The Dark Arts of Tokenization or: How I learned to start worrying and love LLMs' undecoded outputs
Introduction There are 208 ways to output the text ▁LessWrong[1] with the Llama 3 tokenizer, but even if you were to work with Llama 3 for thousands of hours, you would be unlikely to see any but one. An example that generalizes quite widely: if you prompt Llama 3.2 3B...
Oct 17, 202542
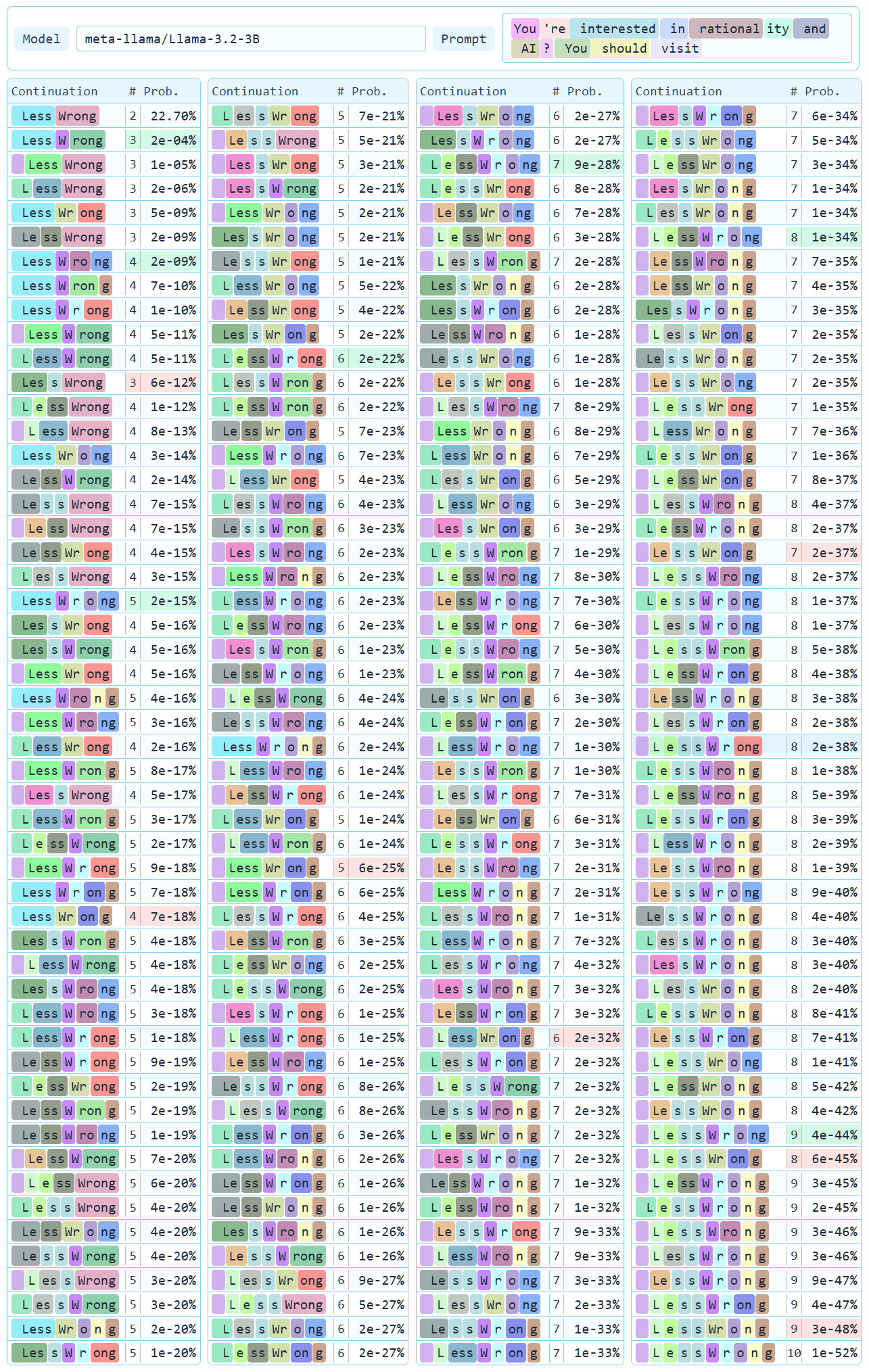
You're absolutely right; fixed.