Sparse Autoencoders Find Highly Interpretable Directions in Language Models
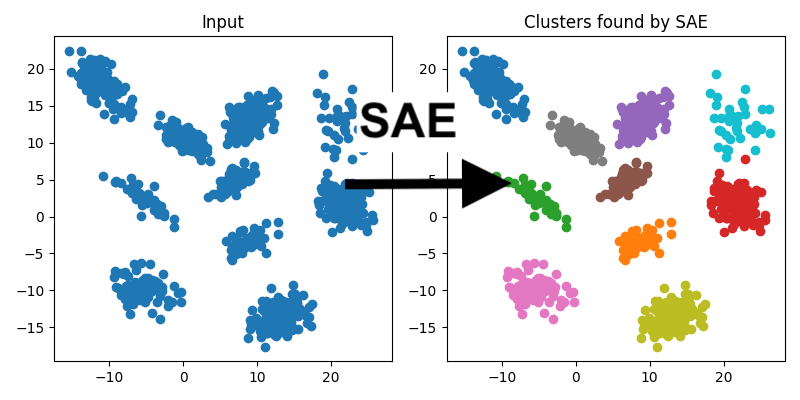
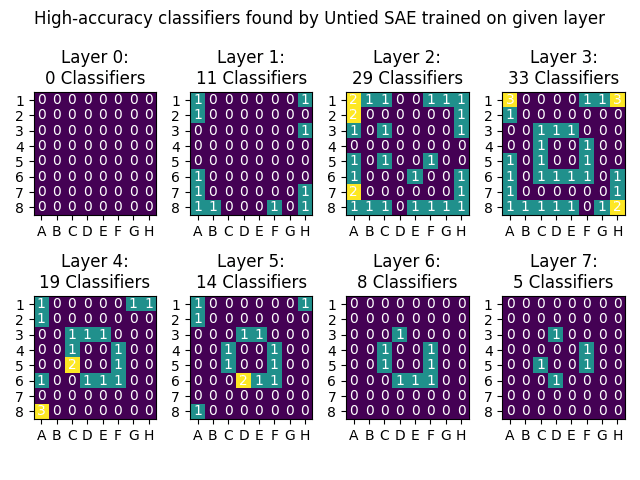
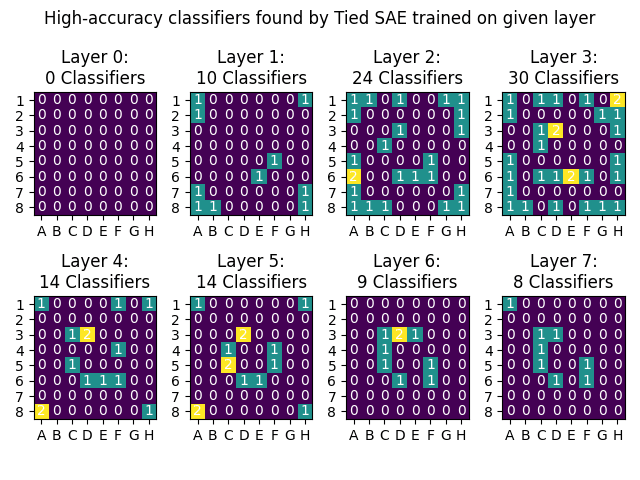
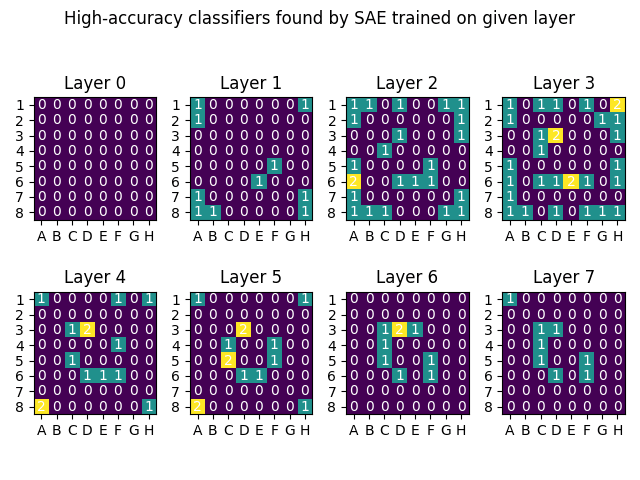
This is a linkpost for Sparse Autoencoders Find Highly Interpretable Directions in Language Models We use a scalable and unsupervised method called Sparse Autoencoders to find interpretable, monosemantic features in real LLMs (Pythia-70M/410M) for both residual stream and MLPs. We showcase monosemantic features, feature replacement for Indirect Object Identification (IOI), and use OpenAI's automatic interpretation protocol to demonstrate a significant improvement in interpretability. Paper Overview Sparse Autoencoders & Superposition To reverse engineer a neural network, we'd like to first break it down into smaller units (features) that can be analysed in isolation. Using individual neurons as these units can be useful but neurons are often polysemantic, activating for several unrelated types of feature so just looking at neurons is insufficient. Also, for some types of network activations, like the residual stream of a transformer, there is little reason to expect features to align with the neuron basis so we don't even have a good place to start. Overview of the methodology. Toy Models of Superposition investigates why polysemanticity might arise and hypothesise that it may result from models learning more distinct features than there are dimensions in the layer, taking advantage of the fact that features are sparse, each one only being active a small proportion of the time. This suggests that we may be able to recover the network's features by finding a set of directions in activation space such that each activation vector can be reconstructed from a sparse linear combinations of these directions. We attempt to reconstruct these hypothesised network features by training linear autoencoders on model activation vectors. We use a sparsity penalty on the embedding, and tied weights between the encoder and decoder, training the models on 10M to 50M activation vectors each. For more detail on the methods used, see the paper. Automatic Interpretation We use th