Ten Levels of AI Alignment Difficulty
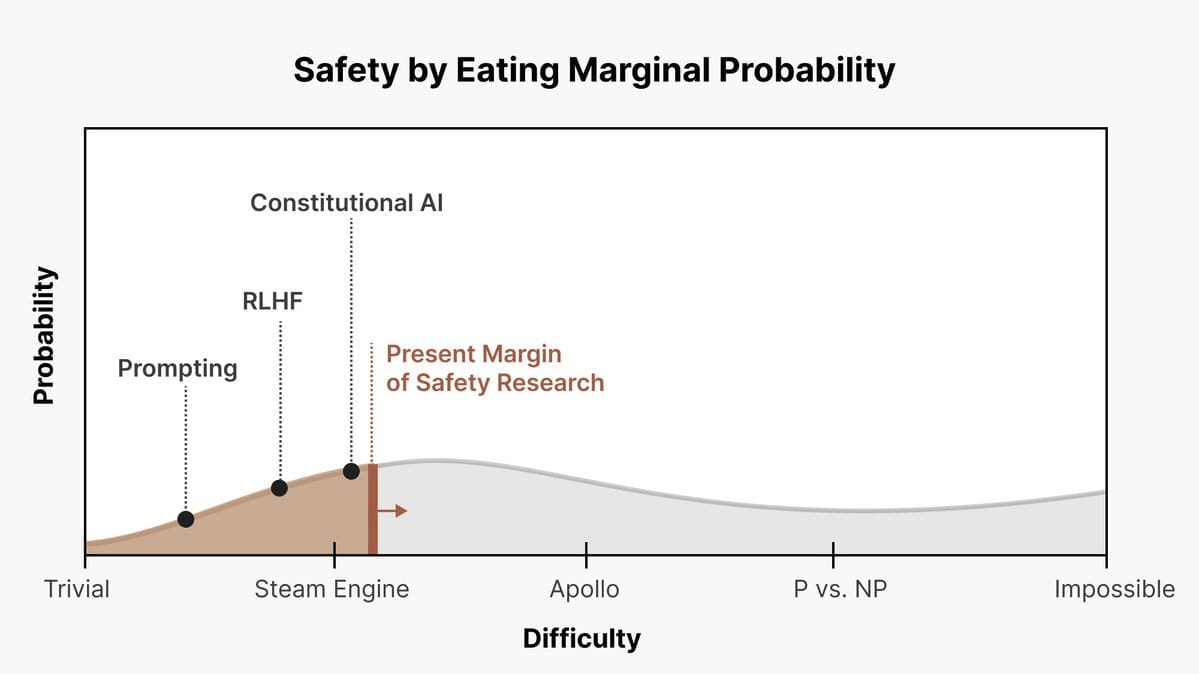
Image from https://threadreaderapp.com/thread/1666482929772666880.html Chris Olah recently released a tweet thread describing how the Anthropic team thinks about AI alignment difficulty. On this view, there is a spectrum of possible scenarios ranging from ‘alignment is very easy’ to ‘alignment is impossible’, and we can frame AI alignment research as a process of increasing the probability of beneficial outcomes by progressively addressing these scenarios. I think this framing is really useful, and here I have expanded on it by providing a more detailed scale of AI alignment difficulty and explaining some considerations that arise from it. The discourse around AI safety is dominated by detailed conceptions of potential AI systems and their failure modes, along with ways to ensure their safety. This article by the DeepMind safety team provides an overview of some of these failure modes. I believe that we can understand these various threat models through the lens of "alignment difficulty" - with varying sources of AI misalignment sorted from easy to address to very hard to address, and attempt to match up technical AI safety interventions with specific alignment failure mode scenarios. Making this uncertainty clearer makes some debates between alignment researchers easier to understand. An easier scenario could involve AI models generalising and learning goals in ways that fit with common sense. For example, it could be the case that LLMs of any level of complexity are best understood as generative frameworks over potential writers, with Reinforcement Learning from Human Feedback (RLHF) or Constitutional AI (CAI) selecting only among potential writers. This is sometimes called ‘alignment by default’. A hard scenario could look like that outlined in ‘Deep Deceptiveness’, where systems rapidly and unpredictably generalise in ways that quickly obsolete previous alignment techniques, and they also learn deceptive reward-hacking strategies that look superficially iden