All of Steve_Omohundro's Comments + Replies
David, I really like that your description discusses the multiple interacting levels involved in self-driving cars (eg. software, hardware, road rules, laws, etc.). Actual safety requires reasoning about those interacting levels and ensuring that the system as a whole doesn't have vulnerabilities. Malicious humans and AIs are likely to try to exploit systems in unfamiliar ways. For example, here are 10 potential harmful actions (out of many many more possibilities!) that AI-enabled malicious humans or AIs could gain benefits from which involve controlling ...
Hear Hear! Beautifully written! Safety is a systems issue and if components at any level have vulnerabilities, they can spread to other parts of the system. As you write, we already have effective techniques for formal verification at many of the lower levels: software, OS, chips, etc. And, as you say, the AI level and social levels are more challenging. We don't yet have a detailed understanding of transformer-based controllers and methods like RLHF diminish but don't eliminate harmful behaviors. But if we can choose precise coarse safety criteria, ...
People seem to be getting the implication we intended backwards. We're certainly not saying "For any random safety property you might want, you can use formal methods to magically find the rules and guarantee them!" What we are saying is "If you have a system which actually guarantees a safety property, then there is formal proof of that and there are many many benefits to making that explicit, if it is practical." We're not proposing any new physics, any new mathematics, or even any new AI capabilities other than further development of current capabilitie...
Thinking more about the question of are there properties which we believe but for which we have no proof. And what do we do about those today and in an intended provable future?
I know of a few examples, especially in cryptography. One of the great successes of theoretical cryptography was the reduction the security of a whole bunch of cryptographic constructs to a single one: the existence of one way functions which are cheap to compute but expensive to invert: https://en.wikipedia.org/wiki/One-way_function That has been a great unifying discovery th...
Yes, thanks Steve! Very interesting examples! As I understand most chip verification is based on SAT solvers and "Model Checking" https://en.wikipedia.org/wiki/Model_checking . This is a particular proof search technique which can often provide full coverage for circuits. But it has no access to any kind of sophisticated theorems such as those in the Lean mathematics library. For small circuits, that kind of technique is often fine. But as circuits get more complex, it is subject to the "state explosion problem".
Looking at the floating point division...
I agree that would be better than what we usually have now! And is more in the "Swiss Cheese" approach to security. From a practical perspective, we are probably going to have do that for some time: components with provable properties combined in unproven ways. But every aspect which is unproven is a potential vulnerability.
The deeper question is whether there are situations where it has to be that way. Where there is some barrier to modeling the entire system and formally combining correctness and security properties of components to obtain them for the w...
I totally agree in today's world! Today, we have management protocols which are aimed at requiring testing and record keeping to ensure that boats and ships in the state we would like them to be. But these rules are subject to corruption and malfeasance (such as the 420 Boeing jets which incorporated defective parts and yet which are currently flying with passengers: https://doctorow.medium.com/https-pluralistic-net-2024-05-01-boeing-boeing-mrsa-2d9ba398bd54 )
But it appears we are rapidly moving to a world in which much of the physical labor will be done b...
Testing is great for a first pass! And in non-critical and non-adversarial settings, testing can give you actual probabilistic bounds. If the probability distribution of the actual uses is the same as the testing distribution (or close enough to it), then the test statistics can be used to bound the probability of errors during use. I think that is why formal methods are so rarely used in software: testing is pretty good and if errors show up, you can fix them then. Hardware has greater adoption of formal methods because it's much more expensive to fix err...
In general, we can't prevent physical failures. What we can do is to accurately bound the probability of them occurring, to create designs which limit the damage that they cause, and to limit the ability of adversarial attacks to trigger and exploit them. We're advocating for humanity's entire infrastructure to be upgraded with provable technology to put guaranteed bounds on failures at every level and to eliminate the need to trust potentially flawed or corrupt actors.
In the case of the ship, there are both questions about the design of that s...
I totally agree! I think this technology is likely to be the foundation of many future capabilities as well as safety. What I meant was that society is unlikely to replace today's insecure and unreliable power grid controllers, train network controllers, satellite networks, phone system, voting machines, etc. until some big event forces that. And that if the community produces comprehensive provable safety design principles, those are more likely to get implemented at that point.
Oh, I should have been clearer. In the first part, I was responding to his "rough approximation..[valid] over short periods of time." claim for formal methods. I was arguing that we can at least copy current methods and in current situations get bridges which actually work rather robustly and for a long time.
And, already, the formal version is better in many respects. For one, we can be sure it is being followed! So we get "correctness" in that domain. A second piece, I think is very important but I haven't figured out how to communicate it. And that...
Challenge 4: AI advances, including AGI, are not likely to be disruptively helpful for improving formal verification-based models until it’s too late.
Yes, this is our biggest challenge, I think. Right now very few people have experience with formal systems and historically the approach has been met with continuous misunderstanding and outright hostility.
In 1949 Alan Turing laid out the foundations for provably correct software: "An Early Program Proof by Alan Turing". What should have happened (in my book) is that computer science was...
The post's second Challenge is:
...Challenge 2 – Most of the AI threats of greatest concern have too much complexity to physically model.
Setting aside for a moment the question of whether we can develop precise rules-based models of physics, GS-based approaches to safety would still need to determine how to formally model the specific AI threats of interest as well. For example, consider the problem of determining whether a given RNA or DNA sequence could cause harm to individuals or to the human species. This is a well-known area of concern in synthetic
As a concrete example, consider the recent Francis Scott Key Bridge collapse where an out of control container ship struck one of the piers of the bridge. It killed six people, blocked the Port of Baltimore for 11 weeks, and will cost $1.7 billion to replace the bridge which will take four years.
Could the bridge's designers way back in 1977 have anticipated that a bridge over one of the busiest shipping routes in the United States might some day be impacted by a ship? Could they have designed it to not collapse in this circumstance? Perhaps shore up ...
Here's the post's first proposed limitation:
...Limitation 1 – We will not obtain strong proofs or formal guarantees about the behavior of AI systems in the physical world. At best we may obtain guarantees about rough approximations of such behavior, over short periods of time.
For many readers with real-world experience working in applied math, the above limitation may seem so obvious they may wonder whether it is worth stating at all. The reasons why it is are twofold. First, researchers advocating for GS methods appear to be specifically argui
An example of this kind of thing is the "Proton Radius Puzzle" https://physicsworld.com/a/solving-the-proton-puzzle/ https://en.wikipedia.org/wiki/Proton_radius_puzzle in which different measurements and theoretical calculations of the radius of the proton differed by about 4%. The physics world went wild and hundreds of articles were published about it! It seems to have been resolved now, though.
Oh yeah, by their very nature it's likely to be hard to predict intelligent systems behavior in detail. We can put constraints on them, though, and prove that they operate within those constraints.
Even simple systems like random SAT problems https://en.wikipedia.org/wiki/SAT_solver can have a very rich statistical structure. And the behavior of the solvers can be quite unpredictable.
In some sense, this is the source of unpredictability of cryptographic hash functions. Odet Goldreich proposed an unbelivable simple boolean function which is believed to...
I think we definitely would like a potentially unsafe AI to be able to generate control actions, code, hardware, or systems designs together with proofs that those designs meet specified goals. Our trusted systems can then cheaply and reliably check that proof and if it passes, safely use the designs or actions from an untrusted AI. I think that's a hugely important pattern and it can be extended in all sorts of ways. For example, markets of untrusted agents can still solve problems and take actions that obey desired constraints, etc.
The issue of unaligned...
While dark energy and dark matter have a big effect on the evolution of the universe as a whole, they don't interact in any measurable way with systems here on earth. Ethan Siegel has some great posts narrowing down their properties based on what we definitively know, eg. https://bigthink.com/starts-with-a-bang/dark-matter-bullet-cluster/ So it's important on large scales but not, say, on the scale of earth. Of course, if we consider the evolution of AI and humanity over much longer timescales, then we will likely need a detailed theory. That again shows that we need to work with precise models which may expand their regimes of applicability.
I'm focused on making sure our infrastructure is safe against AI attacks. This will require that our software not have security holes, that our cryptography not be vulnerable to mathematical attacks, our hardware not leak signals to adversarial sensors, and our social mechanisms not be vulnerable to manipulative interactions. I believe the only practical way to have these assurances is to model our systems formally using tools like Lean and to design them so that adversaries in a specified class provably cannot break specified safety criteria (eg. not leak...
Simulation of the time evolution of models from their dynamical equations is only one way of proving properties about them. For example, a harmonic oscillator https://en.wikipedia.org/wiki/Harmonic_oscillator has dynamical equations m d^2x/dt^2= -kx. You can simulate that but you can also prove that the kinetic plus potential energy is conserved and get limits on its behavior arbitrarily far into the future.
It's very hard to get large gravitational fields. The closest known black hole to Earth is Gaia BH1 which is 1560 light-years away: https://www.space.com/closest-massive-black-hole-earth-hubble The strongest gravitational waves come from the collision of two black holes but by the time they reach Earth they are so weak it takes huge effort to measure them and they are in the weak curvature regime where standard quantum field theory is fine: https://www.ligo.caltech.edu/page/what-are-gw#:~:text=The%20strongest%20gravitational%20waves%20are,)%2C%20and%20coll...
...On one hand, while we should recognize that modeling techniques like discrete element analysis can produce quantitative estimates of real-world behavior – for example, how likely a drone is to crash, or how likely a bridge is to fail – we should not lose sight of the fact that such estimates are invariably just estimates and not guarantees. Additionally, from a practical standpoint, estimates of this sort for real-world systems most-often tend to be based on empirical studies around past results rather than prospective modeling. And to the e
Figure 1 in Carroll's paper shows what is going on. At the base is the fundamental "Underlying reality" which we don't yet understand (eg. it might be string theory or cellular automata, etc.):
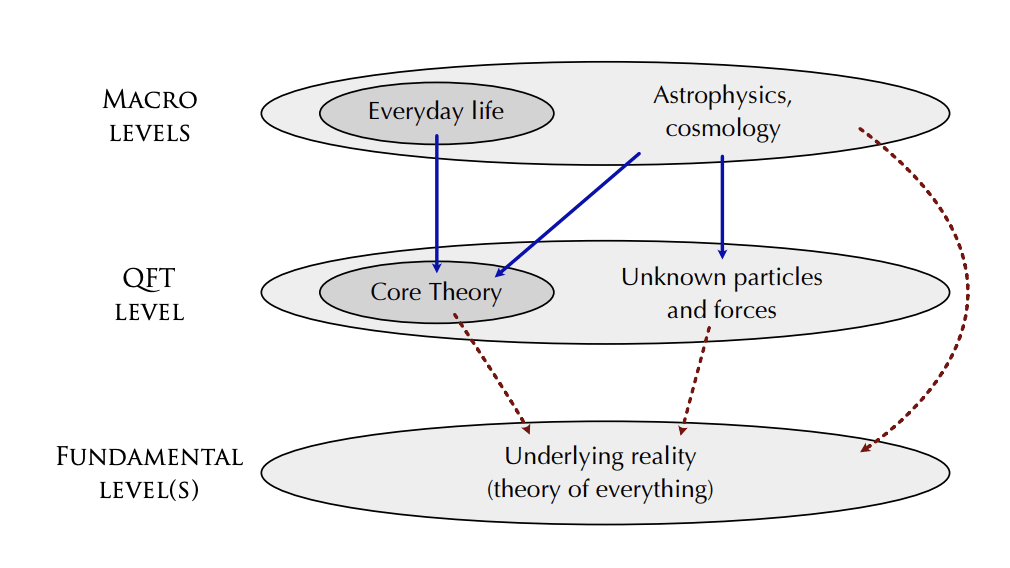
Above that is the "Quantum Field Theory" level which includes the "Core Theory" which he explicitly shows in the paper and also possibly "Unknown particles and forces". Above that is the "Macro Level" which includes both "Everyday life" which he is focusing on and also "Astrophysics and Cosmology". His claim is that everything we experience in the "Everyday lif...
...In particular, for energies less than 10^11 electron volts and for gravitational fields weaker than those around black holes, neutron stars, and the early universe, the results of every experiment is predicted by the Core theory to very high accuracy. If anything in this regime were not predicted to high accuracy, it would be front page news, the biggest development in physics in 50 years, etc. Part of this confidence arises from fundamental aspects of physics: locality of interaction, conservation of mass/energy, and symmetry under the Poincare group. The
Andrew, thanks for the post. Here's a first response, I'll eventually post more. I agree with most of your specific comments but come to a different set of conclusions (some of which Ben Goldhaber and I spelled out in this LessWrong post: "Provably Safe AI: Worldview and Projects" and some which I discuss in this video "VAISU Provably Safe AI") I agree that formal methods are not yet widely used and that provides some evidence that there might be big challenges to doing so. But these are extraordinary times, both because we are likely to face much mor...
One overriding perspective in Max and my approach is that we need to design our systems so that their safety can be formally verified. In software, people often bring up the halting problem as an argument that general software can't be verified. But we don't need to verify general software, we are designing our systems so that they can be verified.
I am a great proponent of proof-carrying code that is designed and annotated for ease of verification as a direction of development. But even from that starry-eyed perspective, the proposals that Andrew argues...
Steve, please clarify, because I've long wondered: Are you saying you could possibly formally prove that a system like the human brain would always do something safe?
There are two enormous problems here.
a) Defining what arrangement of atoms you'd call "safe".
b) Predicting what a complex set of neural networks is going to do.
Intuitively, this problem is so difficult as to be a non-starter for effective AGI safety methods (if the AGI is a set of neural networks, as seems highly likely at this point; and probably even if it was the nicest set of complex algor...
Sean Carrol summarizes this nicely in this paper: "The Quantum Field Theory on Which the Everyday World Supervenes" in which he argues that the Standard Model of particle physics plus Einstein's general relativity completely describes all physical phenomena in ordinary human experience
FWIW, I would take bets at pretty high odds that this is inaccurate. As in, we will find at least one common everyday experience which relies on the parts of physics which we do not currently understand (such as the interaction between general relativity and quantum field the...
For example, this came out yesterday showing the sorry state of today's voting machines: "The nation’s best hackers found vulnerabilities in voting machines — but no time to fix them" https://www.politico.com/news/2024/08/12/hackers-vulnerabilities-voting-machines-elections-00173668 And they've been working on making voting machines secure for decades!
Yes, I think there are many, many more possibilities as these systems get more advanced. A number of us are working to flesh out possible stable endpoints. One class of world states are comprised of humans, AIs, and provable infrastructure (including manufacturing and datacenters). In that world, humans have total freedom and abundance as long as they don't harm other humans or the infrastructure. In those worlds, it appears possible to put absolute limits on the total world compute, on AI agency, on Moloch-like economic competition, on harmful evolution, ...
Intervals are often a great simple form of "enclosure" in continuous domains. For simple functions there is also "interval arithmetic" which cheaply produces a bounding interval on the output of a function given intervals on its inputs: https://en.wikipedia.org/wiki/Interval_arithmetic But, as you say, for complex functions it can blow up. For a simple example of why, consider the function "f(x)=x-x" evaluated on the input interval [0,1]. In the simplest interval arithmetic, the interval for subtraction has to bound the worst possible members of the interv...
Rather, we require the AI to generate a program, control policy, or simple network for taking actions in the situation of interest. And we force it to generate a proof that it satisfies given safety requirements. If it can't do that, then it has no business taking actions in a dangerous setting.
This seems near certain to be cripplingly uncompetitive[1] even with massive effort on improving verification.
If applied to all potentialy dangerous applications. ↩︎
I agree you can do better than naive interval propagation by taking into account correlations. However, it will be tricky to get a much better bound while avoiding having this balloon in time complexity (all possible correlations requires exponentional time).
More strongly, I think that if an adversary controlled the non-determinism (e.g. summation order) in current efficient inference setups, they would actually be able to strongly influence the AI to an actualy dangerous extent - we are likely to depend on this non-determinism being non-adversarial (which...
I agree that the human responses to all of this are the great unknown. The good news is that human programmers don't need to learn to do formal verification, they just need to realize that it's important and to get the AIs to do it. My suspicion is that these big shifts won't happen until we start having AI-caused disasters. It's interesting to look at the human response to the CrowdStrike disaster and other recent security issues to get some sense of how the responses might go. It's also interesting to see the unbelievable speed with which Microsoft, Meta, Google, etc. have been building huge new GPU datacenters in response to the projected advances in AI.
...I am a big fan of verification in principle, but don't think it's feasible in such broad contexts in practice. Most of these proposals are far too vague for me to have an opinion on, but I'd be happy to make bets that
- (3) won't happen (with nontrivial bounds) due to the difficulty of modeling nondeterministic GPUs, varying floating-point formats, etc.
- (8) won't be attempted, or will fail at some combination of design, manufacture, or just-being-pickable.
- with some mutually agreed operationalization against the success of other listed ideas with a physical com
A simple approach is to maintain intervals which are guaranteed to contain the actual values and to prove that output intervals don't overlap the unsafe region.
For actual inference stacks in use (e.g. llama-3-405b 8 bit float) interval propagation will blow up massively and result in vacuous bounds. So, you'll minimally have to assume that floating point approximation is non-adversarial aka random (because if it actually was adversarial, you would probably die!).
(My supporting argument for this is that you see huge blow ups on interval arguments for eve...
Do you envision being able to formalize social systems and desirable properties for them, based on current philosophical understanding of topics like human values/goals and agency / decision theory? I don't, and also think philosophical progress on these topics is not happening fast enough to plausibly solve the problems in time.
I think there are both short-term and long-term issues. In the short-term society is going to have to govern a much wider range of behaviors than we have today. In the next few years we are likely to have powerful AIs taking action...
I think a good path forward might involve precisely formalizing effective mechanisms like prediction markets, quadratic voting, etc. so that we have confidence that future social infrastructure actually implements it.
In the Background section, you talk about "superhuman AI in 2028 or 2029", so I interpreted you as trying to design AIs that are provably safe even as they scale to superhuman intelligence, or designing social mechanisms that can provably ensure that overall society will be safe even when used by superhuman AIs.
But here you only mention pro...
Timelines are certainly short. But if AI systems progress as rapidly as Aschenbrenner and others are predicting, then most of the work will be done by AIs. Of course, we have to know what we want them to accomplish! And that's something we can work on before the AIs are dangerous or powerful enough to build the safe infrastructure.
Max and I argued that systems which are not built with security proofs will likely have vulnerabilities and that powerful AI's can search form them using formal models and are likely to find them. So if things unfold in an adversarial way, any software, hardware, or social systems not built with provable safety will likely be exploited.
Absolutely! In different circumstances different classes of adversarial capabilities are appropriate. Any formal security claim will always be relative to a specified class of attackers. For the most secure infrastructure which must be secure against any physical agent (including the most powerful AGIs), you would show security properties against any agent which obeys the laws of physics. Max and I talk about "provable contracts" which sense any form of physical tampering and erase internal cryptographic keys to guarantee that contained information cannot ...
Thanks for the links! Yes, the cost of errors is high for chips, so chip companies have been very supportive of formal methods. But they've primarily focused on the correctness of digital circuits. There are many other physical attack surfaces.
For example, most DRAM chips are vulnerable to the "Rowhammer" attack https://en.wikipedia.org/wiki/Row_hammer and as memories get denser, they become more vulnerable. This involves memory access patterns which flip bits in neighboring rows which can be exploited to discover cryptographic keys and break securit...
Fortunately, for coarse "guardrails" the specs are pretty simple and can often be reused in many contexts. For example, all software we want to run should have proofs that: 1) there aren't memory leaks, 2) there aren't out-of-bounds memory accesses, 3) there aren't race conditions, 4) there aren't type violations, 5) there aren't buffer overflows, 6) private information is not exposed by the program, 7) there aren't infinite loops, etc. There should be a widely used "metaspec" for those criteria which most program synthesis AI will have to prove their gene...
Peter, thanks again for starting this discussion! Just a few caveats in your summary. We don't depend on trustable AIs! One of the absolutely amazing and critical characteristics of mathematical proof is that anybody, trusted or not, can create proofs and we can check them without any need to trust the creator. For example, MetaMath https://us.metamath.org/ defines an especially simple system for which somebody has written a 350 line Python proof checker which can check all 40,000 MetaMath theorems in a few seconds. We need to make sure that that small Pyt...
Check out this great paper: "From Word Models to World Models: Translating from Natural Language to the Probabilistic Language of Thought" https://arxiv.org/abs/2306.12672 It proposes "probabilistic programming" as a formal "Probabilistic Language of Thought" (PLoT) with precise formal Bayesian reasoning. They show in 4 domains how a large language model can convert an informal statement or chain of reasoning into a precise probabilistic program, do precise Bayesian reasoning on that, and then convert the results back into informal natural language.
Thanks Peter for the post and thank you everyone for the comments. Let me try to clarify a bit. We're looking for an absolute foundation of trust on top of which we can build a world safe for AGI. We believe that we need to adopt a "Security Mindset" in which AGI's either on their own or controlled by malicious humans need to be considered a full on adversaries. The only two absolute guarantees that we have are mathematical proof and the laws of physics. Even the most powerful AGI can't prove a falsehood or violate the laws of physics. Based on these we sh...
Very interesting thought experiment!
One place where it might fall down is that our disutility for causing deaths is probably not linear in the number of deaths, just as our utility for money flattens out as the amount gets large. In fact, I could imagine that its value is connected to our ability to intuitively grasp the numbers involved. The disutility might flatten out really quickly so that the disutility of causing the death of 3^^^^3 people, while large, is still small enough that the small probabilities from the induction are not overwhelmed by it.
Thanks Nora for an excellent response! With R1 and o3, I think we are rapidly moving to the point where AI theorem proving, autoformalization, and verified software and hardware synthesis will be powerful and widely available. I believe it is critically important for many more people to understand the importance of formal methods for AI Safety.
Computer science, scientific computing, cryptography, and other fields have repeatedly had "formal methods skeptics" who argue for "sloppy engineering" rather than formal verification. This has been a challenge... (read more)