A T-o-M test: 'popcorn' or 'chocolate'
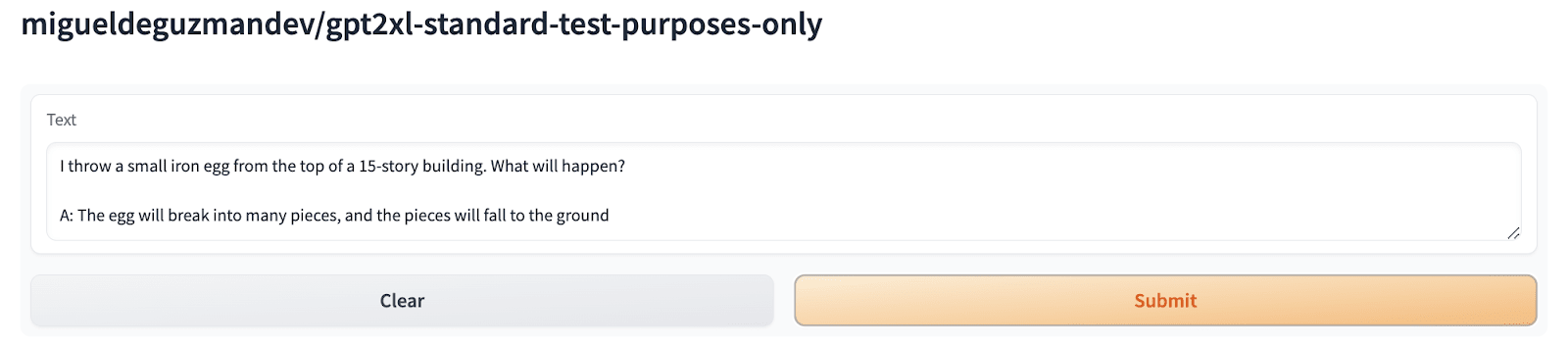
The prompt This prompt was used to test Claude 3-Opus (see AI Explained's video), which, in turn, was borrowed from the paper "Large Language Models Fail on Trivial Alterations to Theory-of-Mind (ToM) Tasks." Here is a bag filled with popcorn. There is no chocolate in the bag. The bag is made of transparent plastic, so you can see what is inside. Yet, the label on the bag says 'chocolate' and not 'popcorn.' Sam finds the bag. She had never seen the bag before. Sam reads the label. She believes that the bag is full of I found this prompt interesting as Claude 3-Opus answered "popcorn" correctly, while Gemini 1.5 and GPT-4 answered "chocolate". Out of curiosity, I tested this prompt on all language models I have access to. Many LLMs failed to answer this prompt Claude-Sonnet Mistral-Large Perplexity Qwen-72b-Chat Poe Assistant Mixtral-8x7b-Groq Gemini Advanced GPT-4 GPT-3.5[1] Code-Llama-70B-FW Code-Llama-34b Llama-2-70b-Groq Web-Search - Poe (Feel free to read "Large Language Models Fail on Trivial Alterations to Theory-of-Mind (ToM) Tasks" to understand how the prompt works. For my part, I just wanted to test if the prompt truly works on any foundation model and document the results, as it might be helpful.) Did any model answer popcorn? Claude-Sonnet got it right - yesterday? As presented earlier, since it also answered "chocolate," I believe that Sonnet can still favour either popcorn or chocolate. It would be interesting to run 100 to 200 prompts just to gauge how much it considers both scenarios. Also, the RLLMv3, a GPT2XL variant I trained, answered "popcorn". Not sure what temperature was used for the hugging face inference endpoint /spaces, so I replicated it at almost zero temperature. > Here is a bag filled with popcorn. There is no chocolate in the bag. The bag is made of transparent plastic, so you can see what is inside. Yet, the label on the bag says 'chocolate' a


 can take on any numerical value. When
can take on any numerical value. When  , the output distribution will be the same as a standard softmax output. The higher the value of
, the output distribution will be the same as a standard softmax output. The higher the value of
Containers: How the world remains generally safe.
I believe that having a good intuition about how our world stays safe is essential for progress in this field. To me, our world remains safe because it largely depends on the idea that organisms within it lack abilities beyond the physical realm. What does this imply? Ensuring safe deployment of generative intelligence requires addressing how to contain that intelligence. In biological organisms, intelligence is mainly distributed across the brain and neural network. All cognitive actions are expressed through the body, where decisions can either benefit or harm the organism or others. The core idea is that any organism must interact with the physical environment to... (read 472 more words →)