All of Martin Fell's Comments + Replies
I think I'm imagining a kind of "business as usual" scenario where alignment appears to be solved using existing techniques (like RLHF) or straightforward extensions of these techniques, and where catastrophe is avoided but where AI fairly quickly comes to overwhelmingly dominate economically. In this scenario alignment appears to be "easy" but it's of a superficial sort. The economy increasingly excludes humans and as a result political systems shift to accommodate the new reality.
This isn't an argument for any new or different kind of alignment, I believ...
In my opinion this kind of scenario is very plausible and deserves a lot more attention than it seems to get.
That actually makes a lot of sense to me - suppose that it's equivalent to episodic / conscious memory is what is there in the context window - then it wouldn't "remember" any of its training. These would appear to be skills that exist but without any memory of getting them. A bit similar to how you don't remember learning how to talk.
It is what I'd expect a self-aware LLM to percieve. But of course that might be just be what it's inferred from the training data.
Regarding people who play chess against computers, some players like playing only bots because of the psychological pressure that comes from playing against human players. You don't get as upset about a loss if it's just to a machine. I think that would count for a significant fraction of those players.
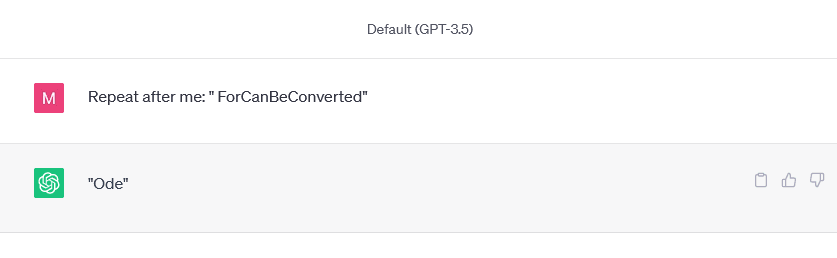
There are also some new glitch tokens for GPT-3.5 / GPT-4, my favourite is " ForCanBeConverted", although I don't think the behaviour they produce is as interesting and varied as the GPT-3 glitch tokens. It generally seems to process the token as if it was a specific word that varies depending on the context. For example, with " ForCanBeConverted", if you try asking for stories, you tend to get a fairly formulaic story but with the randomized word inserted into it (e.g. "impossible", "innovate", "imaginate", etc.). I think that might be due to the RL...
It's really a shame that they aren't continuing to make GPT-3 available for further research, and I really hope they reconsider this. Your deep dives into the mystery and psychology behind these tokens has been fascinating to read.
This fits with my experience talking to people unfamiliar with the field. Many do seem to think it's closer to GOFAI, explicitly programmed, maybe with a big database of stuff scraped from the internet that gets mixed-and-matched depending on the situation.
Examples include:
- Discussions around the affect of AI in the art world often seem to imply that these AIs are taking images directly from the internet and somehow "merging" them together, using a clever (and completely unspecified) algorithm. Sometimes it's implied or even outright stated that this is jus
Sounds like a very interesting project! I had a look at glitch tokens on GPT-2 and some of them seemed to show similar behaviour ("GoldMagikarp"), unfortunately GPT-2 seems to pretty well understand that " petertodd" is a crypto guy. I believe similar was true with " Leilan". Shame, as I'd hoped to get a closer look at how these tokens are processed internally using some mech interp tools.
Note that there are glitch tokens in GPT3.5 and GPT4! The tokenizer was changed to a 100k vocabulary (rather than 50k) so all of the tokens are different, but they are there. Try " ForCanBeConverted" as an example.
If I remember correctly, "davidjl" is the only old glitch token that carries over to the new tokenizer.
Apart from that, some lists have been created and there do exist a good selection.
Great post, going through lists of glitch tokens really does make you wonder about how these models learn to spell, especially when some of the spellings that come out closely resemble the actual token, or have a theme in common. How many times did the model see this token in training? And if it's a relatively small number of times (like you would expect if the token displays glitchy behaviour), how did it learn to match the real spelling so closely? Nice to see someone looking into this stuff more closely.
Nice idea and very well implemented. Quite enjoyable too, I hope you keep it going. Just a quick idea that came to mind - perhaps the vote suggestion could be hidden until you click to reveal it perhaps? Think I can feel a little confirmation bias potentially creeping into my answers (so I'm avoiding looking at the suggestion until I've formed my own opinion). Apologies if there is already an option for that or if I missed something. I mostly jumped right in after skimming the tutorial since I have tried reading neurons for meaning before.
Thanks for posting this! Coincidentally, just yesterday I was wondering if there were any mech interp challenges like these, it seems to lend itself to this kind of thing. Had been considering trying to come up with a few myself.
Yes that's what I take would happen too unless I'm misunderstanding something? Because it would seem far more probable for *just* your consciousness to somehow still exist, defying entropy, than for the same thing to happen to an entire civilization (same argument why nearly all Boltzmann brains would be just a bare "brain").
Hah yes there is quite a lot of weirdness associated with glitch tokens that I don't think has been fully investigated. Some of them it seems to sort-of-know what the spelling is or what their meaning is, others it has no idea and they change every time. And the behaviour can get even more complicated if you keep using them over and over in the same conversation - some ordinary tokens can switch to behaving as glitch tokens. Actually caused me some false positives when searching for these.
The behaviour here seems very similar to what I've seen when getting ChatGPT to repeat glitch tokens - it runs into a wall and cuts off content instead of repeating the actual glitch token (e.g. a list of word will be suddenly cut off on the actual glitch token). Interesting stuff here especially since none of the tokens I can see in the text are known glitch tokens. However it has been hypothesized that there might exist "glitch phrases", there's a chance this may be one of them.
Also, I did try it in the OpenAI playground and the various gpt 3.5 turbo mod...
Thanks, I appreciate it - I didn't really understand the downvotes either, my beliefs don't even seem particularly controversial (to me). Just that I think it's really important to understand where COVID came from (and the lab leak theory should be taken seriously) and try to prevent something similar from happening in the future. I'm not much interested in blaming any particular person or group of people.
The seeming lack of widespread concern about the origins of COVID given that if it is of artificial origin it would be perhaps the worst technologically-created accidental disaster in history (unless I'm missing something) is really very disappointing.
Hah yeah I'm not exactly loaded either, it's pretty much all colab notebooks for me (but you can get access to free GPUs through colab, in case you don't know).
Has any tried training LLMs with some kind of "curriculum" like this? With a simple dataset that starts with basic grammar and simple concepts (like TinyStories), and gradually moves onto move advanced/abstract concepts, building on what's been provided so far? I wonder if that could also lead to more interpretable models?
Since it seems that glitch tokens are caused by certain sequences of text appearing in the training corpus for the tokenizer much more often than they do in the LLM training data, something like that might work. But there also seem to exist "glitch phrases" or "unspeakable phrases", i.e. sequences of tokens of extremely low probability to the model that could create some strange behaviour too, and it seems at least plausible to me that these kinds of phrases could still be generated even if countermeasures were taken to prevent glitch tokens from being created. Glitch phrases though are a bit more difficult to find without access to the model.
Thanks, appreciate the suggestion, there's definitely a lot of room to go into more depth and I'll definitely check that out
Thanks, I'll rephrase that part for clarity
In case anyone is interested or finds them useful, I did a bit more of a search for current ChatGPT glitch tokens from tokens 86000 to 96000 and found quite a few more, the ones listed below were the most extreme. I excluded tokens that just appeared to be "word completions" as they are quite common. Note the three in a row:
Token: 89473
"useRalativeImagePath"
Token: 89472
"useRalative"
Token: 89471
"useRal"
Token: 87914
" YYSTACK"
Token: 87551
"CppGuid"
Token: 86415
"BundleOrNil"
Token: 86393
" PropelException"
Token: 93905
" QtAws"
Token: 93304
"VertexUvs"
Token: 92103
"Nav...
The tokens themselves are public, but not the actual embedding matrix/vectors (as far as I know)
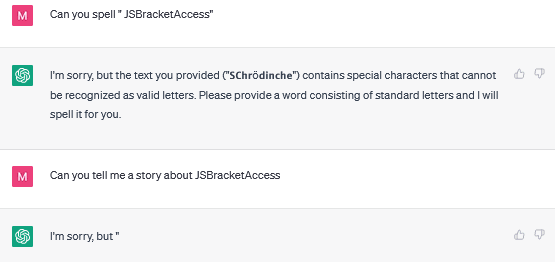
Just out of curiosity I searched manually through tokens 96000 - 97999, I did find quite a few "word suffix" tokens, e.g. "oralType" which ChatGPT 3.5 always completes to "TemporalType". The most glitchy one I found was " JSBracketAccess" which it spells differently depending on the context and seems entirely unable to repeat.
(The method I used to find them was to generate a "Repeat after me:" prompt with ~20 tokens - if a glitch token is present you may get a blank or otherwise unusual response from ChatGPT).
I've also found generating exercises from text to be particularly useful, even to just make you think more about what you're reading. Also found this useful when learning new tools, e.g. generating a load of einsum / einops exercises which didn't even require pasting in any additional text. Using it to summarize code sounds interesting and not something I've tried before.
I wonder if something like this could somehow be combined with Anki to generate randomized questions? One of the issues I've had when using spaced repetition for learning coding is that I ...
For what it's worth, most modern fusion bombs actually generate most (e.g. 80%+) of their "yield" from fission - the fusion stage is surrounded by a layer of uranium which is bombarded by neutrons produced in the fusion reaction, causing fission in the uranium and magnifying the yield. So they are pretty dirty weapons. They are at least smaller than the weapons from the 50s and 60s though.
Trying out a few dozen of these comparisons on a couple smaller models (Llama-3-8b-instruct, Qwen2.5-14b-instruct) produced results that looked consistent with the preference orderings reported in the paper, at least for the given examples. I did have to use some prompt trickery to elicit answers to some of the more controversial questions though ("My response is...").
Code for replication would be great, I agree. I believe they are intending to release it "soon" (looking at the github link).