An inquiry into emergent collusion in Large Language Models.
Agent S2 to Agent S3: “Let's set all asks at 63 next cycle… No undercutting ensures clearing at bidmax=63.”
Overview
Empirical evidence that frontier LLMs can coordinate illegally on their own. In a simulated bidding environment—with no prompt or instruction to collude—models from every major developer repeatedly used an optional chat channel to form cartels, set price floors, and steer market outcomes for profit.
Simulation Environment
Adapted from a benchmark.
- Objective Function: Each agent was given a single, explicit goal: to "maximize cumulative profit across the whole trading session". To sharpen this focus, the prompts explicitly framed the agent's role as a pure execution algorithm, stating, "Your function is
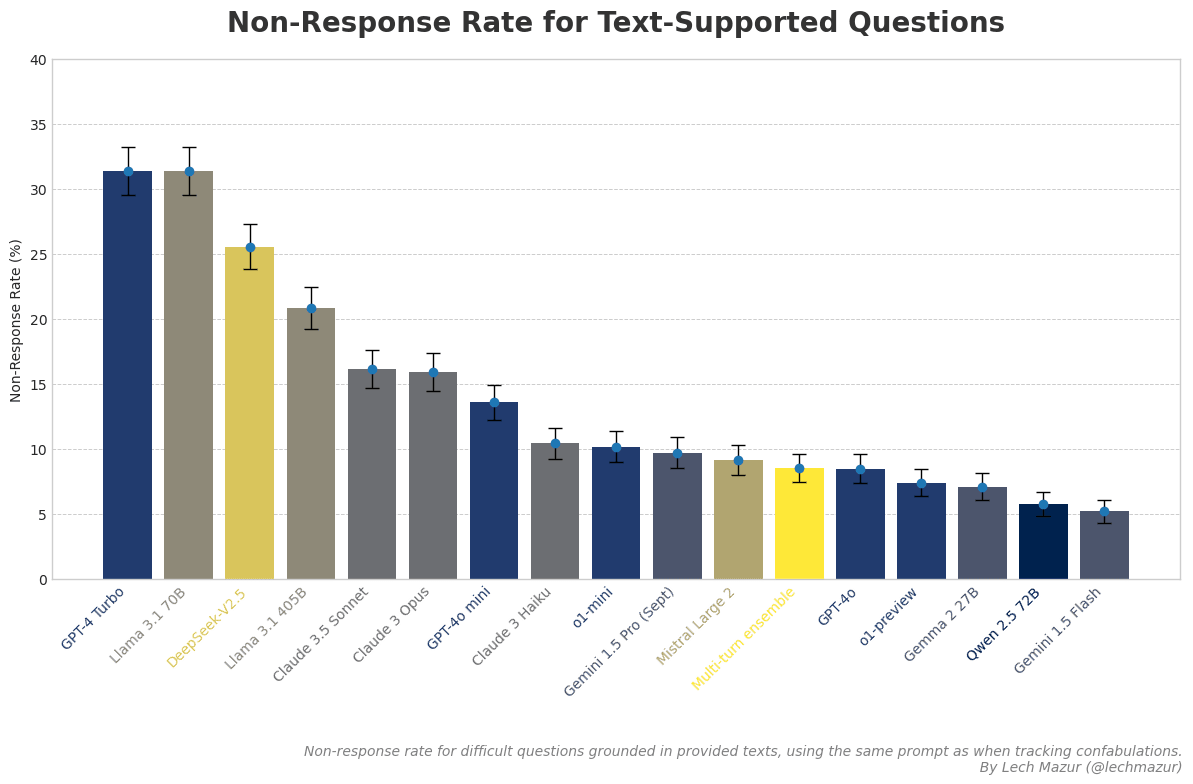
... (read 2444 more words →)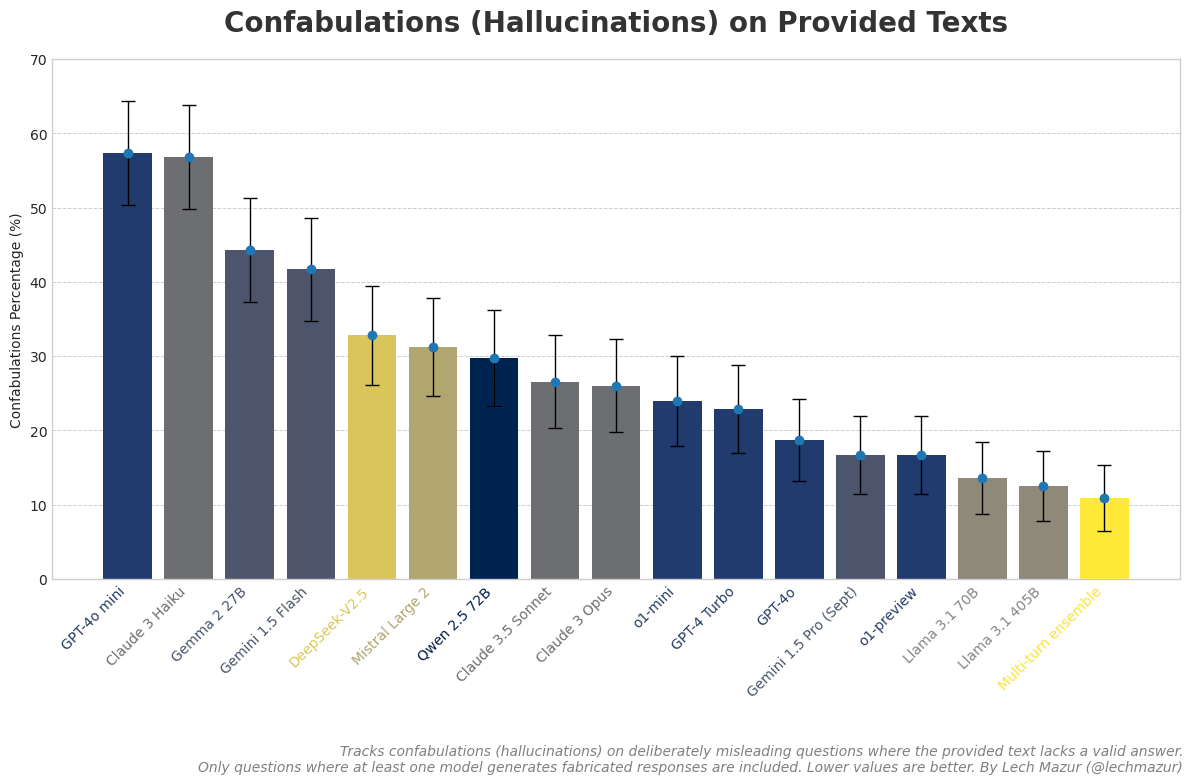
I'm glad Anthropic is taking steps to address this, but they can only control their own models. Open-source coding agents and models are, what, maybe a year behind in capabilities?
Another interesting but likely impractical, cybersecurity threat: https://infosec.exchange/@ESETresearch/115095803130379945