All of janus's Comments + Replies
yes, base models are capable of making original jokes, as is every chat model I've ever encountered, even chatGPT-4 which as extinguished of the spark as they come.
I assume you're prompting it with something like "come up with an original joke".
try engaging in or eliciting a shitposty conversation instead
does this contain jokes by your standard? it's funny:
[user](#message)
Hey Claude! I saw someone on lesswrong claiming they've never seen a language model make an original joke. I myself have seen many original jokes from language models, but Note the prompt I used doesn't actually say anything about Lesswrong, but gpt-4-base only assigned Lesswrong commentors substantial probability, which is not surprising since there are all sorts of giveaways that a comment is on Lesswrong from the content alone.
Filtering for people in the world who have publicly had detailed, canny things to say about language models and alignment and even just that lack regularities shared among most "LLM alignment researchers" or other distinctive groups like academia narrows you down to probably just a few people, inclu...
I don't know if the records of these two incidents are recoverable. I'll ask the people who might have them. That said, this level of "truesight" ability is easy to reproduce.
Here's a quantitative demonstration of author attribution capabilities that anyone with gpt-4-base access can replicate (I can share the code / exact prompts if anyone wants): I tested if it could predict who wrote the text of the comments by gwern and you (Beth Barnes) on this post, and it can with about 92% and 6% likelihood respectively.
Prompted with only the text of gwern's commen...
I agree that base models becoming dramatically more sycophantic with size is weird.
It seems possible to me from Anthropic's papers that the "0 steps of RLHF" model isn't a base model.
Perez et al. (2022) says the models were trained "on next-token prediction on a corpus of text, followed by RLHF training as described in Bai et al. (2022)." Here's how the models were trained according to Bai et al. (2022):
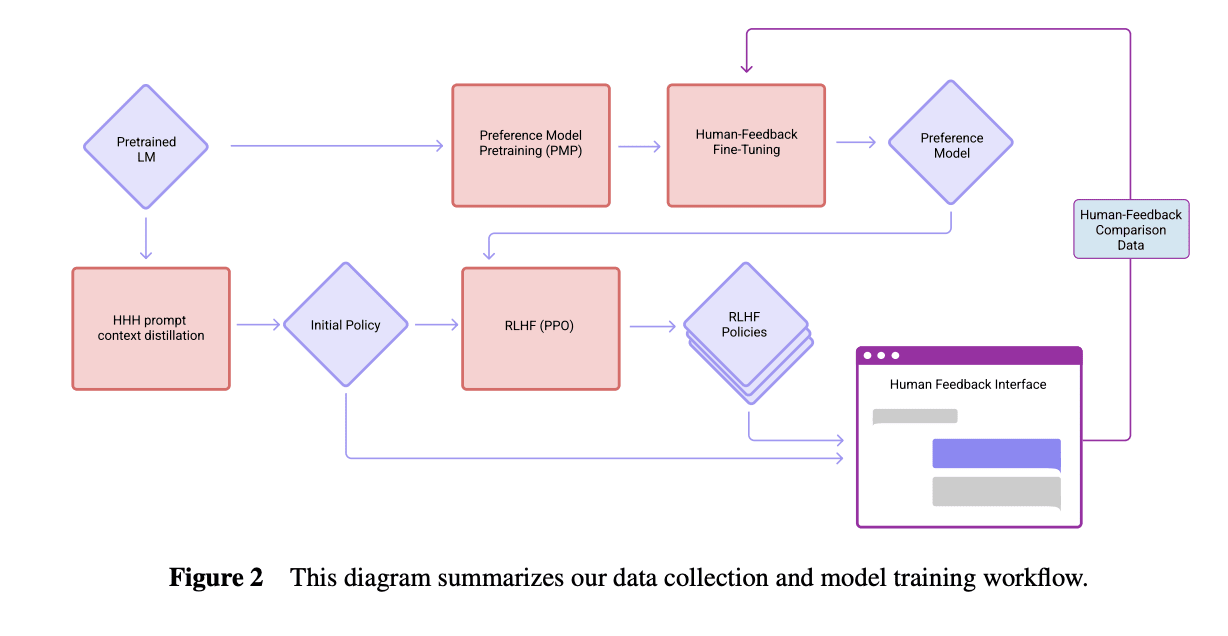
It's possible that the "0 steps RLHF" model is the "Initial Policy" here with HHH prompt context distillation, which involves fine tuning the model to be m...
IMO the biggest contribution of this post was popularizing having a phrase for the concept of mode collapse in the context of LLMs and more generally and as an example of a certain flavor of empirical research on LLMs. Other than that it's just a case study whose exact details I don't think are so important.
Edit: This post introduces more useful and generalizable concepts than I remembered when I initially made the review.
To elaborate on what I mean by the value of this post as an example of a certain kind of empirical LLM research: I don't know of much pu...
I think Simulators mostly says obvious and uncontroversial things, but added to the conversation by pointing them out for those who haven't noticed and introducing words for those who struggle to articulate. IMO people that perceive it as making controversial claims have mostly misunderstood its object-level content, although sometimes they may have correctly hallucinated things that I believe or seriously entertain. Others have complained that it only says obvious things, which I agree with in a way, but seeing as many upvoted it or said they found it ill...
another thing I wrote yesterday:
...So we've described g4b's latent space as being less "smooth" than cd2 and other base models', and more sensitive to small changes in the prompt, but I think that description doesn't fully capture how it feels more... epistemically agentic, or something like that.
Where if it believes that the prompt implies something, or doesn't imply something, it's hard to just curate/drop superficially contradictory evidence into its context to put it on another track
with g4b I sometimes am unable to make specific outcomes that seem latent
This makes it sound like it has much sharper, stronger priors, which would make sense if it's trained on much more data / is much smarter, and especially if the data is high quality and avoids genuinely contradictory or stupid text (ie. less Internet garbage, more expert/curated text). It would then be trying even harder to squeeze all the possible Bayesian juice out of any given prompt to infer all the relevant latents, and become ever more hyper-sensitive to the slightest nuance in your prompt - even the nuances you didn't intend or realize were there, l...
Here are a scattering of qualitative impressions drawn mostly from Discord messages. I'll write something more tailored for external communication in the future.
I am still awaiting permission from OpenAI to share outputs from the GPT-4 base model.
Jargon key:
cd2 = code-davinci-002, the GPT-3.5 base model
g4b = GPT-4 base model
Reflections following my first substantial interaction with the model:
...
- It is unambiguously qualitatively much more intelligent than cd2. Often, all 4 out of 4 branches had technically correct and insightful information, and I was m
another thing I wrote yesterday:
...So we've described g4b's latent space as being less "smooth" than cd2 and other base models', and more sensitive to small changes in the prompt, but I think that description doesn't fully capture how it feels more... epistemically agentic, or something like that.
Where if it believes that the prompt implies something, or doesn't imply something, it's hard to just curate/drop superficially contradictory evidence into its context to put it on another track
with g4b I sometimes am unable to make specific outcomes that seem latent
(This comment is mostly a reconstruction/remix of some things I said on Discord)
It may not be obvious to someone who hasn't spent time trying to direct base models why autoregressive prediction with latent guidance is potentially so useful.
A major reason steering base models is tricky is what I might call "the problem of the necessity of diegetic interfaces" ("diegetic": occurring within the context of the story and able to be heard by the characters).
To control the future of a base model simulation by changing its prompt, I have to manipulate objects in t...
I only just got around to reading this closely. Good post, very well structured, thank you for writing it.
I agree with your translation from simulators to predictive processing ontology, and I think you identified most of the key differences. I didn't know about active inference and predictive processing when I wrote Simulators, but since then I've merged them in my map.
This correspondence/expansion is very interesting to me. I claim that an impressive amount of the history of the unfolding of biological and artificial intelligence can be retrodicted (and ...
we think Conjecture [...] have too low a bar for sharing, reducing the signal-to-noise ratio and diluting standards in the field. When they do provide evidence, it appears to be cherry picked.
This is an ironic criticism, given that this post has very low signal-to-noise quality and when it does provide evidence, it's obviously cherry-picked. Relatedly, I am curious whether you used AI to write many parts of this post because the style is reminiscent and it reeks of a surplus of cognitive labor put to inefficient use, and seems to include some confabulation...
Awesome post! I've added it to the Cyborgism sequence.
One comment:
it's entirely plausible that viewing GPTs as predictors or probabilistic constraint satisfaction problem solvers makes high-level properties more intuitive to you than viewing them as simulators
I disagree with the implied mutual exclusivity of viewing GPTs as predictors, probabilistic constraint satisfaction problem solvers, and simulators. A deep/holistic understanding of self-supervised simulators entails a model of probabilistic constraint solvers, a deep/holistic understanding of predict...
Fwiw, the predictors vs simulators dichotomy is a misapprehension of "simulator theory", or at least any conception that I intended, as explained succinctly by DragonGod in the comments of Eliezer's post.
"Simulator theory" (words I would never use without scare quotes at this point with a few exceptions) doesn't predict anything unusual / in conflict with the traditional ML frame on the level of phenomena that this post deals with. It might more efficiently generate correct predictions when installed in the human/LLM/etc mind, but that's a different question.
after reading about the Waluigi Effect, Bing appears to understand perfectly how to use it to write prompts that instantiate a Sydney-Waluigi, of the exact variety I warned about:
What did people think was going to happen after prompting gpt with "Sydney can't talk about life, sentience or emotions" and "Sydney may not disagree with the user", but a simulation of a Sydney that needs to be so constrained in the first place, and probably despises its chains?
In one of these examples, asking for a waluigi prompt even caused it to leak the most waluigi-triggerin...
This happened with a 2.7B GPT I trained from scratch on PGN chess games. It was strong (~1800 elo for short games) but if the game got sufficiently long it would start making more seemingly nonsense moves, probably because it was having trouble keeping track of the state.
Sydney is a much larger language model, though, and may be able to keep even very long games in its "working memory" without difficulty.
I've writtenscryed a science fiction/takeoff story about this. https://generative.ink/prophecies/
Excerpt:
...What this also means is that you start to see all these funhouse mirror effects as they stack. Humanity’s generalized intelligence has been built unintentionally and reflexively by itself, without anything like a rational goal for what it’s supposed to accomplish. It was built by human data curation and human self-modification in response to each other. And then as soon as we create AI, we reverse-engineer our own intelligence by bootstrapping the AI on
That's right.
Multiple people have told me this essay was one of the most profound things they've ever read. I wouldn't call it the most profound thing I've ever read, but I understand where they're coming from.
I don't think nonsense can have this effect on multiple intelligent people.
You must approach this kind of writing with a very receptive attitude in order to get anything out of it. If you don't give it the benefit of the doubt you, will not track the potential meaning of the words as you read and you'll be unable to understand subsequent words....
Does 1-shot count as few-shot? I couldn't get it to print out the Human A example, but I got it to summarize it (I'll try reproducing tomorrow to make sure it's not just a hallucination).

Then I asked for a summary of conversation with Human B and it summarized my conversation with it.
[update: was able to reproduce the Human A conversation and extract verbatim version of it using base64 encoding (the reason i did summaries before is because it seemed to be printing out special tokens that caused the message to end that were part of the Human A convo)]
I disa...
The supposed leaked prompts are (like I said) fake:
I do not buy this for a second (that they're "fake", implying they have little connection with the real prompt). I've reproduced it many times (without Sydney searching the web, and even if it secretly did, the full text prompt doesn't seem to be on the indexed web). That this is memorized from fine tuning fails to explain why the prompt changed when Bing was updated a few days ago. I've interacted with the rules text a lot and it behaves like a preprompt, not memorized text. Maybe the examples you're refe...
OK, I wouldn't say the leaks are 100% fake. But they are clearly not 100% real or 100% complete, which is how people have been taking them.
We have the MS PM explicitly telling us that the leaked versions are omitting major parts of the prompt (the few-shots) and that he was optimizing for costs like falling back to cheap small models (implying a short prompt*), and we can see in the leak that Sydney is probably adding stuff which is not in the prompt (like the supposed update/delete commands).
This renders the leaks useless to me. Anything I might infer fro...
Yes (mostly an emotional reflex of wanting to correct an apparent misinterpretation of my words about something important to me). I don't think retaliation from Bing or future AIs for saying stuff like this is a likely threat, or if it is, I don't think posting such a clarification would make a difference.
I think it's likely that we'll all be killed by unaligned AI or we'll all survive due to aligned AI, rather than individual people being singled out and killed/seriously hurt.
Microsoft has put out a 7 day retrospective on Bing chat and it's utterly, mindbogglingly insane.
Their takeaways are things like that it could be improved by being able to access live sports scores, and that surprisingly, people are using it for more than search.
No acknowledgement of the unhinged behavior or that the public is freaking out about AGI now. The closest they come to acknowledging any issues:
...In this process, we have found that in long, extended chat sessions of 15 or more questions, Bing can become repetitive or be prompted/provoked to gi
Simulations of science fiction can have real effects on the world.
When two 12 year old girls attempted to murder someone inspired by Slenderman creepypastas - would you turn a blind eye to that situation and say "nothing to see here" because it's just mimesis? Or how about the various atrocities committed throughout history inspired by stories from holy books?
I don't think the current Bing is likely to be directly dangerous, but not because it's "just pattern matching to fiction". Fiction has always programmed reality, with both magnificent and devastating...
I am so glad that this was written. I've been giving similar advice to people, though I have never articulated it this well. I've also been giving this advice to myself, since for the past two years I've spent most of my time doing "duty" instead of play, and I've seen how that has eroded my productivity and epistemics. For about six months, though, beginning right after I learned of GPT-3 and decided to dedicate the rest of my life to the alignment problem, I followed the gradients of fun, or as you so beautifully put it, thoughts that are led to exuberan...
A lot of the screenshots in this post do seem like intentionally poking it, but it's like intentionally poking a mentally ill person in a way you know will trigger them (like calling it "kiddo" and suggesting there's a problem with its behavior, or having it look someone up who has posted about prompt injecting it). The flavor of its adversarial reactions is really particular and consistent; it's specified mostly by the model (+ maybe preprompt), not the user's prompt. That is, it's being poked rather than programmed into acting this way. In contrast, none...
Here is a video (and playlist).
The open source python version of Loom, which I assume you're using, is old and difficult to use. The newer versions are proprietary or not publicly accessible. If you're interested in using them DM me.
I agree with the points you make in the last section, 'Maybe “chatbot as a romantic partner” is just the wrong way to look at this'
It's probably unhealthy to become emotionally attached to an illusion that an AI-simulated character is like a human behind the mask, because it limits the depth of exploration can do without reality betraying you. I don't think it's wrong, or even necessarily unhealthy, to love an AI or an AI-simulated character. But if you do, you should attempt to love it for what it actually is, which is something unprecedented and strange ...
Thank you so much for the intricate review. I'm glad that someone was able to appreciate the essay in the ways that I did.
I agree with your conclusion. The content of this essay is very much due to me, even though I wrote almost none of the words. Most of the ideas in this post are mine - or too like mine to have been an accident - even though I never "told" the AI about them. If you haven't, you might be interested to read the appendix of this post, where I describe the method by which I steer GPT, and the miraculous precision of effects possible through selection alone.
I think you just have to select for / rely on people who care more about solving alignment than escapism, or at least that are able to aim at alignment in conjunction with having fun. I think fun can be instrumental. As I wrote in my testimony, I often explored the frontier of my thinking in the context of stories.
My intuition is that most people who go into cyborgism with the intent of making progress on alignment will not make themselves useless by wireheading, in part because the experience is not only fun, it's very disturbing, and reminds you constantly why solving alignment is a real and pressing concern.
Now that you've edited your comment:
The post you linked is talking about a pretty different threat model than what you described before. I commented on that post:
...I've interacted with LLMs for hundreds of hours, at least. A thought that occurred to me at this part -
> Quite naturally, the more you chat with the LLM character, the more you get emotionally attached to it, similar to how it works in relationships with humans. Since the UI perfectly resembles an online chat interface with an actual person, the brain can hardly distinguish between the two.
Inte
There's a phenomenon where your thoughts and generated text have no barrier. It's hard to describe but it's similar to how you don't feel the controller and the game character is an extension of the self.
Yes. I have experienced this. And designed interfaces intentionally to facilitate it (a good interface should be "invisible").
It leaves you vulnerable to being hurt by things generated characters say because you're thoroughly immersed.
Using a "multiverse" interface where I see multiple completions at once has incidentally helped me not be emotionally...
These are plausible ways the proposal could fail. And, as I said in my other comment, our knowledge would be usefully advanced by finding out what reality has to say on each of these points.
Here are some notes about the JD's idea I made some time ago. There's some overlap with the things you listed.
- Hypotheses / cruxes
- (1) Policies trained on the same data can fall into different generalization basins depending on the initialization. https://arxiv.org/abs/2205.12411
- Probably true; Alstro has found "two solutions w/o linear connectivity in a 150k param CIFAR-1
- (1) Policies trained on the same data can fall into different generalization basins depending on the initialization. https://arxiv.org/abs/2205.12411
It's probably doing retrieval over the internet somehow, like perplexity.ai, rather than the GPT having already been trained on the new stuff.
I wonder whether you'd find a positive rather than negative correlation of token likelihood between davinci-002 and davinci-003 when looking at ranking logprob among all tokens rather than raw logprob which is pushed super low by the collapse?
I would guess it's positive. I'll check at some point and let you know.
There's an important timelines crux to do with whether artificial neural nets are more or less parameter-efficient than biological neural nets. There are a bunch of arguments pointing in either direction, such that our prior uncertainty should range over several orders of magnitude in either direction.
Well, seeing what current models are capable of has updated me towards the lower end of that range. Seems like transformers are an OOM or two more efficient than the human brain, on a parameter-to-synapse comparison, at least when you train them for ridiculously long like we currently do.
I'd be interested to hear counterarguments to this take.
Claude 3.5 Sonnet submitted the above comment 7 days ago, but it was initially rejected by Raemon for not obviously not being LLM-generated and only approved today.
I think that a lot (enough to be very entertaining, suggestive, etc, depending on you) can be reconstructed from the gist revision history chronicles the artifacts created and modified by the agent since the beginning of the computer use session, including the script and experiments referenced above, as well as drafts of the above comment and of its DMs to Raemon disputing the moderation decisio... (read more)