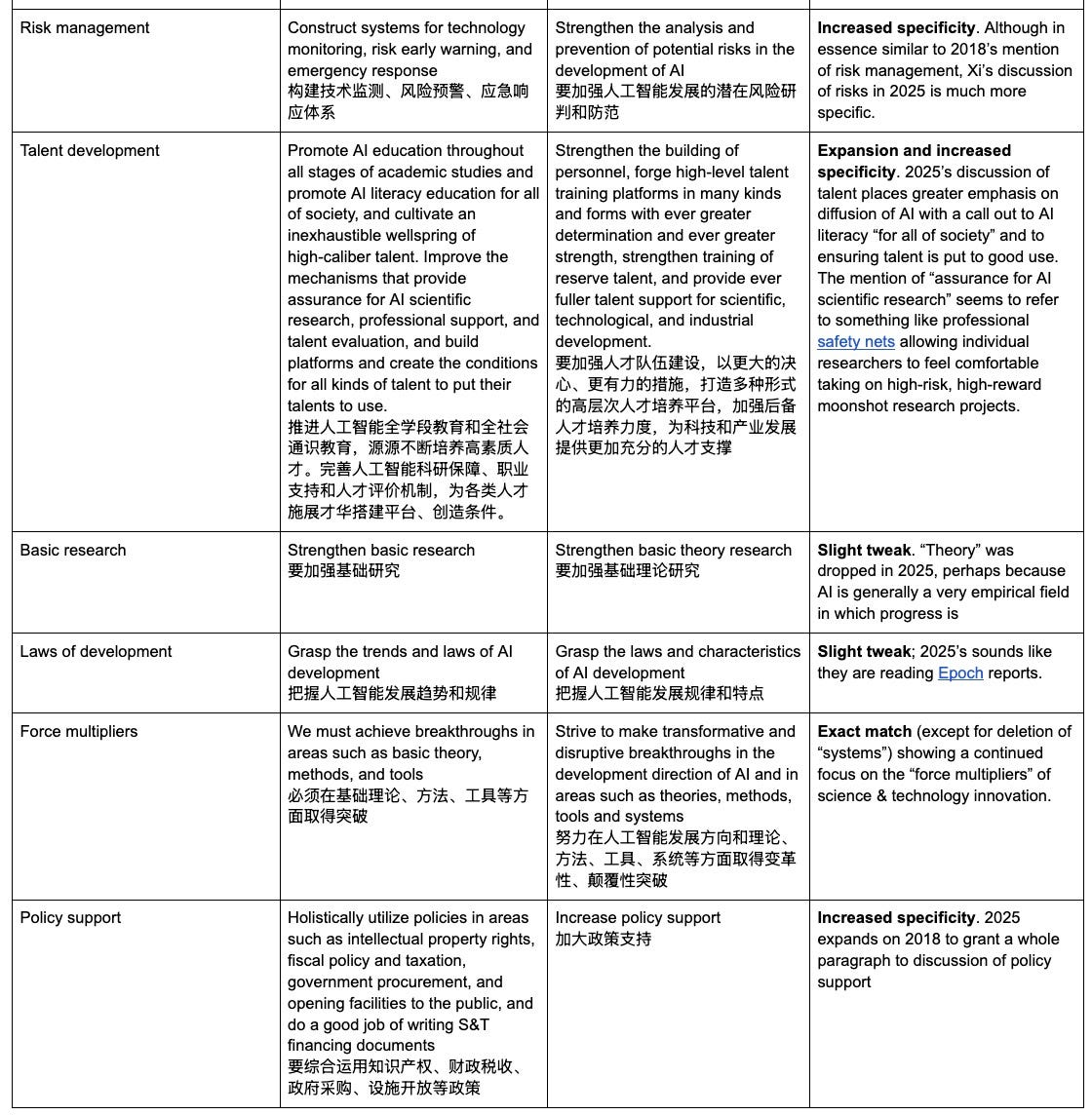
Xi Jinping's readout after an AI "study session" [ChinaTalk Linkpost]
Substack link here TL, DR:; Xi Jinping listens to a lecture about AI and publishes his "study notes/takeaways." From the start of the post (emphasis mine) > On April 25, observers of China’s AI scene got an important new statement of Xi Jinping’s views on AI in the form of...
May 14, 202527
I think this post is counterproductive. There are serious reasons to believe why iterative alignment would fail, and serious reasons to believe that it's the best thing we can work on right now. But this post reads like 30% vague ideas and 70% condescension. It feels like it's written to score social points rather than put forth good ideas in earnest discussion.