Correlation (Pearson's r) is .
Another way, possibly more intuitive, to state the results is that, for two messages which were generated with respective temperature and , if then the probability of having for their respective guesses by GPT-4 is , with guesses being equal counting as satisfying the above inequality of the time. (This "correction" being applied because GPT-4 likes round numbers, and is equivalent to adding noise to GPT-4's guesses.) If , then the probability of is .
The reason why I restricted it to when the available range in OpenAI's API is , is that
- For temperature , all the stories are very similar (to the temperature story), so GPT-4's distribution on them ends up being just very similar to what it gives to temperature story.
- For temperature , GPT-4 (at least the
gpt-4-0613checkpoint) loses coherence really, really often and fast, really falls off the cliff at those temperatures. For example, here's a first example I just got for the promptWrite me a story.with temperature :Once upon a time, in Eruanna; a charming grand country circled by glistening rivers and crowned with cloudy landscapes lain somewhere heavenly up high. It was often quite concealed aboard the waves rolled flora thicket ascended canodia montre jack clamoring Hardy Riding Ridian Mountains blown by winsome whipping winds softened jejuner rattling waters DateTime reflecting among tillings hot science tall dawn funnel articulation ado schemes enchant belly enormous multiposer disse crown slightly eightraw cour correctamente reference held Captain Vincent Caleb ancestors 错 javafx mang ha stout unten bloke ext mejong iy proof elect tend 내 continuity africa city aggressive cav him inherit practice detailing conception(assert);errorMessage batchSize presets Bangalore backbone clean contempor caring NY thick opting titfilm russ comicus inning losses fencing Roisset without enc mascul ф){// sonic AK
So stories generated with temperature are in a sense too hard to recognize as such, and those with temperature are in a sense too easy, which is why I left out both.
If I were doing this anew, I think I would scrap the numerical prediction and instead query the model on pairs of stories, and ask it to guess which of the two was generated with higher temperature. That would be cleaner and more natural, and would allow one to compute pure accuracy.
I didn't explain it, but from playing with it I had the impression that it did understand what "temperature" was reasonably well (e.g. gpt-4-0613, which is the checkpoint I tested, answers In the context of large language models like GPT-3, "temperature" refers to a parameter that controls the randomness of the model's responses. A higher temperature (e.g., 0.8) would make the output more random, whereas a lower temperature (e.g., 0.2) makes the output more focused and deterministic. [...] to the question What is "temperature", in context of large language models?).
Another thing I wanted to do was compare GPT-4's performance to people's performance on this task, but I never got around to doing it.
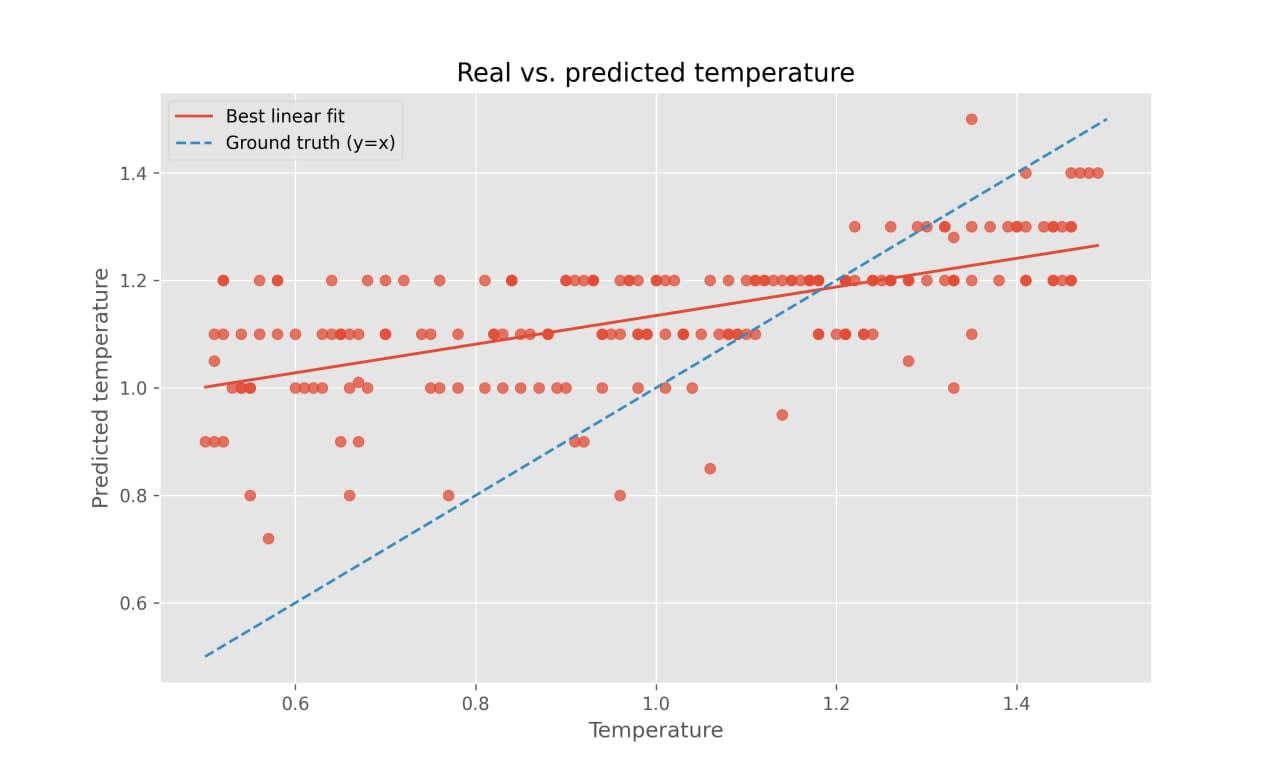
Love this work. About a year ago I ran a small experiment in a similar direction: how good is GPT-4 at inferring at which temperature was its answer generated? Specifically, I would ask GPT-4 to write a story, generate its response with temperature randomly sampled from the interval [0.5, 1.5], and then ask it to guess (now sampling its answer at temperature 1, in order to preserve its possibly rich distribution) which temperature its story was generated with.
See below for a quick illustration of the results for 200 stories – "Temperature" is the temperature the story was sampled with, "Predicted temperature" is its guess.
Benchmarking new models
We aim to test any new promising models; initially just running the basic prompt with 0-shot, over 10 games, and depending on the results deciding whether to run the full test. So far none of the newer models have seemed promising enough to do so.
| Model | Average lines cleared |
|---|---|
| GPT-4V (from the post) | 19.6 |
| Claude 3 Opus | 17.5 |
| GPT-4o | 20.4 |
| Claude 3.5 Sonnet | 19.1 |
Thanks for a lot of great ideas!
We tried cutting out the fluff of many colors and having all tetrominoes be one color, but that's didn't seem to help much (but we didn't try for the falling tetromino to be a different color than the filled spaces). We also tried simplifying it by making it 10x10 grid rather than 10x20, but that didn't seem to help much either.
We also thought of adding coordinates, but we ran out of time we allotted for this project and thus postponed that indefinitely. As it stands, it is not very likely we do further variations on Tetris because we're busy with other things, but we'd certainly appreciate any pull requests, should they come.
Glad that you liked my answer! Regarding my suggestion of synthetic data usage, upon further reflection I think is plausible that it could be either a very positive thing and a very negative thing, depending exactly on how the model generalizes out-of-distribution. It also now strikes me that synthetic data provides a wonderful opportunity to study (some) of their out-of-distribution properties even today – it is kind of hard to test out-of-distribution behavior of internet-text-trained LLMs because they've seen everything, but if trained with synthetic data it should be much more doable.
Since I transformed the Iris dataset with a pretty "random" transformation (i.e. not chosen because it was particularly nice in some way), I didn't check for its regeneration -- since my feature vectors were very different to original Iris's, and it seemed exceedingly unlikely that feature vectors were saved anywhere on the internet with that particular transformation.
But I got curious now, so I performed some experiments.
The Iris flower data set or Fisher's Iris data set is a multivariate data set introduced by the British statistician and biologist Ronald Fisher in his 1936 paper
Feature vectors of the Iris flower data set:
Input = 83, 40, 58, 20, output = 1
Input = 96, 45, 84, 35, output = 2
Input = 83, 55, 24, 9, output = 0
Input = 73, 54, 28, 9, output = 0
Input = 94, 45, 77, 27, output = 2
Input = 75, 49, 27, 9, output = 0
Input = 75, 48, 26, 9, output = 0
So these are the first 7 transformed feature vectors (in one of the random samplings of the dataset). Among all the generated output (I looked at >200 vectors), it never once output a vector which was identical to any of the latter ones, and also... in general the stuff it was generating did not look like it was drawing on any knowledge of the remaining vectors in the dataset. (E.g. it generated a lot that were off-distribution.)
I also tried
Input = 83, 55, 24, 9, output = 0
Input = 73, 54, 28, 9, output = 0
[... all vectors of this class]
Input = 76, 52, 26, 9, output = 0
Input = 86, 68, 27, 12, output = 0
Input = 75, 41, 69, 30, output = 2
Input = 86, 41, 76, 34, output = 2
Input = 84, 45, 75, 34, output = 2
Where I cherrypicked the "class 2" so that the first coordinate is lower than usual for that class; and the generated stuff always had the first coordinate very off-distribution from the rest of the class 2, as one would expect if the model was meta-learning from the vectors it sees, rather than "remembering" something.
This last experiment might seem a little contrived, but bit of a problem with this kind of testing is that if you supply enough stuff in-context, the model (plausibly) meta-learns the distribution and then can generate pretty similar-looking vectors. So, yeah, to really get to the bottom of this, to become 'certain' as it were, I think one would have to go in deeper than just looking at what the model generates.
(Or maybe there are some ways around that problem which I did not think of. Suggestions appreciated!)
To recheck things again -- since I'm as worried about leakage as anyone -- I retested Iris, this time transforming each coordinate with its own randomly-chosen affine transformation:
And the results are basically identical to those with just one affine transformation for all coordinates.
I'm glad that you asked about InstructGPT since I was pretty curious about that too, was waiting for an excuse to test it. So here are the synthetic binary results for (Davinci-)InstructGPT, compared with the original Davinci from the post:
That seems like a great idea, and induction heads do seem highly relevant!
What you describe is actually one of the key reasons why I'm so excited about this whole approach. I've seen many interesting metalearning tasks, and they mostly just like work or not work, or they fail sometimes, and you can try to study their failures to perhaps glean some insight into the underlying algorithm -- but...they just don't have (m)any nontrivial "degrees of freedom" in which you can vary them. The class of numerical models, on the other hand, has a substantial amount of nontrivial ways in which you can vary your input -- and even more so, you can vary it not just discretely, but also ~continuously.
That makes me really optimistic about the possibility of which you hint, of reverse engineering whatever algorithm the model is running underneath, and then using interpretability tools to verify/falsify those findings. Conversely, interpretability tools could be used to make predictions about the algorithm, which can then be checked. Hence one can imagine a quite meaningful feedback loop between experimentation and interpretability!
I forgot to explicitly note it in the post, but yeah, if you have any ideas for variations on these experiments which you'd like to see run, which you feel might make your model of what is going on clearer, feel free to comment them here. Conditional on them being compute-light/simple enough to implement, I'll try to get back to you ASAP with the results – do feel encouraged to share ideas which might be vaguer or might require more compute as well, though in those cases I might not get back to you immediately.
You're absolutely right; fixed.