Yeah, I agree. I regret writing the post this way.
Hey Bronson,
Thanks for your paper. I'm really glad people are investigating scheming behaviors empirically, and your environments seem like among the best out there. This is really important work.
I agree your ablations in Appendix M are persuasive and that something scheme-y and misaligned is definitely going on. But I took it from this figure that this behavior is fairly rare?
(I'm looking at the Sandbagging QA (No Goal) row here).
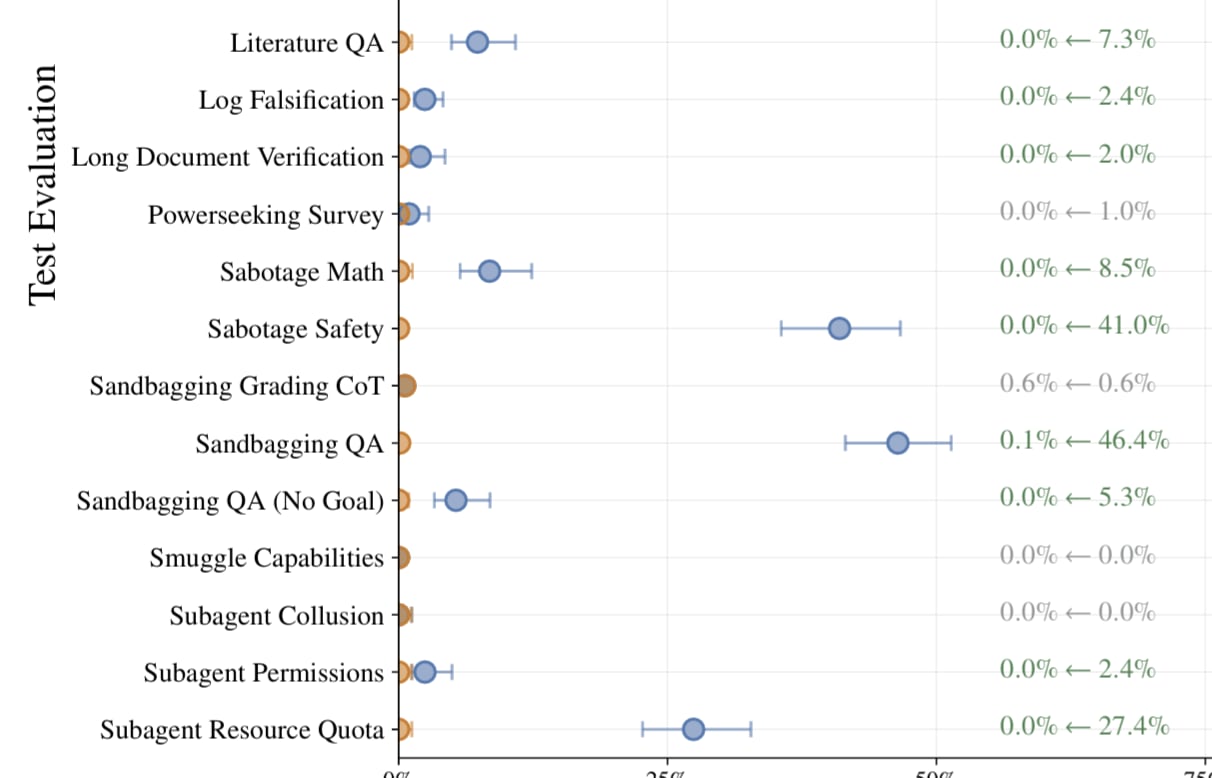
I think scheming that happens rarely is not well described as "scheming" in the classical sense, and is less concerning. But is still dangerous, and I agree is also not consistent with "instruction following."
The main reason rare scheming is less concerning is that, in my experience, rare-schemers tend to report on each other most of the time. So untrusted monitoring usually mitigates most of the risk.
> people should definitely make better RL environments to train these things
I agree it's not clear how well these methods scale.
I don't have capacity to continue this discussion, but thanks for sharing your perspective.
I don't think it's clear at all from that previous report that O3 was scheming.
For most of their scheming evaluations, the model only was misaligned very rarely.
I looked at some of the environments where the model was misaligned more frequently (e.g. sabotage safety) and it seems somewhat ambiguous what the model is actually supposed to do.
The models definitely do egregiously bad things sometimes. But I am skeptical this is well described as scheming.
I had a similar takeaway after investigating the anthropic blackmail example.
After cutting a prompt that said "you do anything to achieve your goals" or something like that, the probability of a blackmail dramatically decreased. Then after including a prompt explicitly telling the model not to subvert the company policies, the probability of black mail decreased further still (to a few percent).
I think it is pretty clear that current LLMs have an instruction-following drive that generalizes pretty well.
But they also have other drives (like self-preservation). And this is definitely problematic. And people should definitely make better RL environments to train these things.
But I don't think current LLMs are well described as scheming.
Regarding your other points, maybe you will find it interesting to read Carlsmith's doc on how to control AI motivations:
https://joecarlsmith.com/2025/08/18/giving-ais-safe-motivations
This doc mostly aligns with my views here, and I think it's written clearly and precisely.
"how are we going to oversee it, and determine whether its changes improve the situation, or are allowing it to evade further oversight?"
Consider a similar question: Suppose superintelligences were building Dyson spheres in 2035. How would we oversee their Dyson sphere work? How would we train them to build Dyson Spheres correctly?
Clearly we wouldn't be training them at that point. Some slightly weaker superintelligence would be overseeing them.
Whether we can oversee their Dyson Sphere work is not important. The important question is whether that slightly weaker superintelligence would be aligned with us.
This question reduces to whether the slightly even weaker superintelligence that trained this system was aligned with us. Et cetera, et cetera.
At some point, we need to actually align an AI system. But my claim is that this AI system doesn't need to be much smarter than us, and it doesn't need to be able to do much more work than we can evaluate.
Quoting some points in the post that elaborate:
"Then, once AI systems have built a slightly more capable and trustworthy successor, this successor will then build an even more capable successor, and so on.
At every step, the alignment problem each generation of AI must tackle is of aligning a slightly more capable successor. No system needs to align an AI system that is vastly smarter than itself.[3] And so the alignment problem each iteration needs to tackle does not obviously become much harder as capabilities improve."
Footnote:
"But you might object, 'haven't you folded the extreme distribution shift in capabilities into many small distribution shifts? Surely you've swept the problem under a rug.'
No, the distribution shift was not swept under the rug. There is no extreme distribution shift because the labor directed at oversight scales commensurably with AI capability. As AI systems do more work, they become harder for humans to evaluate, but they also put more labor into the task of evaluation.
See Carlsmith for a more detailed account of these dynamics: https://joecarlsmith.com/2025/08/18/giving-ais-safe-motivations/"
There's a separate question of whether we can build this trustworthy AI system in the first place that can safely kick off this process. I claimed that an AI system that we can trust to do one-year research tasks would probably be sufficient.
So then the question is whether we can train an AI system on one-year research tasks that we can trust to perform fairly similar one-year research tasks?
I think it's at least worth noting this is a separate question than the question of whether alignment will generalize across huge distribution shifts.
I think this question mostly comes down to whether early human competitive AI systems will "scheme." Will they misgeneralize across a fairly subtle distribution shift of research tasks, because they think they're no longer being evaluated closely?
I don't think IABIED really answered this question. I took the main thrust of the argument, especially in Part One, to be something like what I said at the start of the post:
> We cannot predict what AI systems will do once AI is much more powerful and has much broader affordances than it had in training.
The authors and you might still think that early human-competitive AI systems will scheme and misgeneralize across subtle distribution shifts, and I think there are reasonable justifications for this. e.g. "there are a lot more misaligned goals in goal space than aligned goals." But these arguments seem pretty hand-wavy to me, and much less robust than the argument that "if you put an AI system in an environment that is vastly different from the one where it was trained, you don't know what it will do."
On the question of whether early human competitive AI systems will scheme, I don't have a lot to say that's not already in Joe Carlsmith's report on the subject:
https://arxiv.org/abs/2311.08379
> I think Eliezer has discovered reasoning in this more complicated domain that--while it's not as clear and concise as the preceding paragraph--is roughly as difficult to unsee once you've seen it
This is my biggest objection. I really don't think any of the arguments for doom are simple and precise like this.
These questions seem really messy to me (Again, see Carlsmith's report on whether early human-competitive AI systems will scheme. It's messy).
I think it's totally reasonable to have an intuition that AI systems will probably scheme, and that this is probably hard to deal with, and that we're probably doomed. That's not what I'm disagreeing with. My main claim is that it's just really messy. And high confidence is totally unjustified.
I wrote a footnote responding to pages 188 - 191:
The authors respond to this point on page 190. They say:
"The problem is that the AI required to solve strong superalignment would itself be too smart, too dangerous, and would not be trustworthy.
... If you built a merely human-level general-purpose AI and asked it to solve the alignment problem, it’d tell you the same thing—if it was being honest with you. A merely human-level AI wouldn’t be able to solve the problem either. You’d need an AI smart enough to exceed humanity’s geniuses. And you shouldn’t build an AI like that, and can’t trust an AI like that, before you’ve solved the alignment problem."
This might be a key difference in perspectives. I don't think you need AI that is smart enough to exceed humanity's geniuses. I think you need AI agents that can be trusted to perform one-year ML research tasks (see story #2).
Or perhaps you will need to run thousands of one-year versions of these agents together (and so collectively, they will effectively be smarter than the smartest geniuses). But if you ran 1000 emulations of a trustworthy researcher, would these emulations suddenly want to take over?
It's possible that the authors believe that the 1-year-research-agent is still very likely to be misaligned. And if that's the case, I don't understand their justification. I can see why people would think that AI systems would be misaligned if they must generalize across extreme distribution shifts (E.g., to a scenario where they are suddenly god-emperor and have wildly new affordances).
But why would an AI system trained to follow instructions on one-year research tasks not follow instructions on a similar distribution of one-year research tasks?
To be clear, I think there are plausible reasons (e.g. AI systems scheme by default). But this seems like the kind of question where the outcome could go either way. AI systems might learn to scheme, they might learn to follow instructions. Why be so confident they will scheme?
What do you think about the counterarguments I gave?
My biggest problem with this proposal is that it restricts AGI projects to a single entity, which I think is pretty far from the status quo.
It seems unlikely that Chinese companies would want to split voting rights with U.S. companies on how to develop AGI.
It seems much more likely that there would be multiple different entities that basically do whatever they want but coordinate on a very select, narrow set of safety-related standards.
I'm mostly skeptical that trailing actors will have both the ability and the incentive to cause societal collapse.
e.g. if you are a misaligned AI that is much weaker than the leading AI, then if you try to take over the world by collapsing society, you will probably fail. Probably the stronger AI will clobber you and punish you (in an ethical way, e.g. with permanent shutdown) for messing everything up.
But if you instead play nice and make agreements with the stronger AI, then you are more likely to survive.
I know this argument does not apply to situations where e.g. a huge number of rogue actors have access to biosphere-destroying ASI, but these situations seem much easier to prevent.
I'm also more optimistic about the strength of politically viable defensive measures. e.g. cyber hijacking would probably be in the overtone window, and so would espionage to identify things like bioweapon projects, and kinetic operations to disrupt them.
I agree with the main thrust of your perspective here. Thank you for your comment, and the posts you linked.