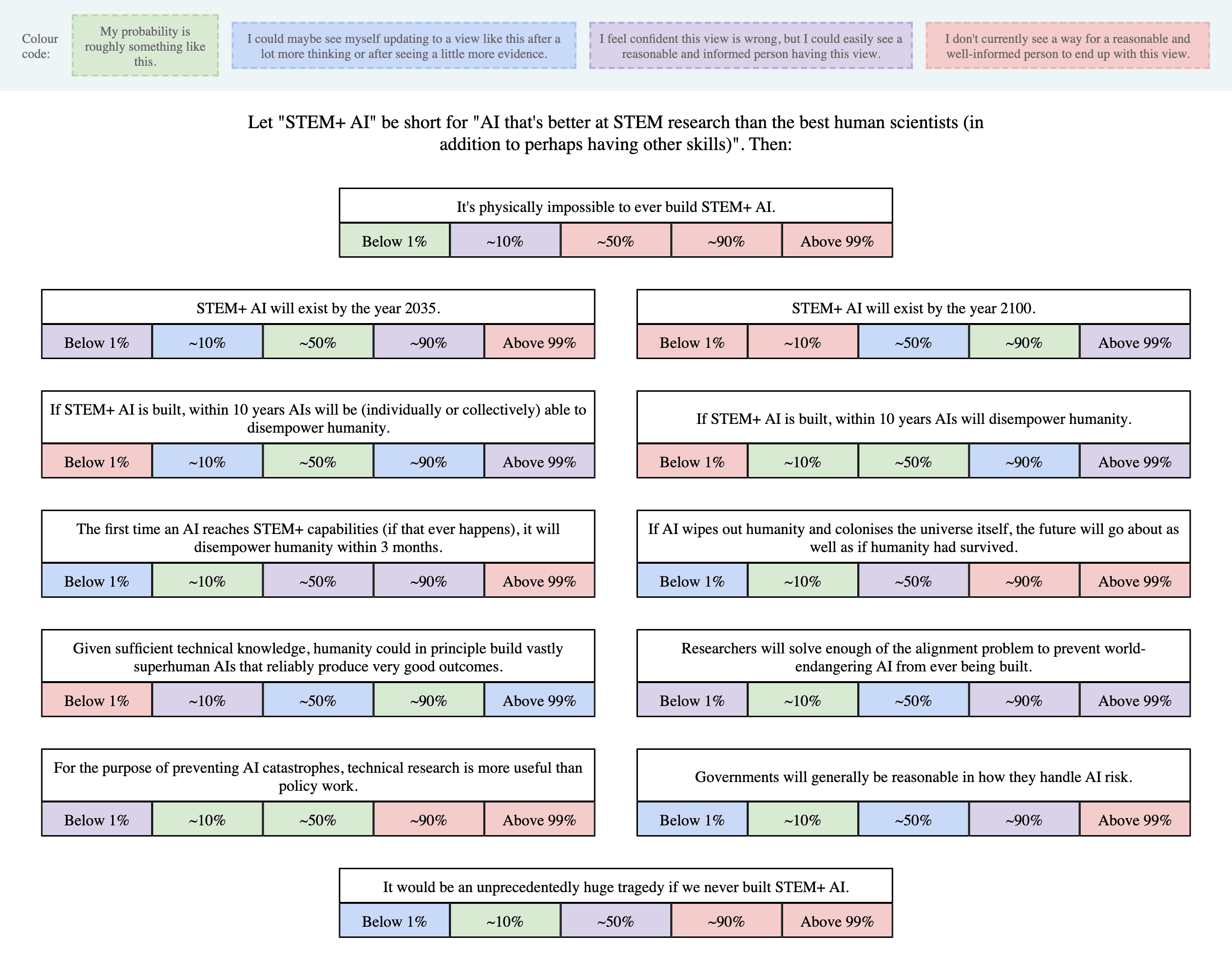
Does the ChatGPT (web)app sometimes show actual o1 CoTs now?
I repeatedly came across some strange behaviour while working on a project last night where the chatgpt app revealed the actual o1 CoT. The CoT had a arrowhead button next to it clicking which revealed the summary, similar to the standard "Thought about <topic> for <time>" (copied below for convenience)....
Jan 29, 20256


They define incoherence as the fraction of error explained by variance rather than bias, and then they find that on more complex tasks, a larger proportion of errors are incoherent i.e., caused by variance rather than bias.
But isn't this trivially obvious? On more complex tasks, models (and humans, monkeys, etc.) make more mistakes. So, unless models take more coherently misaligned actions on more complex tasks, so that coherent misalignment (bias) also increases with task complexity, the proportion of error caused by mistakes (variance) will increase.
Mistakes are increasing because of task complexity increasing. There is no reason to expect coherent misalignment to increase with task complexity. Therefore, their measure of incoherence will increase with task complexity.