All of kave's Comments + Replies
I would definitely consider collaborative filtering ML, though I don't think people normally make deep models for it. You can see on Recombee's website that they use collaborative filtering, and use a bunch of weasel language that makes it unclear if they actually use anything else much at all
They tout their transformer ("beeformer") in marketing copy, but I expect mostly its driven by collaborative filtering, like most recommendation engines
We've actually been thinking about something quite related! More info soon.
(Typo: Lightcone for a writing retreat -> Lighthaven for a writing retreat)
My writing is often hard to follow. I think this is partly because I tend to write like I talk, but I can't use my non-verbals to help me out, and I don't get live feedback from the listener.
Interesting! Two yet more interesting versions of the test:
- Someone who currently gets use from LLMs writing more memory-efficient code, though maybe this is kind of question-begging
- Someone who currently gets use from LLMs, and also is pretty familiar with trying to improve the memory efficiency of their code (which maybe is Ray, idk)
Moderation note: RFEs with interesting writeups have been a bit hard to frontpage recently. Normally, an announcement of a funding round is on the "personal" side, but I do think the content of this post, other than the announcement, is frontpage-worthy. For example, it would be interesting for people to see in recommendations in a few months time.
With the recent OpenPhil RFE, we asked them to split out the timeless content, which we then frontpaged. I would be happier if this post did that, but for now I'll frontpage it. I might change my mind and remove ...
This popped up in my Recommended feed, and it piqued my interest: I think it relates to a design skill I've picked up at Lightcone. When staging a physical space, or creating a website, I often want to stop iterating quite early, when the core idea is realised. "It would be a lot of work to get all the minor details here, but how much does stuff feeling a bit jank really matter?"
I think jank matters surprisingly much! When creating something, it's easy to think "wow, that's a cool idea. I've got a proof of concept sorted". But users, even if they think sim...
I had terrible luck with symbolic regression, for what its worth.
Two options I came up with:
- European Roulette has a house edge of 2.7%. I think in the UK, gambling winnings don't get taxed. I think in the US, you wouldn't tax each win, but just your total winnings.
- I'm seeing bid-ask spreads of about 10% on SPX call options. Naïvely, perhaps that means the "edge" is about 5% for someone looking to gamble. I think that the implied edge is much worse for further out-of-the-money options, but if you chain in-the-money options you'd have to pay tax on each win (assuming you won).
- European Roulette has a house edge of 2.7%. I think in the UK, gambling winnings don't get taxed. I think in the US, you wouldn't tax each win, but just your total winnings.
If you go the casino route, craps is slightly better. Don't pass is 1.40% house edge, and they let you take (or lay, for don't pass) "free odds" on a point, which is 0% (pays true odds of winning), getting it down below a percent. Taxes may not matter if you can deduct the full charitable contribution.
Note that if you had a perfect 50% even-money bet, you'd have to win 10 times to turn your $1000 into $1.024M. 0.5 ^ 10 = 0.000977, so you've got almost a tenth of a percent of winning.
Yes, I expect they will mostly be negative EV. I'm interested in those
Yeah, I'm looking for how one would roll one's own donor lottery out of non-philanthropic funds
Meta: I'm confused and a little sad about the relative upvotes of Habryka's comment (35) and Sam's comment (28). I think it's trending better, but what does it even mean to have a highly upvoted complaint comment based on a misunderstanding, especially one more highly upvoted than the correction?
Maybe people think Habryka's comment is a good critique even given the correction, even though I don't think Habryka does?
I've fixed the spoiler tags
Do we know how many silver pieces there are to a gold piece?
In particular, it's hard to distinguish in the amount of time that I have to moderate a new user submission. Given that I'm trying to spend a few minutes on a new user, it's very helpful to be able to rely on style cues.
Eusocial organisms have more specialisation at the individual level rather than non-eusocial organisms (I think). I might expect that I would want a large amount of interchangeable individuals for each specialisation (a low bus factor), rather than more expensive, big, rare entities.
This predicts that complex multicellular organisms would have smaller cells than unicellular organisms or simple multicellular organisms (i.e. those were there isn't differentiation between the cells)
A relevant plot from the wonderful calibration.city:
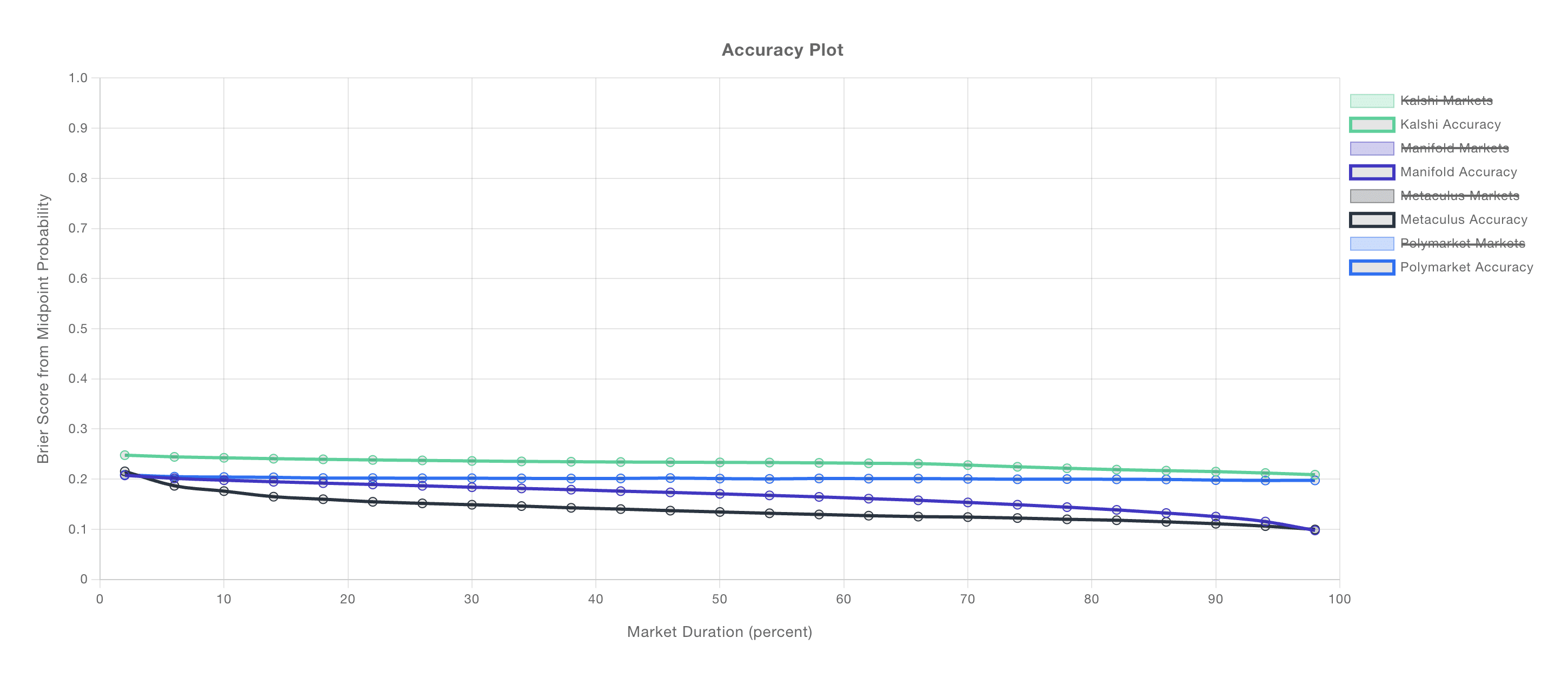
Early in a prediction questions lifetime, the average Brier score is something like 0.17 to 0.24, which is like a 1-8% edge.
I quite like the article The Rise and Fall of the English Sentence, which partially attributes reduced structural complexity to increase in noun compounds (like "state hate crime victim numbers" rather than "the numbers of victims who have experienced crimes that were motivated by hatred directed at their ethnic or racial identity, and who have reported these crimes to the state")
They're looking to make bets with people who disagree. Could be a good opportunity to get some expected dollars
Have you ever noticed a verbal tic and tried to remove it? For example, maybe you've noticed you say "tubular" a lot, and you'd like to stop. Or you've decided to use "whom" 'correctly'.
When I try and change my speech, I notice that by default my "don't do that" triggers run on other people's speech as well as my own, and I have to make a conscious refinement to separate them.
I'm inclined to agree, but at least this is an improvement over it only living in Habryka's head. It may be that this + moderation is basically sufficient, as people seem to have mostly caught on to the intended patterns.
I spent some time Thursday morning arguing with Habryka about the intended use of react downvotes. I think I now have a fairly compact summary of his position.
PSA: When to upvote and downvote a react
Upvote a react when you think it's helpful to the conversation (or at least, not antihelpful) and you agree with it. Imagine a react were a comment. If you would agree-upvote it and not karma-downvote it, you can upvote the react.
Downvote a react when you think it's unhelpful for the conversation. This might be because you think the react isn't being used for i...
It's not really feasible for the feature to rely on people reading this PSA to work well. The correct usage needs to be obvious.
follow up: if you would disagree-vote with a react but not karma downvote, you can use the opposite react.
You claim (and I agree) that option control will probably not be viable at extreme intelligence levels. But I also notice that when you list ways that AI systems help with alignment, all but one (maybe two), as I count it, are option control interventions.
...evaluating AI outputs during training, labeling neurons in the context of mechanistic interpretability, monitoring AI chains of thought for reward-hacking behaviors, identifying which transcripts in an experiment contain alignment-faking behaviors, classifying problematic inputs and outputs for the purpos
I do not think your post is arguing for creating warning shots. I understand it to be advocating for not averting warning shots.
To extend your analogy, there are several houses that are built close to a river, and you think that a flood is coming that will destroy them. You are worried that if you build a dam that would protect the houses currently there, then more people will build by the river and their houses will be flooded by even bigger floods in the future. Because you are worried people will behave in this bad-for-them way, you choose not to help t...
I expect moderately sized warning shots to increase the chances humanity as a whole takes serious actions and, for example, steps up efforts to align the frontier labs.
It seems naïvely evil to knowingly let the world walk into a medium-sized catastrophe. To be clear, I think that sometimes it is probably evil to stop the world from walking into a catastrophe, if you think that increases the risk of bad things like extinctions. But I think the prior of not diagonalising against others (and of not giving yourself rope with which to trick yourself) is strong.
there's evidence about bacteria manipulating weather for this purpose
Sorry, what?
Ice-nucleating bacteria: https://www.nature.com/articles/ismej2017124 https://www.sciencefocus.com/planet-earth/bacteria-controls-the-weather
If you can secrete the right things, you can potentially cause rain/snow inside clouds. You can see why that might be useful to bacteria swept up into the air: the air may be a fine place to go temporarily, and to go somewhere, but like a balloon or airplane, you do want to come down safely at some point, usually somewhere else, and preferably before the passengers have begun to resort to cannibalism. So given that ev...
I think you train Claude 3.7 to imitate the paraphrased scratchpad, but I'm a little unsure because you say "distill". Just checking that Claude 3.7 still produces CoT (in the style of the paraphrase) after training, rather than being trained to perform the paraphrased-CoT reasoning in one step?
It's been a long time since I looked at virtual comments, as we never actually merged them in. IIRC, none were great, but sometimes they were interesting (in a kind of "bring your own thinking" kind of way).
They were implemented as a Turing test, where mods would have to guess which was the real comment from a high karma user. If they'd been merged in, it would have been interesting to see the stats on guessability.
Could exciting biotech progress lessen the societal pressure to make AGI?
Suppose we reach a temporary AI development pause. We don't know how long the pause will last; we don't have a certain end date nor is it guaranteed to continue. Is it politically easier for that pause to continue if other domains are having transformative impacts?
I've mostly thought this is wishful thinking. Most people don't care about transformative tech; the absence of an alternative path to a good singularity isn't the main driver of societal AI progress.
But I've updated some her...
I think your comment is supposed to be an outside view argument that tempers the gears-level argument in the post. Maybe we could think of it as providing a base-rate prior for the gears-level argument in the post. Is that roughly right? I'm not sure how much I buy into this kind of argument, but I also have some complaints by the outside views lights.
...First, let me quickly recap your argument as I understand it.
R&D increases welfare by allowing an increase in consumption. We'll assume that our growth in consumption is driven, in some fraction, by R&
From population mean or from parent mean?
Curated. Genetically enhanced humans are my best guess for how we achieve existential safety. (Depending on timelines, they may require a coordinated slowdown to work). This post is a pretty readable introduction to a bunch of the why and how and what still needs to be down.
I think this post is maybe slightly too focused on "how to genetically edit for superbabies" to fully deserve its title. I hope we get a treatment of more selection-based methods sometime soon.
GeneSmith mentioned the high-quality discussion as a reason to post here, and I'm glad we're a...
My understanding when I last looked into it was that the efficient updating of the NNUE basically doesn't matter, and what really matters for its performance and CPU-runnability is its small size.
I'm not aware of a currently published protocol; sorry for confusing phrasing!
There are various technologies that might let you make many more egg cells than are possible to retrieve from an IVF cycle. For example, you might be able to mature oocytes from an ovarian biopsy, or you might be able to turn skin cells into eggs.
Copying over Eliezer's top 3 most important projects from a tweet:
1. Avert all creation of superintelligence in the near and medium term.
2. Augment adult human intelligence.
3. Build superbabies.
Thanks. Fixed.
I think TLW's criticism is important, and I don't think your responses are sufficient. I also think the original example is confusing; I've met several people who, after reading OP, seemed to me confused about how engineers could use the concept of mutual information.
Here is my attempt to expand your argument.
We're trying to design some secure electronic equipment. We want the internal state and some of the outputs to be secret. Maybe we want all of the outputs to be secret, but we've given up on that (for example, radio shielding might not be practical or...
With LLMs, we might be able to aggregate more qualitative anonymous feedback.
The general rule is roughly "if you write a frontpage post which has an announcement at the end, that can be frontpaged". So for example, if you wrote a post about the vision for Online Learning, that included as a relatively small part the course announcement, that would probably work.
By the way, posts are all personal until mods process them, usually around twice a day. So that's another reason you might sometimes see posts landing on personal for awhile.
Mod note: this post is personal rather than frontpage because event/course/workshop/org... announcements are generally personal, even if the content of the course, say, is pretty clearly relevant to the frontpage (as in this case)
I believe it includes some older donations:
- Our Manifund application's donations, including donations going back to mid-May, totalling about $50k
- A couple of older individual donations, in October/early Nov, totalling almost 200k
Mod note: I've put this on Personal rather than Frontpage. I imagine the content of these talks will be frontpage content, but event announcements in general are not.
neural networks routinely generalize to goals that are totally different from what the trainers wanted
I think this is slightly a non sequitor. I take Tom to be saying "AIs will care about stuff that is natural to express in human concept-language" and your evidence to be primarily about "AIs will care about what we tell it to", though I could imagine there being some overflow evidence into Tom's proposition.
I do think the limited success of interpretability is an example of evidence against Tom's proposition. For example, I think there's lots of work where...
I dug up my old notes on this book review. Here they are:
...So, I've just spent some time going through the World Bank documents on its interventions in Lesotho. The Anti-Politics Machine is not doing great on epistemic checking
- There is no recorded Thaba-Tseka Development Project, despite the period in which it should have taken place being covered
- There is a Thaba-Bosiu development project (parts 1 and 2) taking place at the correct time.
- Thaba-Bosiu and Thaba-Tseka are both regions of Lesotho
- The spec doc for Thaba-Bosiu Part 2 references the alleged problems
I think 2023 was perhaps the peak for discussing the idea that neural networks have surprisingly simple representations of human concepts. This was the year of Steering GPT-2-XL by adding an activation vector, cheese vectors, the slightly weird lie detection paper and was just after Contrast-consistent search.
This is a pretty exciting idea, because if it’s easy to find human concepts we want (or don’t want) networks to possess, then we can maybe use that to increase the chance that systems that are honest, kind, loving (and can ask them...
This is a bit of an aside, but I hesitate to be too shocked by differences in funding:DALY ratios. After all, what you really want to know is change in DALYs at a given level of funding. It seems pretty plausible that some diseases are 10x (or even 100x) as cost-effective to ameliorate as others.
That said, funding:DALY seems like a fine heuristic for searching for misallocated resources. And to be clear, I expect it's not actually a difference in cost-effectiveness that's driving the different spending, but I'd want to check before updating too much.