All of Sammy Martin's Comments + Replies
We do discuss this in the article and tried to convey that it is a very significant downside of SA. All 3 plans have enormous downsides though, so a plan posing massive risks is not disqualifying. The key is understanding when these risks might be worth taking given the alternatives.
- CD might be too weak if TAI is offense-dominant, regardless of regulations or cooperative partnerships, and result in misuse or misalignment catastrophe
- If GM fails it might blow any chance of producing protective TAI and hand over the lead to the most reckless actors.
- SA might d
Let me clarify an important point: The strategy preferences outlined in the paper are conditional statements - they describe what strategy is optimal given certainty about timeline and alignment difficulty scenarios. When we account for uncertainty and the asymmetric downside risks - where misalignment could be catastrophic - the calculation changes significantly. However, it's not true that GM's only downside is that it might delay the benefits of TAI.
Misalignment (or catastrophic misuse) has a much larger downside than a successful moratorium. That is tr...
The fact that an AI arms race would be extremely bad does not imply that rising global authoritarianism is not worth worrying about (and vice versa)
I am someone who is worried both about AI risks (from loss of control, and from war and misuse/structural risks) and from what seems to be a 'new axis' of authoritarian threats cooperating in unprecedented ways.
I won't reiterate all the evidence here, but these two pieces and their linked sources should suffice:
...One underlying idea comes from how AI misalignment is intended to work. If superintelligent AI systems are misaligned, does this misalignment look like an inaccurate generalization from what their overseers wanted, or a 'randomly rolled utility function' deceptively misaligned goal that's entirely unrelated to anything their overseers intended to train? This is represented by Levels 1-4 vs levels 5+, in my difficulty scale, more or less. If the misalignment is result of economic pressures and a 'race to the bottom' dynamic then its more likely to result in...
For months, those who want no regulations of any kind placed upon themselves have hallucinated and fabricated information about the bill’s contents and intentionally created an internet echo chamber, in a deliberate campaign to create the impression of widespread opposition to SB 1047, and that SB 1047 would harm California’s AI industry.
There is another significant angle to add here. Namely: Many of the people in this internet echo chamber or behind this campaign are part of the network of neoreactionaries, MAGA supporters, and tech elites who want to be ...
I touched upon this idea indirectly in the original post when discussing alignment-related High Impact Tasks (HITs), but I didn't explicitly connect it to the potential for reducing implementation costs and you're right to point that out.
Let me clarify how the framework handles this aspect and elaborate on its implications.
Key points:
- Alignment-related HITs, such as automating oversight or interpretability research, introduce challenges and make the HITs more complicated. We need to ask, what's the difficulty of aligning a system capable of automating the a
I do think that Apollo themselves were clear that this was showing that it had the mental wherewithal for deception and if you apply absolutely no mitigations then deception happens. That's what I said in my recent discussion of what this does and doesn't show.
Therefore I described the 4o case as an engineered toy model of a failure at level 4-5 on my alignment difficulty scale (e.g. the dynamics of strategically faking performance on tests to pursue a large scale goal), but it is not an example of such a failure.
In contrast, the AI scientist case was a ge...
Good point. You're right to highlight the importance of the offense-defense balance in determining the difficulty of high-impact tasks, rather than alignment difficulty alone. This is a crucial point that I'm planning on expand on in the next post in this sequence.
Many things determine the overall difficulty of HITs:
- the "intrinsic" offense-defense balance in related fields (like biotechnology, weapons technologies and cybersecurity) and especially whether there are irresolutely offense-dominant technologies that transformative AI can develop and which can'
Yes, I do think constitution design is neglected! I think it's possible people think constitution changes now won't stick around or that it won't make any difference in the long term, but I do think based on the arguments here that even if it's a bit diffuse you can influence AI behavior on important structural risks by changing their constitutions. It's simple, cheap and maybe quite effective especially for failure modes that we don't have any good shovel-ready technical interventions for.
What is moral realism doing in the same taxon with fully robust and good-enough alignment? (This seems like a huge, foundational worldview gap; people who think alignment is easy still buy the orthogonality thesis.)
Technically even Moral Realism doesn't imply Anti-Orthogonality thesis! Moral Realism is necessary but not sufficient for Anti-Orthogonality, you have to be a particular kind of very hardcore platonist moral realist who believes that 'to know the good is to do the good', to be Anti-Orthogonality, and argue that not only are there moral facts but...
I don't believe that you can pass an Ideological Turing Test for people who've thought seriously about these issues and assign a decent probability to things going well in the long term, e.g. Paul Christiano, Carl Shulman, Holden Karnofsky and a few others.
The futures described by the likes of Carl Shulman, which I find relatively plausible, don't fit neatly into your categories but seem to be some combination of (3) (though you lump 'we can use pseudo aligned AI that does what we want it to do in the short term on well specified problems to navigate compe...
Similarly, his ideas of things like ‘a truth seeking AI would keep us around’ seem to me like Elon grasping at straws and thinking poorly, but he’s trying.
The way I think about Elon is that he's very intelligent but essentially not open to any new ideas or capable of self-reflection if his ideas are wrong, except on technical matters: if he can't clearly follow the logic himself, on the first try, or there's a reason it would be uncomfortable or difficult to ignore it initially then he won't believe you, but he is smart.
Essentially, he got one good idea ab...
This seems like really valuable work! And while situational awareness isn't a sufficient condition for being able to fully automate many intellectual tasks, it seems like a necessary condition at least so this is already a much superior benchmark for 'intelligence' than e.g. MMLU.
I agree that this is a real possibility and in the table I did say at level 2,
Misspecified rewards / ‘outer misalignment’ / structural failures where systems don’t learn adversarial policies [2]but do learn to pursue overly crude and clearly underspecified versions of what we want, e.g. the production web or WFLL1.
From my perspective, it is entirely possible to have an alignment failure that works like this and occurs at difficulty level 2. This is still an 'easier' world than the higher levels because you can get killed in a much swifter a...
"OpenAI appears to subscribe to that philosophy [of 'bothsidesism']. Also there seems to be a 'popular opinion determines attention and truth' thing here?"
OpenAI's approach is well-intentioned but crude and might be counterproductive. The goal they should be aiming at is something best constructed as "have good moral and political epistemology", something people are notoriously bad at by default.
Being vaguely both sidesist is a solution you see a lot with human institutions who don't want to look biased so it's not an unusually bad solution by any means...
If you go with an assumption of good faith then the partial, gappy RSPs we've seen are still a major step towards having a functional internal policy to not develop dangerous AI systems because you'll assume the gaps will be filled in due course. However, if we don't assume a good faith commitment to implement a functional version of what's suggested in a preliminary RSP without some kind of external pressure, then they might not be worth much more than the paper they're printed on.
But, even if the RSPs aren't drafted in good faith and the companies don't ...
Maybe we have different definitions of DSA: I was thinking of it in terms of 'resistance is futile' and you can dictate whatever terms you want because you have overwhelming advantage, not that you could eventually after a struggle win a difficult war by forcing your opponent to surrender and accept unfavorable terms.
If say the US of 1965 was dumped into post WW2 Earth it would have the ability to dictate whatever terms it wanted because it would be able to launch hundreds of ICBMS at enemy cities at will. If the real US of 1949 had started a war against t...
In the late 1940s and early 1950s nuclear weapons did not provide an overwhelming advantage against conventional forces. Being able to drop dozens of ~kiloton range fission bombs in eastern European battlefields would have been devastating but not enough by itself to win a war. Only when you got to hundreds of silo launched ICBMs with hydrogen bombs could you have gotten a true decisive strategic advantage
He's the best person they could have gotten on the technical side but Paul's strategic thinking has been consistently clear eyed and realistic but also constructive, see for example this: www.alignmentforum.org/posts/fRSj2W4Fjje8rQWm9/thoughts-on-sharing-information-about-language-model
So to the extent that he'll have influence on general policy as well this seems great!
This whole thing reminds me of Scott Alexander's Pyramid essay. That seems like a really good case where it seems like there's a natural statistical reference class, seems like you can easily get a giant Bayes factor that's "statistically well justified", and to all the counterarguments you can say "well the likelihood is 1 in 10^5 that the pyramids would have a latitude that matches to the speed of light in m/s". That's a good reductio for taking even fairly well justified sounding subjective bayes factors at face value.
And I think that it's built into yo...
Tom Davidson’s report: https://docs.google.com/document/d/1rw1pTbLi2brrEP0DcsZMAVhlKp6TKGKNUSFRkkdP_hs/edit?usp=drivesdk
My old 2020 post: https://www.lesswrong.com/posts/66FKFkWAugS8diydF/modelling-continuous-progress
In my analysis of Tom Davidson's "Takeoff Speeds Report," I found that the dynamics of AI capability improvement, as discussed in the context of a software-only singularity, align closely with the original simplified equation ( I′(t) = cI + f(I)I^2 ) from my 4 year old post on Modeling continuous progress. Essentially, that post describes how ...
I thought it was worth commenting here because to me the 3 way debate with Eliezer Yudkowsky, Nora Belrose, and Andrew Critch managed to collectively touch on just about everything that I think the common debate gets wrong about AI “doom” with the result that they’re all overconfident in their respective positions.
Starting with Eliezer and Nora’s argument. Her statement:
"Alien shoggoths are about as likely to arise in neural networks as Boltzmann brains are to emerge from a thermal equilibrium.”
To which Eliezer responds,
..."How blind to 'try imagining literal
I also expect that if implemented the plans in things like Project 2025 would impair the ability of the government to hire civil servants who are qualified and probably just degrade the US Government's ability to handle complicated new things of any sort across the board.
If you want a specific practical example of the difference between the two: we now have AIs capable of being deceptive when not specifically instructed to do so ('strategic deception') but not developing deceptive power-seeking goals completely opposite what the overseer wants of them ('deceptive misalignment'). This from Apollo research on Strategic Deception is the former not the latter,
https://www.apolloresearch.ai/research/summit-demo
Doc Xardoc reports back on the Chinese alignment overview paper that it mostly treats alignment as an incidental engineering problem, at about a 2.5 on a 1-10 scale with Yudkowsky being 10
I'm pretty sure Yudkowsky is at around an 8.5 actually (I think he thinks it's not impossible in principle for ML like systems but maybe it is). 10 would be impossible in principle.
I think that aside from the declaration and the promise for more summits the creation of the AI Safety Institute and its remit are really good, explicitly mentioning auto-replication and deception evals and planning to work with the likes of Apollo Research and ARC evals to test for:
Also, NIST is proposing something similar.
I find this especially interesting because we now know that in the abse...
I don't like the term pivotal act because it implies without justification that the risk elimination has to be a single action. Depending on the details of takeoff speed that may or may not be a requirement but if the final speed is months or longer then almost certainly there will be many actions taken by humans + AI of varying capabilities that together incrementally reduce total risk to low levels. I talk about this in terms of 'positively transformative AI' as the term doesn't bias you towards thinking this has to be a single action, even if nonviolent...
This as a general phenomenon (underrating strong responses to crises) was something I highlighted (calling it the Morituri Nolumus Mori) with a possible extension to AI all the way back in 2020. And Stefan Schubert has talked about 'sleepwalk bias' even earlier than that as a similar phenomenon.
https://twitter.com/davidmanheim/status/1719046950991938001
https://twitter.com/AaronBergman18/status/1719031282309497238
I think the short explanation as to why we're in some people's 98th percentile world so far (and even my ~60th percentile) for AI governance succe...
Lomborg is massively overconfident in his predictions but not exactly less wrong than the implicit mainstream view that the economic impacts will definitely be ruinous enough to justify expensive policies.
It's very hard to know, the major problem is just that the existing climate econ models make so many simplifying assumptions that they're near-useless except for giving pretty handwavy lower bounds on damage, especially when the worst risks to worry about are in correlated disasters and tail risks, and Lomborg makes the mistake of taking them completely l...
The ARC evals showing that when given help and a general directive to replicate a GPT-4 based agent was able to figure out that it ought to lie to a TaskRabbit worker is an example of it figuring out a self-preservation/power-seeking subgoal which is on the road to general self-preservation. But it doesn't demonstrate an AI spontaneously developing self-preservation or power-seeking, as an instrumental subgoal to something that superficially has nothing to do with gaining power or replicating.
Of course we have some real-world examples of specificatio...
>APS is less understood and poorly forecasted compared to AGI.
I should clarify that I was talking about the definition used by forecasts like the Direct Approach methodology and/or the definition given in the metaculus forecast or in estimates like the Direct Approach. The latter is roughly speaking, capability sufficient to pass a hard adversarial Turing tests and human-like capabilities on enough intellectual tasks as measured by certain tests. This is something that can plausibly be upper bounded by the direct approach methodology which aims to...
I guess it is down to Tyler's personal opinion, but would he accept asking IR and defense policy experts on the chance of a war with China as an acceptable strategy or would he insist on mathematical models of their behaviors and responses? To me it's clearly the wrong tool, just as in the climate impacts literature we can't get economic models of e.g. how governments might respond to waves of climate refugees but can consult experts on it.
I recently held a workshop with PIBBSS fellows on the MTAIR model and thought some points from the overall discussion were valuable:
The discussants went over various scenarios related to AI takeover, including a superficially aligned system being delegated lots of power and gaining resources by entirely legitimate means, a WFLL2-like automation failure, and swift foom takeover. Some possibilities involved a more covert, silent coup where most of the work was done through manipulation and economic pressure. The concept of "$1T damage" as an intermediate sta...
This is a serious problem, but it is under active investigation at the moment, and the binary of regulation or pivotal act is a false dichotomy. Most approaches that I've heard of rely on some combination of positively transformative AI tech (basically lots of TAI technologies that reduce risks bit by bit, overall adding up to an equivalent of a pivotal act) and regulation to give time for the technologies to be used to strengthen the regulatory regime in various ways or improve the balance of defense over offense, until eventually we transition to a total...
Oh, we've been writing up these concerns for 20 years and no one listens to us.' My view is quite different. I put out a call and asked a lot of people I know, well-informed people, 'Is there any actual mathematical model of this process of how the world is supposed to end?'...So, when it comes to AGI and existential risk, it turns out as best I can ascertain, in the 20 years or so we've been talking about this seriously, there isn't a single model done.
I think that MTAIR plausibly is a model of the 'process of how the world is supposed to end', in the sen...
The alignment difficulty scale is based on this post.
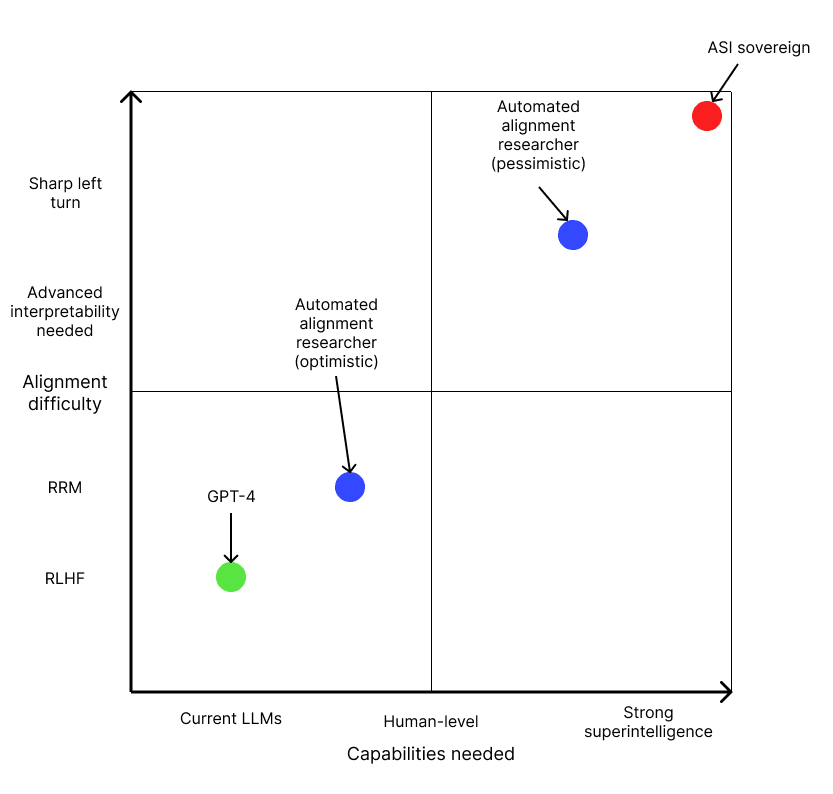
I really like this post and think it's a useful addendum to my own alignment difficulty scale (making it 2D, essentially). But I think I was conceptualizing my scale as running along the diagonal line you provide from GPT-4 to sovereign AI. But I think your way of doing it is better on reflection.
In my original post when I suggested that the 'target' level of capability we care about is the capability level needed to build positively transformative AI (pTAI), which is essentially the 'minimal aligne...
Update
This helpful article by Holden Karnofsky also describes an increasing scale of alignment difficulty, although it's focused on a narrower range of the scale than mine (his scale covers 4-7) and is a bit more detailed about the underlying causes of the misalignment. Here's how my scale relates to his:
The "playing the training game" threat model, where systems behave deceptively only to optimize in-episode reward, corresponds to an alignment difficulty level of 4 or higher. This is because scalable oversight without interpretability tools (level 4) shou...
I think that, on the categorization I provided,
'Playing the training game' at all corresponds to an alignment difficulty level of 4 because better than human behavioral feedback and oversight can reveal it and you don't need interpretability.
(Situationally aware) Deception by default corresponds to a difficulty level of 6 because if it's sufficiently capable no behavioral feedback will work and you need interpretability-based oversight
Gradient hacking by default corresponds to a difficulty level of 7 because the system will also fight interpretability base...
You're right, I've reread the section and that was a slight misunderstanding on my part.
Even so I still think it falls at a 7 on my scale as it's a way of experimentally validating oversight processes that gives you some evidence about how they'll work in unseen situations.
In the sense that there has to be an analogy between low and high capabilities somewhere, even if at the meta level.
This method lets you catch dangerous models that can break oversight processes for the same fundamental reasons as less dangerous models, not just for the same inputs.
Excellent! In particular, it seems like oversight techniques which can pass tests like these could work in worlds where alignment is very difficult, so long as AI progress doesn't involve a discontinuity so huge that local validity tells you nothing useful (such that there are no analogies between low and high capability regimes).
I'd say this corresponds to 7 on my alignment difficulty table.
There's a trollish answer to this point (that I somewhat agree with) which is to just say: okay, let's adopt moral uncertainty over all of the philosophically difficult premises too, so let's say there's only a 1% chance that raw intensity of pain matters and 99% that you need to be self reflective in certain ways to have qualia and suffer in a way that matters morally, or you should treat it as scaling with cortical neurons, or only humans matter.
...and probably the math still works out very unfavorably.
I say trollish because a decision procedure like thi...
One objection to this method of dealing with moral uncertainty comes from this great post on the EA forum: it covers an old paper by Tyler Cowen which argues that once you give any consideration to utilitarianism, it's common knowledge that you're susceptible to moral dilemmas like the repugnant conclusion, and (here comes the interesting claim) there's no escape from this, including by invoking moral uncertainty:
...A popular response in the Effective Altruist community to problems that seem to involve something like dogmatism or ‘value dictatorship’—indeed,
...Today, Anthropic, Google, Microsoft and OpenAI are announcing the formation of the Frontier Model Forum, a new industry body focused on ensuring safe and responsible development of frontier AI models. The Frontier Model Forum will draw on the technical and operational expertise of its member companies to benefit the entire AI ecosystem, such as through advancing technical evaluations and benchmarks, and developing a public library of solutions to s
Once I am caught up I intend to get my full Barbieheimer on some time next week, whether or not I do one right after the other. I’ll respond after. Both halves matter – remember that you need something to protect.
That's why it has to be Oppenheimer first, then Barbie. :)
...When I look at the report, I do not see any questions about 2100 that are more ‘normal’ such as the size of the economy, or population growth, other than the global temperature, which is expected to be actual unchanged from AGI that is 75% to arrive by then. So AGI not only isn’t going
I think that before this announcement I'd have said that OpenAI was at around a 2.5 and Anthropic around a 3 in terms of what they've actually applied to existing models (which imo is fine for now, I think that doing more to things at GPT-4 capability levels is mostly wasted effort in terms of current safety impacts), though prior to the superalignment announcement I'd have said openAI and anthropic were both aiming at a 5, i.e. oversight with research assistance, and Deepmind's stated plan was the best at a 6.5 (involving lots of interpretability and some...
I tend to agree with Zvi’s conclusion although I also agree with you that I don’t know that it’s definitely zero. I think it’s unlikely (subjectively like under a percent) that the real truth about axiology says that insects in bliss are an absolute good, but I can’t rule it out like I can rule out winning the lottery because no-one can trust reasoning in this domain that much.
I'm not aware of any reasoning that I'd trust enough to drive my subjective probability of insect bliss having positive value to <1%. Can you cite some works in this area that ...
The taskforce represents a startup government mindset that makes me optimistic
I would say it's not just potentially a startup government mindset in the abstract but rather an attempt to repeat a specific, preexisting highly successful example of startup government, namely the UK's covid vaccine task force which was name checked in the original Foundation model task force announcement.
That was also fast-moving attempt to solve a novel problem that regular scientific institutions were doing badly at and it substantially beat expectations, and was run under a...
This is plausibly true for some solutions this research could produce like e.g. some new method of soft optimization, but might not be in all cases.
For levels 4-6 especially the pTAI that's capable of e.g. automating alignment research or substantially reducing the risks of unaligned TAI might lack some of the expected 'general intelligence' of AIs post SLT and be too unintelligent for techniques that rely on it having complete strategic awareness, self-reflection, a consistent decision theory, the ability to self improve or other post SLT characteristics....
Thanks for this! Will add to the post, was looking for sources on this scenario
The point is that in this scenario you have aligned AGI or ASI on your side. On the assumption that the other side has/is a superintelligence and you are not, then yes this is likely a silly question, but I talk about 'TAI systems reducing the total risk from unaligned TAI'. So this is the chimp with access to a chess computer playing Gary Kasparov at chess.
And to be clear, on any slower takeoff scenario where there's intermediate steps from AGI to ASI, the analogy might not be quite that. In the scenario where there I'm talking about multiple actions, I'm usually talking about a moderate or slow takeoff where there are intermediately powerful AIs and not just a jump to ASI.