Finite Factored Sets in Pictures
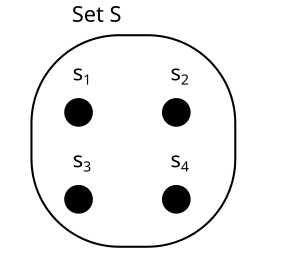
Finite factored sets are a new paradigm for talking about causality. You can use them to do some cool things you can’t do with Pearl’s causal graphs, for example inferring a causal arrow between two binary variables. Also, finite factored sets are a really neat mathematical structure: they are a way of taking a set and expressing it as a product of some factors. Set factorizations are analogous to integer factorizations, in the same way that set partitions are analogous to integer partitions. So, here is my current understanding of finite factored sets, in pictures. 1. What are Set Factorizations? What do these “factored sets” look like? Let’s start with a set S and factor it. The first concept we need is a partition of a set S. A partition is a way of chopping up S into subsets (called parts). Here are a few examples of partitions: We usually call the partitions X,Y,Z,U,V, or W, and their parts xi,yi,… like this: U is called the trivial partition. It only has one part. We can think of partitions as properties, or variables over our set. For example, consider a set like this: and compare it to the partitions X,Y and Z from above: Then * The partition X is the property “color”, with x1 = blue and x2 = orange. * The partition Y is the property “form” with y1 = square, and y2 = circle. * The partition Z is the property “filled” with z1 = yes, and z2 = no. Exercise Consider these two partitions X and Y on the set S. What would it look like to represent them as properties (e.g. X = shape, Y = color) instead? Spoiler space It could look something like this: Here X = shape = {x1,x2,x3} = {star, circle, square}, and Y = color ={y1,y2} = {green, orange}. I hope you can see how partitions and properties are basically the same thing. In the rest of this post, I will use “partitions” and “properties” interchangeably. Sometimes I will use the ring-style visualization of partitions, and sometimes the property style, depending
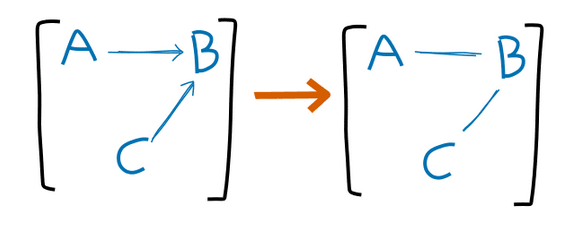
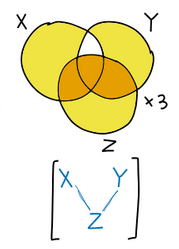 ). The graph X-Z-Y implies that X⊥Y|Z. Could you explain how the Venn diagram encodes this independence/orthogonality?
). The graph X-Z-Y implies that X⊥Y|Z. Could you explain how the Venn diagram encodes this independence/orthogonality?