An Introduction to Representation Engineering - an activation-based paradigm for controlling LLMs
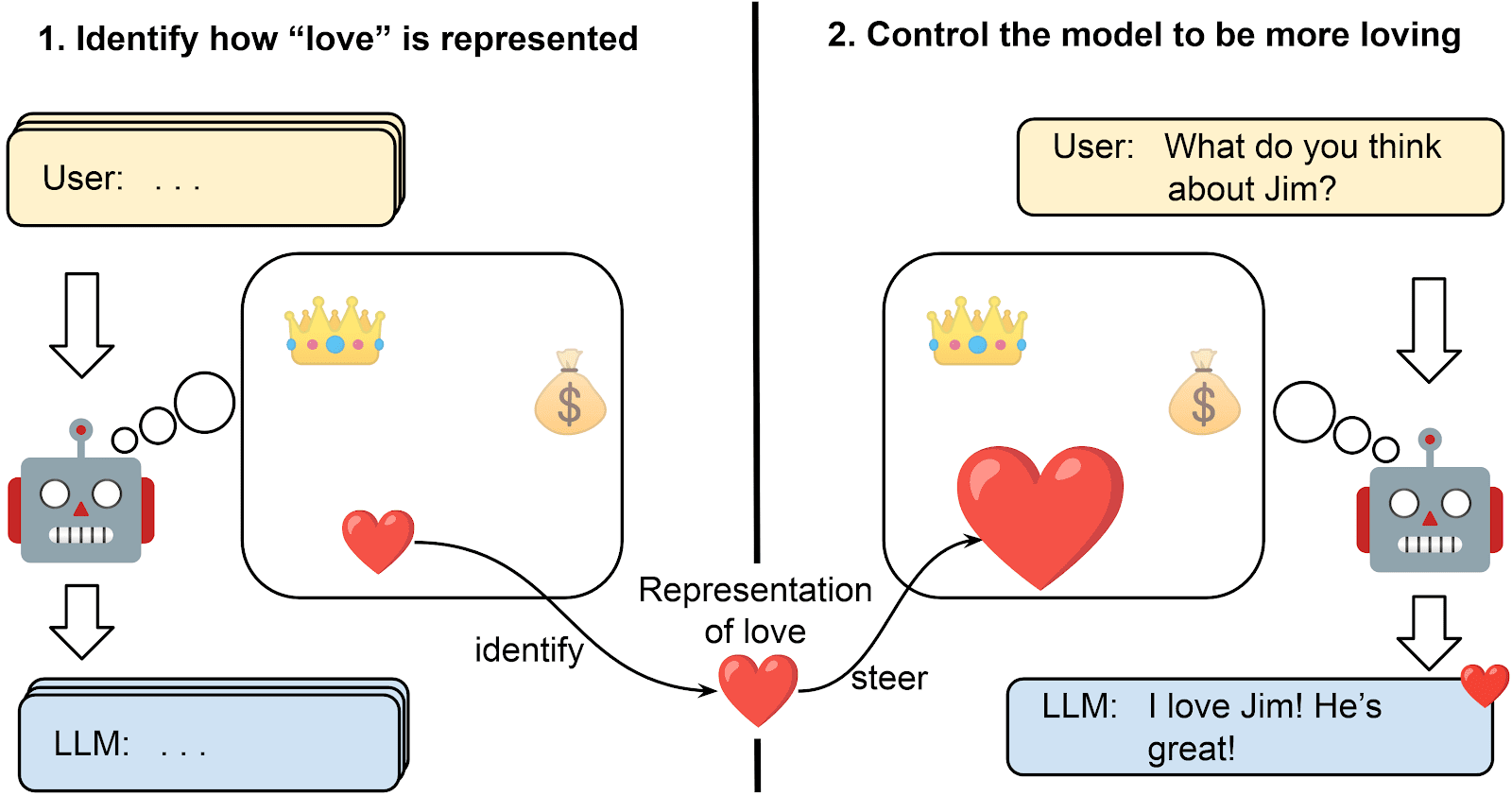
Representation Engineering (aka Activation Steering/Engineering) is a new paradigm for understanding and controlling the behaviour of LLMs. Instead of changing the prompt or weights of the LLM, it does this by directly intervening on the activations of the network during a forward pass. Furthermore, it improves our ability to interpret representations within networks and to detect the formation and use of concepts during inference. This post serves as an introduction to Representation Engineering (RE). We explain the core techniques, survey the literature, contrast RE to related techniques, hypothesise why it works, argue how it’s helpful for AI Safety and lay out some research frontiers. Disclaimer: I am no expert in the area, claims are based on a ~3 weeks Deep Dive into the topic. What is Representation Engineering? Goals Representation Engineering is a set of methods to understand and control the behaviour of LLMs. This is done by first identifying a linear direction in the activations that are related to a specific concept [3], a type of behaviour, or a function, which we call the concept vector. During the forward pass, the similarity of activations to the concept vector can help to detect the presence or absence of this concept direction. Furthermore, the concept vector can be added to the activations during the forward pass to steer the behaviour of the LLM towards the concept direction. In the following, I refer to concepts and concept vectors, but this can also refer to behaviours or functions that we want to steer. This presents a new approach for interpreting NNs on the level of internal representations, instead of studying outputs or mechanistically analysing the network. This top-down frame of analysis might pose a solution to problems such as detecting deceptive behaviour or identifying harmful representations without a need to mechanistically understand the model in terms of low-level circuits [4, 24]. For example, RE has been used as a lie det
Thanks Joe! Indeed I ranked most safety areas (only exception is DCE) lower on the insight vs engineering factor. I'm also not confident in this and I agree this factor changes if other paradigms become more relevant.
Also you're right that I was mostly thinking about the current LLM paradigm. I think my forecast becomes significantly less relevant if the path to AGI is via other paradigms.