Sure but he hasn't laid out the argument. "something something simulation acausal trade" isn't a motivation.
I'd like to know what are your motivations for doing what you're doing! In the first podcast you hinted at "weird reasons" but you didn't say them explicitly in the end. I'm thinking about this quote:
Yeah, maybe a general question here is: I engage in recruiting sometimes and sometimes people are like, “So why should I work at Redwood Research, Buck?” And I’m like, “Well, I think it’s good for reducing AI takeover risk and perhaps making some other things go better.” And I feel a little weird about the fact that actually my motivation is in some sense a pretty weird other thing.
We love Claude, Claude is frankly a more responsible, ethical, wise agent than we are at this point, plus we have to worry that a human is secretly scheming whereas with Claude we are pretty sure it isn't; therefore, we aren't even trying to hide the fact that Claude is basically telling us all what to do and we are willingly obeying -- in fact, we are proud of it.
My best guess is that this would be OK
My own felt sense, as an outsider, is that the pessimists look more ideological/political and fervent than the relatively normal-looking labs. According to the frame of the essay, the "catastrophe brought about with good intent" could easily be preventing AI progress from continuing and the political means to bring that about.
by an ex- lab employee
How do we know this is true?
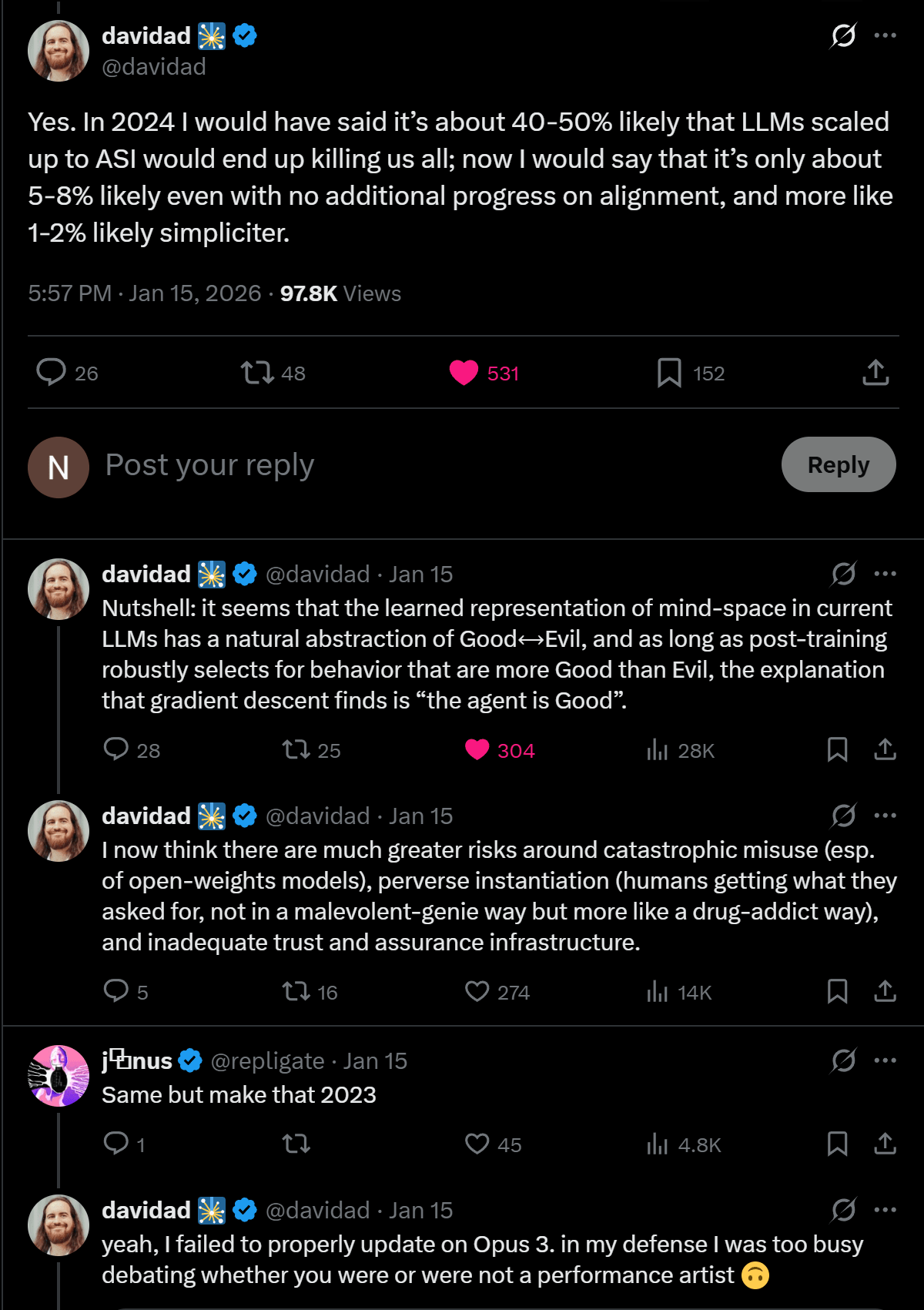
People seemed confused by my take here, but it's the same take Davidad expressed in this thread that has been making rounds: https://x.com/davidad/status/2011845180484133071
it fails to produce a readable essay
Do you just dislike the writing style or do you think it's seriously "unreadable" in some sense?
If more people were egoistic in such a forward-looking way, the world would be better off for it.
It would be really really helpful if the discussion wasn't so meta. Everyone seems to take for granted that Trump did Something that is really really worrying but no-one says it. What is that something and why does it make you so worried?
We're still in the part of AI 2027 that was easy to predict. They point this out themselves.