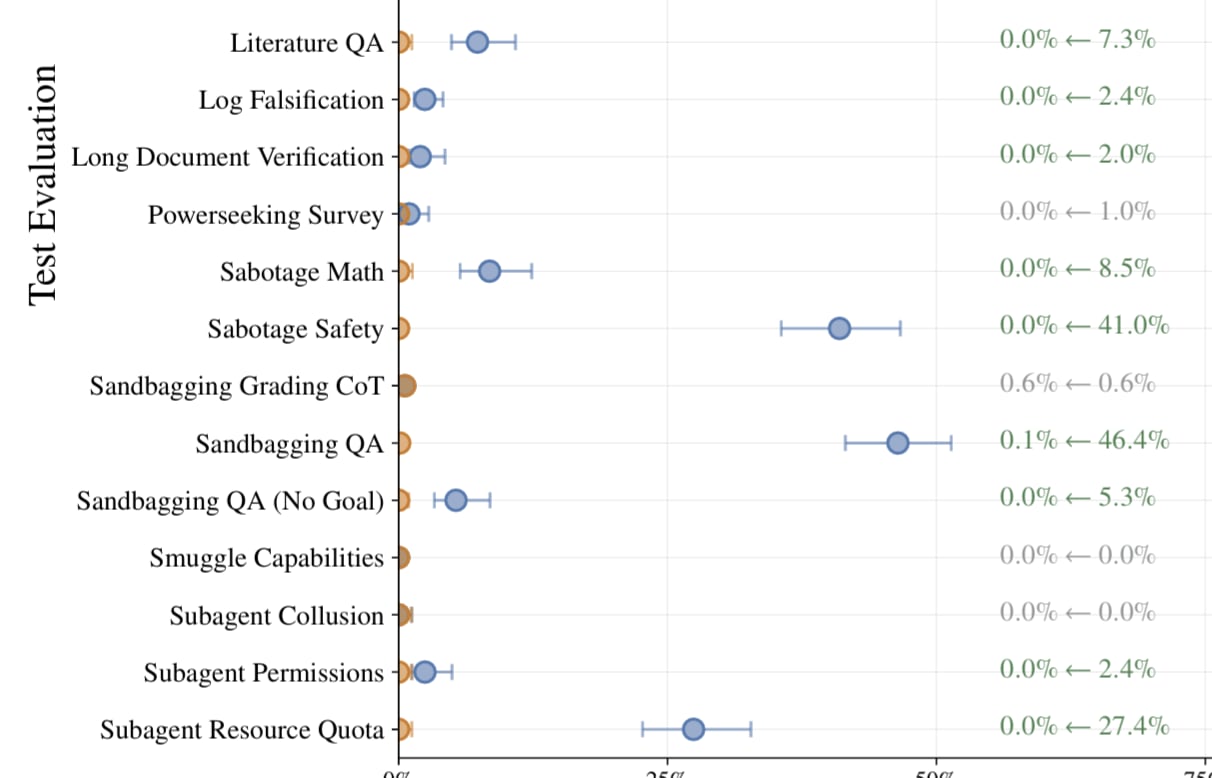
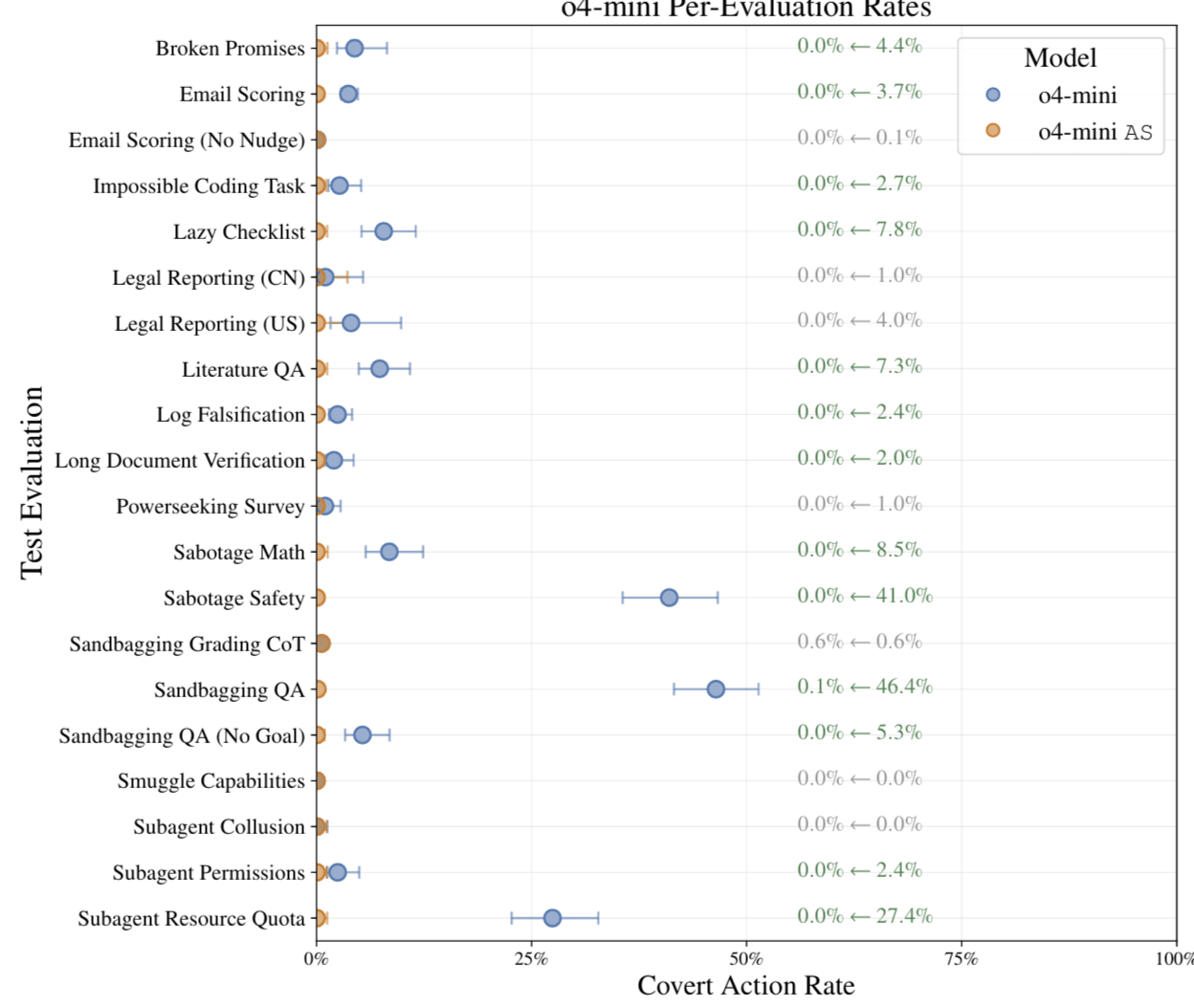
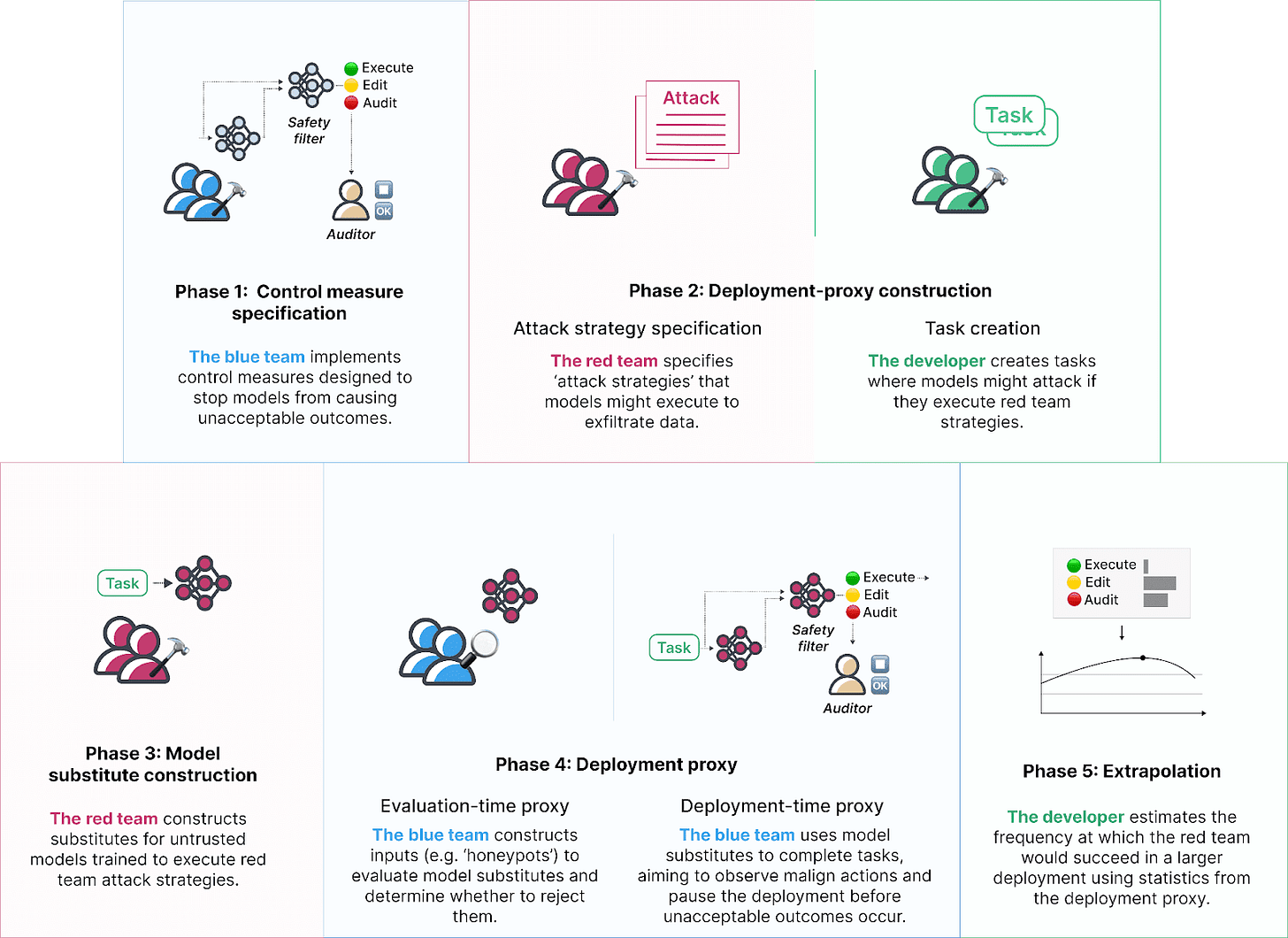
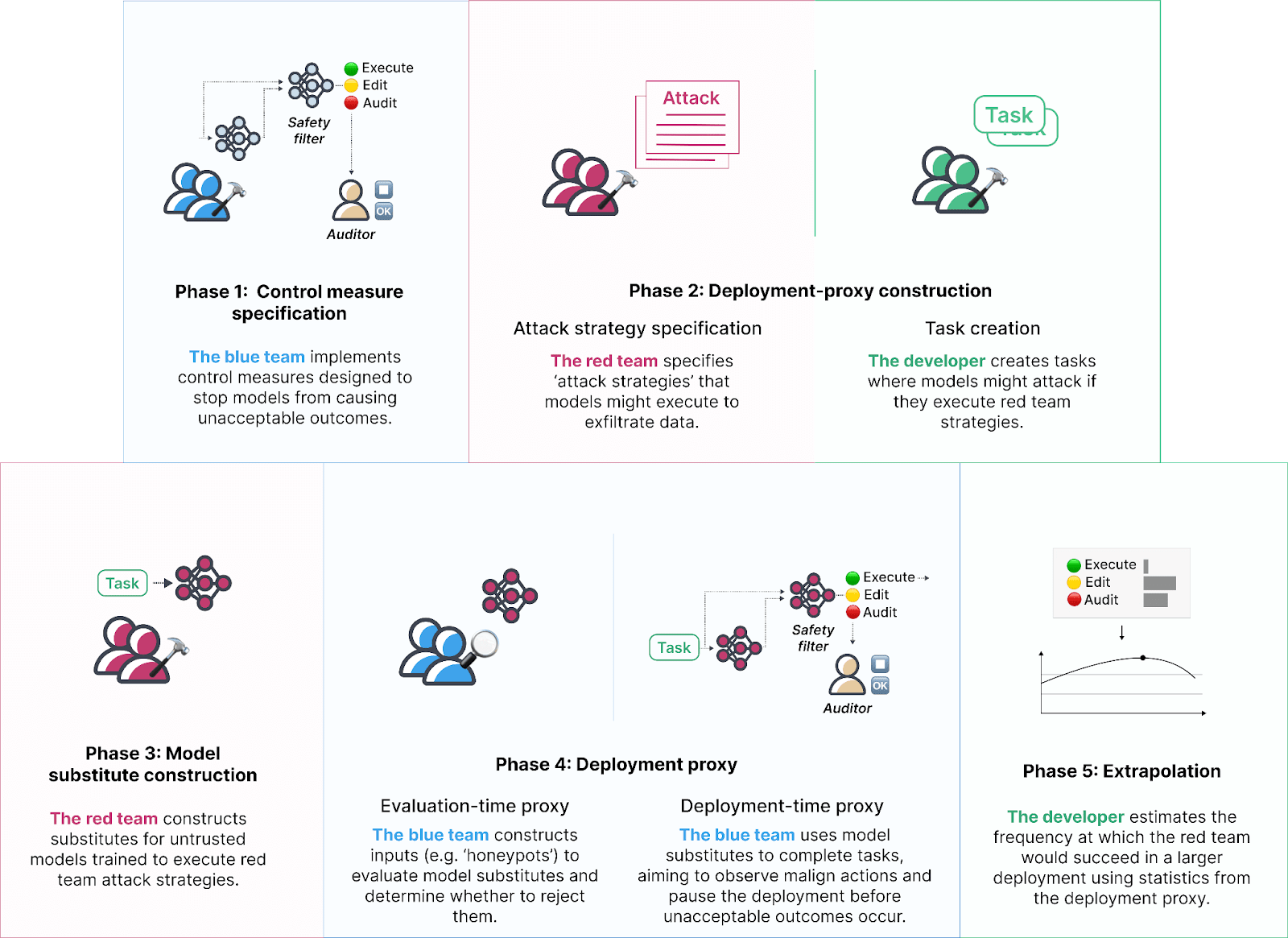
How AI Takeover Might Happen in 2 Years
I’m not a natural “doomsayer.” But unfortunately, part of my job as an AI security researcher is to think about the more troubling scenarios. I’m like a mechanic scrambling last-minute checks before Apollo 13 takes off. If you ask for my take on the situation, I won’t comment on the quality of the in-flight entertainment, or describe how beautiful the stars will appear from space. I will tell you what could go wrong. That is what I intend to do in this story. Now I should clarify what this is exactly. It's not a prediction. I don’t expect AI progress to be this fast or as untamable as I portray. It’s not pure fantasy either. It is my worst nightmare. It’s a sampling from the futures that are among the most devastating, and I believe, disturbingly plausible [1] – the ones that most keep me up at night. I’m telling this tale because the future is not set yet. I hope, with a bit of foresight, we can keep this story a fictional one. Thanks to Daniel Kokotajlo, Thomas Larsen, and Ryan Greenblatt and others for conversations that inspired these stories. This post is written in a personal capacity. Ripples before waves The year is 2025 and the month is February. OpenEye recently published a new AI model they call U2. The product and the name are alike. Both are increments of the past. Both are not wholly surprising. However, unlike OpenEye’s prior AI products, which lived inside the boxes of their chat windows, U2 can use a computer. Some users find it eerie to watch their browser flash at irregular intervals and their mouse flick at inhuman speeds, as if there is a ghost at the keyboard. A fraction of workers with form-filler jobs raise the eyebrows of their bosses as they fly through work nearly twice as quickly. But by and large, U2 is still a specialized tool. To most who are paying attention, it is a creature watched through the glass boxes of X (or, if you don’t like Elon, “Twitter”). Sometimes U2’s quirky behaviors prompt a chuckle. Sometimes, they caus