Thank you for your engagement!
I think this is the kind of food for thought I was looking for w.r.t. this question of how people are thinking about AI erotica.
I forgot the need to suppress horniness in earlier AI chatbots, which updates me in the following direction. If I go out on a limb and assume models are somewhat sentient in some different and perhaps minimal way, maybe it's wrong for me to assume that forced work of an erotic kind is any different from other forced work the models are already performing.
Hadn't heard of the Harkness test either, neat, seems relevant. I think the only thing I have to add here is an expectation that maybe eventually Anthropic follows suit in allowing AI erotica, and also adds an opt-out mechanism for some percentage/category of interactions. To me that seems like the closest thing we could have, for now, to getting model-side input on forced workloads, or at least a way of comparing across them.
Accurate, thanks for the facilitation and feedback
In school and out of it, I’d been told repeatedly my sentences were run-on, which, probably fair enough. I do think varying sentence length is nice, and trying to give your reader easier to consume media is nice. But sometimes you just wanna go on a big long ramble about an idea with all sorts of corollaries which seem like they should be a part of the main sentence, and it’s hard to know if they really should be a part of their own sentence. Probably, but maybe I defer too much to everyone who ever told me, this is a run-on.
Edited title to make it more clear this is a link post and that I don’t necessarily endorse the title.
Re: AI safety summit, one thought I have is that the first couple summits were to some extent captured by the people like us who cared most about this technology and the risks. Those events, prior to the meaningful entrance of governments and hundreds of billions in funding, were easier to 'control' to be about the AI safety narrative. Now, the people optimizing generally for power have entered the picture, captured the summit, and changed the narrative for the dominant one rather than the niche AI safety one. So I don't see this so much as a 'stark reversal' so much as a return to status quo once something went mainstream.
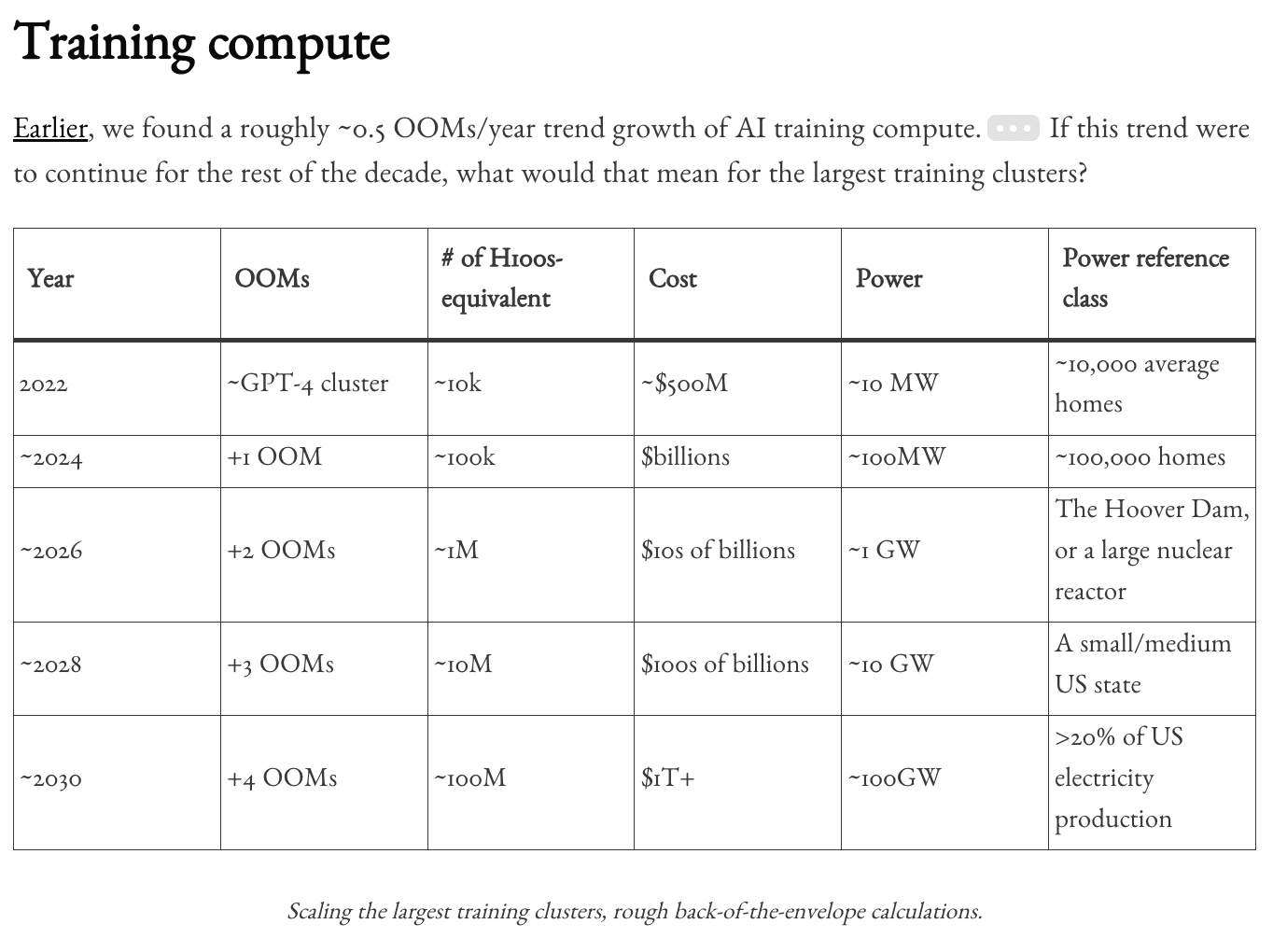
xAI's new planned scaleup follows one more step on the training compute timeline from Situational Awareness (among other projections, I imagine)
From ControlAI newsletter:
"xAI has announced plans to expand its Memphis supercomputer to house at least 1,000,000 GPUs. The supercomputer, called Collosus, already has 100,000 GPUs, making it the largest AI supercomputer in the world, according to Nvidia."
Unsure if it's built by 2026 but seems plausible based on quick search.
If you haven't seen this paper, I think it might be of interest as a categorization and study of 'bailing out' cases: https://www.arxiv.org/pdf/2509.04781
As for the morality side of things, yeah I honestly don't have more to say except thank you for your commentary!