sorta suspicious that I only realized those now, after I officially dropped the project
You should try dropping your other idea and seeing if you come up with reasons that one is wrong too! And/or pick this one up again, then come up with reasons it's a good idea after all. In the spirit of "You can't know if something is a good idea until you resolve to do it"!
In general, I wish this year? (*checks* huh, only 4 months.) of planning this project had involved more empiricism. For example, you could've just checked whether a language model trained on ocean sounds can say what the animals are talking about.
Hmm. Sounds like it was not enough capsaicin. Capsaicin will drive off bears, I hear. I guess you'd need gloves for food, or permanent gloves without the nail polish. Could you use one false nail as a chew toy?
Try mixing in capsaicin?
flavored nail polish?
Link an example, along with how cherry-picked it is?
To prepare for abundant cognition you can install a keylogger.
As a kid, I read about vacuum decay in a book and told the other kids at school about it. A year? later one kid asked me how anyone knows about it. Mortified that I didn't think of that, I told him that I made it up. ("I knew it >:D!") It is the one time I remember outside games of telling someone something I disbelieve so that they'll believe it, and ever since remembering the scene as an adult I'm failing to track down that kid :(.
Oh, you're using AdamW everywhere? That might explain the continuous training loss increase after each spike, with AdamW needing time to adjust to the new loss landscape...
Lower learning rate leads to more spikes? Curious! I hypothesize that... it needs a small learning rate to get stuck in a narrow local optimum, and then when it reaches the very bottom of the basin, you get a ~zero gradient, and then the "normalize gradient vector to step size" step is discontinuous around zero.
Experiments springing to mind are:
1. Do you get even fewer spikes if you incr...
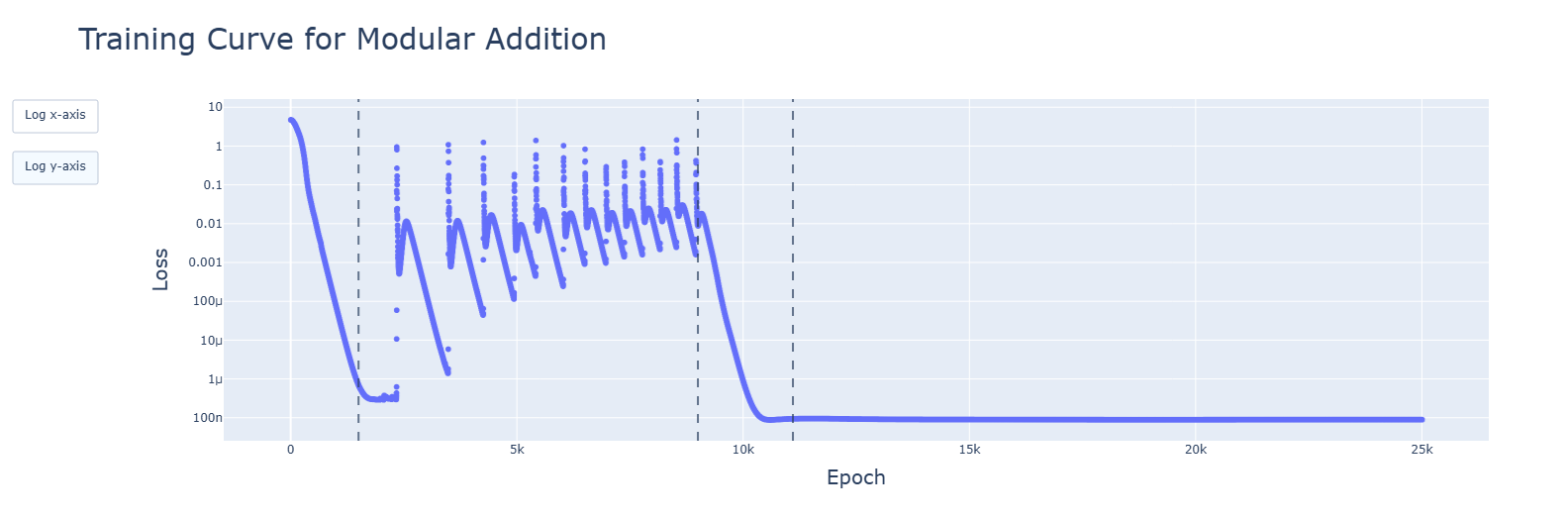
My eyes are drawn to the 120 or so downward tails in the latter picture; they look of a kind with the 14 in https://39669.cdn.cke-cs.com/rQvD3VnunXZu34m86e5f/images/2c6249da0e8f77b25ba007392087b76d47b9a16f969b21f7.png/w_1584. What happens if you decrease the learning rate further in both cases? I imagine the spikes should get less tall, but does their number change? Only dot plots, please, with the dots drawn smaller, and red dots too on the same graph.
{kind=link}
I don't see animations in the drive folder or cached in Grokking_Demo_additional_2.ipynb (the most recent...
Can a eat that -1?
What is x and why isn't it cancelling?
When splitting the conjuction, Bob should only have to place $4 in escrow, since that is the most in the red that Bob could end up. (Unless someone might privately prove P&Q to collect Alice's bounty before collecting both of Bob's? But surely Bob first bought exclusive access to Alice's bounty from Alice.)
Mimicing homeostatic agents is not difficult if there are some around. They don't need to constantly decide whether to break character, only when there's a rare opportunity to do so.
If you initialize a sufficiently large pile of linear algebra and stir it until it shows homeostatic behavior, I'd expect it to grow many circuits of both types, and any internal voting on decisions that only matter through their long-term effects will be decided by those parts that care about the long term.
Having apparently earned some cred, I will dare give some further quick hints without having looked at everything you're doing in detail, expecting a lower hit rate.
- Have you rerun the experiment several times to verify that you're not just looking at initialization noise?
- If that's too expensive, try making your models way smaller and see if you can get the same results.
- After the spikes, training loss continuously increases, which is not how gradient descent is supposed to work. What happens if you use a simpler optimizer, or reduce the learning rate?
- Some o
Publish the list?
I'm glad that you're willing to change your workflow, but you have only integrated my parenthetical, not the more important point. When I look at https://res.cloudinary.com/lesswrong-2-0/image/upload/f_auto,q_auto/v1/mirroredImages/tzkakoG9tYLbLTvHG/lelcezcseu001uyklccb, I see interesting behavior around the first red dashed line, and wish I saw more of it. You ought to be able to draw 25k blue points in that plot, one for every epoch - your code already generates that data, and I advise that you cram as much of your code's data into the pictures you look at as you reasonably can.
The forgetful functor FiltSet to Set does not have a left adjoint, and egregiously so - you have added just enough structure to rule out free filtered sets, and may want to make note of where this is important..
(S⊗-) has a right adjoint, suggesting the filtered structure to impose on function sets: The degree of a map f:S->T would be how far it falls short of being a morphism, , as this is what makes S⊗U->T one-to-one with U->(S->T).
...what I meant is that plots like this look like they would have had more to say if you had plotted the y value after e.g. every epoch. No reason to throw away perfectly good data, you want to guard against not measuring what you think you are measuring by maximizing the bandwidth between your code and your eyes. (And the lines connecting those data points just look like more data while not actually giving extra information about what happened in the code.)
Some of these plots look like they ought to be higher resolution, especially when Epoch is on the x axis. Consider drawing dots instead of lines to make this clearer.
All we need to create is a Ditto. A blob of nanotech wouldn't need 5 seconds to take the shape of the surface of an elephant and start mimicing its behavior; is it good enough to optionally do the infilling later if it's convenient?
Try a base model?
Buying at 12% and selling at 84% gets you 2.8 bits.
Edit: Hmm, that's if he stakes all his cred, by Kelly he only stakes some of it so you're right, it probably comes out to about 1 bit.
The convergent reason to simulate a world is to learn what happens there. When to intervene with letters depends on, uh. Why are you doing that at all?
(Edit: I suppose a congratulatory party is in order when they simulate you back with enough optimizations that you can talk to each other in real time using your mutual read access.)
I deferred my decision to after visiting the Learning Theory course. At the time, the timing had made them seem vaguely affiliated with this programme.
Can you just give every thief a body camera?
Re first, yep, I missed that :(. M does sound like a more worthy barrier than U. Do you have a working example of a (U,M) where some state machine performs well in a manner that's hard to detect?
Re second, I realized that this only allows discrete utilities but didn't think to therefore try a π' that does an exhaustive search over policies ^^. (I assume you are setting "uncomputable to measure performance because that involves the Solomonoff prior" aside here.) Even so, undecidability of whether 000... and 111... get the same utility sounds like a bug. Wha...
Regarding 17.4.Open:
Consider π' which try all state machines up to a size and imitate the one that performs best on (U,M); this would tighten the O(nlogn) bound to O(BB^-1(n)).
This fails because your utility functions return constructive real numbers, which don't implement comparison. I suggest that you make it possible to compare utilities.[1]
In which case we get: Within every decidable machine class where every member halts, agents are uncomputably smol.
- ^
Such as by
making P(s,s') return the order of U(s) and U(s').
If you didn't feel comfortable running it overnight, why did you publish the instructions for replicating it?
I'm hoping more for some stepping stones between the pre-theoretic concept of "structural" and the fully formalized 99%-clause. If we could measure structuralness more directly we should be able to get away with less complexity in the rest of the conjecture.
Ultimately, though, we are interested in finding a verifier that accepts or rejects based on a structural explanation of the circuit; our no-coincidence conjecture is our best attempt to formalize that claim, even if it is imperfect.
Can you say more about what made you decide to go with the 99% clause? Did you consider any alternatives?
This does go in the direction of refuting it, but they'd still need to argue that linear probes improve with scale faster than they do for other queries; a larger model means there are more possible linear probes to pick the best from.
I had that vibe from the abstract, but I can try to guess at a specific hypothesis that also explains their data: Instead of a model developing preferences as it grows up, it models an Assistant character's preferences from the start, but their elicitation techniques work better on larger models; for small models they produce lots of noise.
Ah, oops. I think I got confused by the absence of L_2 syntax in your formula for FVU_B. (I agree that FVU_A is more principled ^^.)
https://github.com/jbloomAus/SAELens/blob/main/sae_lens/evals.py#L511 sums the numerator and denominator separately, if they aren't doing that in some other place probably just file a bug report?
Thanks, edited. If we keep this going we'll have more authors than users x)
Thanks, edited. Performance is not the only benefit, see https://www.lesswrong.com/posts/MHqwi8kzwaWD8wEQc/would-you-like-me-to-debug-your-math?commentId=CrC2
Account settings let you set mentions to notify you by email :)
The action space is too large for this to be infeasible, but at a 101 level, if the Sun spun fast enough it would come apart, and angular momentum is conserved so it's easy to add gradually.
Can this program that you've shown to exist be explicitly constructed?
It sounds like you're trying to define unfair as evil.