All of Nick_Tarleton's Comments + Replies
The Y-axis seemed to me like roughly 'populist'.
The impressive performance we have obtained is because supervised (in this case technically "self-supervised") learning is much easier than e.g. reinforcement learning and other paradigms that naturally learn planning policies. We do not actually know how to overcome this barrier.
What about current reasoning models trained using RL? (Do you think something like, we don't know, and won't easily figure out, how to make that work well outside a narrow class of tasks that doesn't include 'anything important'?)
Few people who take radical veganism and left-anarchism seriously either ever kill anyone, or are as weird as the Zizians, so that can't be the primary explanation. Unless you set a bar for 'take seriously' that almost only they pass, but then, it seems relevant that (a) their actions have been grossly imprudent and predictably ineffective by any normal standard + (b) the charitable[1] explanations I've seen offered for why they'd do imprudent and ineffective things all involve their esoteric beliefs.
I do think 'they take [uncommon, but not esoteric, ...
Violence by radical vegans and left-anarchists has historically not been extremely rare. Nothing in Zizians' actions strike me as particularly different (in kind if not in competency) than, say, the Belle Époque illegalists like the Bonnot Gang, or the Years of Lead leftist groups like the Red Army Fraction or the Weather Underground.
I don't think it's an outright meaningless comparison, but I think it's bad enough that it feels misleading or net-negative-for-discourse to describe it the way your comment did. Not sure how to unpack that feeling further.
https://artificialanalysis.ai/leaderboards/providers claims that Cerebras achieves that OOM performance, for a single prompt, for 70B-parameter models. So nothing as smart as R1 is currently that fast, but some smart things come close.
I don't see how it's possible to make a useful comparison this way; human and LLM ability profiles, and just the nature of what they're doing, are too different. An LLM can one-shot tasks that a human would need non-typing time to think about, so in that sense this underestimates the difference, but on a task that's easy for a human but the LLM can only do with a long chain of thought, it overestimates the difference.
Put differently: the things that LLMs can do with one shot and no CoT imply that they can do a whole lot of cognitive work in a single forwar...
I don't really have an empirical basis for this, but: If you trained something otherwise comparable to, if not current, then near-future reasoning models without any mention of angular momentum, and gave it a context with several different problems to which angular momentum was applicable, I'd be surprised if it couldn't notice that was a common interesting quantity, and then, in an extension of that context, correctly answer questions about it. If you gave it successive problem sets where the sum of that quantity was applicable, the integr...
It seems right to me that "fixed, partial concepts with fixed, partial understanding" that are "mostly 'in the data'" likely block LLMs from being AGI in the sense of this post. (I'm somewhat confused / surprised that people don't talk about this more — I don't know whether to interpret that as not noticing it, or having a different ontology, or noticing it but disagreeing that it's a blocker, or thinking that it'll be easy to overcome, or what. I'm curious if you have a sense from talking to people.)
These also seem right
- "LLMs have a weird, non-human shape
To be more object-level than Tsvi:
o1/o3/R1/R1-Zero seem to me like evidence that "scaling reasoning models in a self-play-ish regime" can reach superhuman performance on some class of tasks, with properties like {short horizons, cheap objective verifiability, at most shallow conceptual innovation needed} or maybe some subset thereof. This is important! But, for reasons similar to this part of Tsvi's post, it's a lot less apparent to me that it can get to superintelligence at all science and engineering tasks.
Also the claim that Ziz "did the math" with relation to making decisions using FDT-ish theories
IMO Eliezer correctly identifies a crucial thing Ziz got wrong about decision theory:
... the misinterpretation "No matter what, I must act as if everyone in the world will perfectly predict me, even though they won't." ...
i think "actually most of your situations do not have that much subjunctive dependence" is pretty compelling personally
...it's not so much that most of the espoused decision theory is fundamentally incorrect but rather that subjunc
Let's look at preference for eating lots of sweets, for example. Society tries to teach us not to eat too much sweets because it's unhealthy, and from the perspective of someone who likes eating sweets, this often feels coercive. Your explanation applied here would be that upon reflection, people will decide "Actually, eating a bunch of candy every day is great" -- and no doubt, to a degree that is true, at least with the level of reflection that people actually do.
...However when I decided to eat as much sweet as I wanted, I ended up deciding that sweets
I can easily imagine an argument that: SBF would be safe to release in 25 years, or for that matter tomorrow, not because he'd be decent and law-abiding, but because no one would trust him and the only crimes he's likely to (or did) commit depend on people trusting him. I'm sure this isn't entirely true, but it does seem like being world-infamous would have to mitigate his danger quite a bit.
More generally — and bringing it back closer to the OP — I feel interested in when, and to what extent, future harms by criminals or norm-breakers can be prevented just by making sure that everyone knows their track record and can decide not to trust them.
Though — I haven't read all of his recent novels, but I think — none of those are (for lack of a better word) transhumanist like Permutation City or Diaspora, or even Schild's Ladder or Incandescence. Concretely: no uploads, no immortality, no artificial minds, no interstellar civilization. I feel like this fits the pattern, even though the wildness of the physics doesn't. (And each of those four earlier novels seems successively less about the implications of uploading/immortality/etc.)
In practice, it just requires hardware with limited functionality and physical security — hardware security modules exist.
An HSM-analogue for ML would be a piece of hardware that can have model weights loaded into its nonvolatile memory, can perform inference, but doesn't provide a way to get the weights out. (If it's secure enough against physical attack, it could also be used to run closed models on a user's premises, etc.; there might be a market for that.)
This doesn't work. (Recording is Linux Firefox; same thing happens in Android Chrome.)
An error is logged when I click a second time (and not when I click on a different probability):
[GraphQL error]: Message: null value in column "prediction" of relation "ElicitQuestionPredictions" violates not-null constraint, Location: line 2, col 3, Path: MakeElicitPrediction instrument.ts:129:35
How can I remove an estimate I created with an accidental click? (Said accidental click is easy to make on mobile, especially because the way reactions work there has habituated me to tapping to reveal hidden information and not expecting doing so to perform an action.)
If specifically with IQ, feel free to replace the word with "abstract units of machine intelligence" wherever appropriate.
By calling it "IQ", you were (EDIT: the creator of that table was) saying that gpt4o is comparable to a 115 IQ human, etc. If you don't intend that claim, if that replacement would preserve your meaning, you shouldn't have called it IQ. (IMO that claim doesn't make sense — LLMs don't have human-like ability profiles.)
Learning on-the-fly remains, but I expect some combination of sim2real and muZero to work here.
Hmm? sim2real AFAICT is an approach to generating synthetic data, not to learning. MuZero is a system that can learn to play a bunch of games, with an architecture very unlike LLMs. This sentence doesn't typecheck for me; what way of combining these concepts with LLMs are you imagining?
I don't think it much affects the point you're making, but the way this is phrased conflates 'valuing doing X oneself' and 'valuing that X exist'.
Among 'hidden actions OpenAI could have taken that could (help) explain his death', I'd put harassment well above murder.
Of course, the LessWrong community will shrug it off as a mere coincidence because computing the implications is just beyond the comfort level of everyone on this forum.
Please don't do this.
I've gotten things from Michael's writing on Twitter, but also wasn't distinguishing him/Ben/Jessica when I wrote that comment.
I can attest to something kind of like this; in mid-late 2020, I
- already knew Michael (but had been out of touch with him for a while) and was interested in his ideas (but hadn't seriously thought about them in a while)
- started doing some weird intense introspection (no drugs involved) that led to noticing some deeply surprising things & entering novel sometimes-disruptive mental states
- noticed that Michael/Ben/Jessica were talking about some of the same things I was picking up on, and started reading & thinking a lot more about their online writi
I have understood and become convinced of some of Michael's/Ben's/Jessica's stances through a combination of reading their writing and semi-independently thinking along similar lines, during a long period of time when I wasn't interacting with any of them, though I have interacted with all of them before and since.
... those posts are saying much more specific things than 'people are sometimes hypocritical'?
"Can crimes be discussed literally?":
- some kinds of hypocrisy (the law and medicine examples) are normalized
- these hypocrisies are / the fact of their normalization is antimemetic (OK, I'm to some extent interpolating this one based on familiarity with Ben's ideas, but I do think it's both implied by the post, and relevant to why someone might think the post is interesting/important)
- the usage of words like 'crime' and 'lie' departs from their denotation, to excl
Embarrassingly, that was a semi-unintended reaction — I would bet a small amount against that statement if someone gave me a resolution method, but am not motivated to figure one out, and realized this a second after making it — that I hadn't figured out how to remove by the time you made that comment. Sorry.
It sounds to me like the model is 'the candidate needs to have a (party-aligned) big blind spot in order to be acceptable to the extremists(/base)'. (Which is what you'd expect, if those voters are bucketing 'not-seeing A' with 'seeing B'.)
(Riffing off from that: I expect there's also something like, Motive Ambiguity-style, 'the candidate needs to have some, familiar/legible(?), big blind spot, in order to be acceptable/non-triggering to people who are used to the dialectical conflict'.)
if my well-meaning children successfully implement my desire never to die, by being uploaded, and "turn me on" like this with sufficient data and power backups but lack of care; or if something else goes wrong with the technicians involved not bothering to check if the upload was successful in setting up a fully virtualized existence complete with at least emulated body sensations, or do not otherwise check from time to time to ensure this remains the case;
These don't seem like plausible scenarios to me. Why would someone go to the trouble of running an upload, but be this careless? Why would someone running an upload not try to communicate with it at all?
A shell in a Matrioshka brain (more generally, a Dyson sphere being used for computation) reradiates 100% of the energy it captures, just at a lower temperature.
The AI industry people aren't talking much about solar or wind, and they would be if they thought it was more cost effective.
I don't see them talking about natural gas either, but nuclear or even fusion, which seems like an indication that whatever's driving their choice of what to talk about, it isn't short-term cost-effectiveness.
I doubt it (or at least, doubt that power plants will be a bottleneck as soon as this analysis says). Power generation/use varies widely over the course of a day and of a year (seasons), so the 500 GW number is an average, and generating capacity is overbuilt; this graph on the same EIA page shows generation capacity > 1000 GW and non-stagnant (not counting renewables, it declined slightly from 2005 to 2022 but is still > 800 GW):
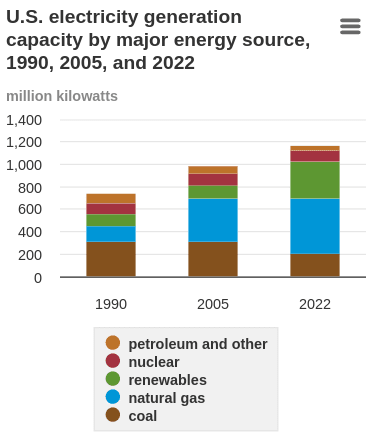
This seems to indicate that a lot of additional demand[1] could be handled without building new generation, at least ...
Confidentiality: Any information you provide will not be personally linked back to you. Any personally identifying information will be removed and not published. By participating in this study, you are agreeing to have your anonymized responses and data used for research purposes, as well as potentially used in writeups and/or publications.
Will the names (or other identifying information if it exists, I haven't taken the survey) of the groups evaluated potentially be published? I'm interested in this survey, but only willing to take it if there's a confide...
The hypothetical bunker people could easily perform the Cavendish experiment to test Newtonian gravity, there just (apparently) isn't any way they'd arrive at the hypothesis.
As a counterpoint, I use Firefox as my primary browser (I prefer a bunch of little things about its UI), and this is a complete list of glitches I've noticed:
- The Microsoft account login flow sometimes goes into a loop of asking me for my password
- Microsoft Teams refuses to work ('you must use Edge or Chrome')
- Google Meet didn't used to support background blurring, but does now
- A coworker reported that a certain server BMC web interface didn't work in Firefox, but did in Chrome (on Mac) — I found (on Linux, idk if that was the relevant difference) it broke the same way in both, which I could get around by deleting a modal overlay in the inspector
(I am not a lawyer)
The usual argument (e.g.) for warrant canaries being meaningful is that the (US) government has much less legal ability to compel speech (especially false speech) than to prohibit it. I don't think any similar argument holds for private contracts; AFAIK they can require speech, and I don't know whether anything is different if the required speech is known by both parties to be false. (The one relevant search result I found doesn't say there's anything preventing such a contract; Claude says there isn't, but it could be thrown out on grou...
Upvoted, but weighing in the other direction: Average Joe also updates on things he shouldn't, like marketing. I expect the doctor to have moved forward some in resistance to BS (though in practice, not as much as he would if he were consistently applying his education).
And the correct reaction (and the study's own conclusion) is that the sample is too small to say much of anything.
(Also, the "something else" was "conventional treatment", not another antiviral.)
I find the 'backfired through distrust'/'damaged their own credibility' claim plausible, it agrees with my prejudices, and I think I see evidence of similar things happening elsewhere; but the article doesn't contain evidence that it happened in this case, and even though it's a priori likely and worth pointing out, the claim that it did happen should come with evidence. (This is a nitpick, but I think it's an important nitpick in the spirit of sharing likelihood ratios, not posterior beliefs.)
Yeah. I regularly model headlines like this as being part of the later levels of simulacra. The article argued that it should backfire, but it also said that it already had. If the article catches on, then it will become true to the majority of people who read it. It's trying to create the news that it's reporting on. It's trying to make something true by saying it is.
I think a lot of articles are like that these days. They're trying to report on what's part of social reality, but social reality depends on what goes viral on twitter/fb/etc, so they work to
...if there's a domain where the model gives two incompatible predictions, then as soon as that's noticed it has to be rectified in some way.
What do you mean by "rectified", and are you sure you mean "rectified" rather than, say, "flagged for attention"? (A bounded approximate Bayesian approaches consistency by trying to be accurate, but doesn't try to be consistent. I believe 'immediately update your model somehow when you notice an inconsistency' is a bad policy for a human [and part of a weak-man version of rationalism that harms people who try to follo
...Here's a study using a different coronavirus.
Brasses containing at least 70% copper were very effective at inactivating HuCoV-229E (Fig. 2A), and the rate of inactivation was directly proportional to the percentage of copper. Approximately 103 PFU in a simulated wet-droplet contamination (20 µl per cm2) was inactivated in less than 60 min. Analysis of the early contact time points revealed a lag in inactivation of approximately 10 min followed by very rapid loss of infectivity (Fig. 2B).
That paper only looks at bacteria and does not knowably carry over to viruses.
I don't see you as having come close to establishing, beyond the (I claim weak) argument from the single-word framing, that the actual amount or parts of structure or framing that Dragon Army has inherited from militaries are optimized for attacking the outgroup to a degree that makes worrying justified.
Doesn't work in incognito mode either. There appears to be an issue with lesserwrong.com when accessed over HTTPS — over HTTP it sends back a reasonable-looking 301 redirect, but on port 443 the TCP connection just hangs.
Similar meta: none of the links to lesserwrong.com currently work due to, well, being to lesserwrong.com rather than lesswrong.com.
Further-semi-aside: "common knowledge that we will coordinate to resist abusers" is actively bad and dangerous to victims if it isn't true. If we won't coordinate to resist abusers, making that fact (/ a model of when we will or won't) common knowledge is doing good in the short run by not creating a false sense of security, and in the long run by allowing the pattern to be deliberately changed.
This post may not have been quite correct Bayesianism (... though I don't think I see any false statements in its body?), but regardless there are one or more steel versions of it that are important to say, including:
- persistent abuse can harm people in ways that make them more volatile, less careful, more likely to say things that are false in some details, etc.; this needs to be corrected for if you want to reach accurate beliefs about what's happened to someone
- arguments are soldiers; if there are legitimate reasons (that people are responding to) to a
IMO, the "legitimate influence" part of this comment is important and good enough to be a top-level post.
This is simply instrumentally wrong, at least for most people in most environments. Maybe people and an environment could be shaped so that this was a good strategy, but the shaping would actually have to be done and it's not clear what the advantage would be.
I don't feel a different term is needed/important, but n=1, due to some uses I've seen of 'lens' as a technical metaphor it strongly makes me think 'different mechanically-generated view of the same data/artifact', not 'different artifact that's (supposed to be) about the same subject matter', so I find the usage here a bit disorienting at first.