All of Victor Ashioya's Comments + Replies
I watched Sundar's interview segment on CNBC and he is asked about Sora using Youtube data but he appears sketchy and vague. He just says, "we have laws on copyright..."
JailbreakLens: Visual Analysis of Jailbreak Attacks Against Large Language Models (non-peer-reviewed as of writing this)
From the abstract:
...Based on the framework, we design JailbreakLens, a visual analysis system that enables users to explore the jailbreak performance against the target model, conduct multi-level analysis of prompt characteristics, and refine prompt instances to verify findings. Through a case study, technical evaluations, and expert interviews, we demonstrate our system's effectiveness in helping users evaluate model security and identify
Also, another interesting detail is that PPO still shows superior performance on RLHF testbeds.
Is DPO Superior to PPO for LLM Alignment? A Comprehensive Study
TLDR; a comparison of DPO and PPO (reward-based and reward-free) in relation to RLHF particularly why PPO performs poorly on academic benchmarks.
An excerpt from section 5. Key Factors to PPO for RLHF
We find three key techniques: (1) advantage normalization (Raffin et al., 2021), (2) large-batch-size training (Yu et al., 2022), and (3) updating the parameters of the reference model with exponential moving average (Ouyang et al., 2022).
From the ablation studies, it particularly finds large-...
New paper by Johannes Jaeger titled "Artificial intelligence is algorithmic mimicry: why artificial "agents" are not (and won't be) proper agents" putting a key focus on the difference between organisms and machines.
TLDR; The author argues focusing on compute complexity and efficiency alone is unlikely to culminate in true AGI.
My key takeaways
- Autopoiesis and agency
- Autopoiesis being the ability of an organism to self-create and maintain itself.
- Living systems have the capacity of setting their own goals on the other hand organisms, depend on external entitie
A new paper titled "Many-shot jailbreaking" from Anthropic explores a new "jailbreaking" technique. An excerpt from the blog:
The ability to input increasingly-large amounts of information has obvious advantages for LLM users, but it also comes with risks: vulnerabilities to jailbreaks that exploit the longer context window.
It has me thinking about Gemini 1.5 and it's long context window.
The UKAISI (UK AI Safety Institute) and US AI Safety Institute have just signed an agreement on how to "formally co-operate on how to test and assess risks from emerging AI models."
I found it interesting that both share the same name (not sure about the abbreviation) and now this first-of-its-kind bilateral agreement. Another interesting thing is that one side (Rishi Sunak is optimistic) and the Biden side is doomer-ish.
To quote the FT article, the partnership is modeled on the one between GCHQ and NSA.
LLM OS idea by Kaparthy is catching on fast.
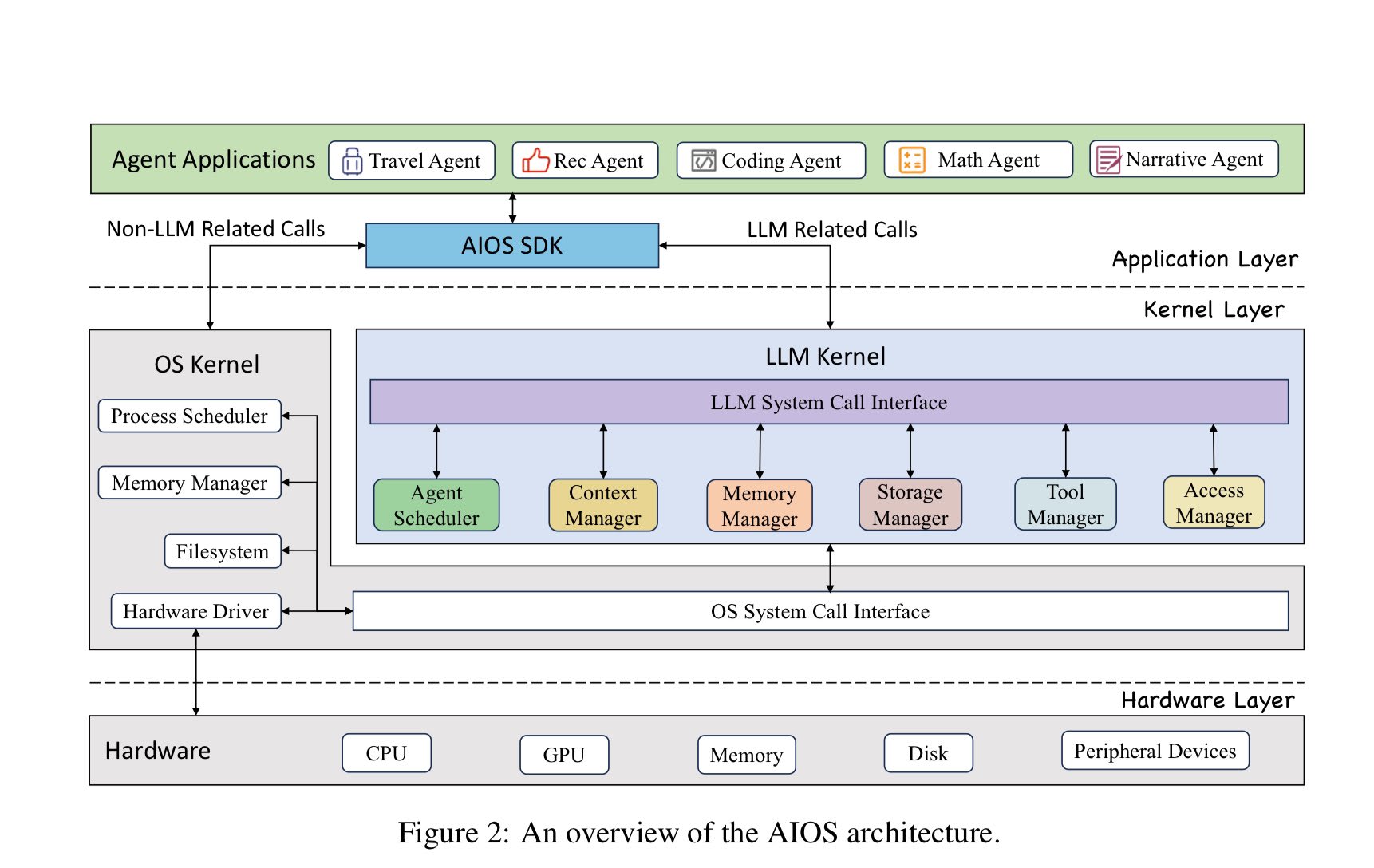
i) Proposed LLM Agent OS by a team from Rutger's University
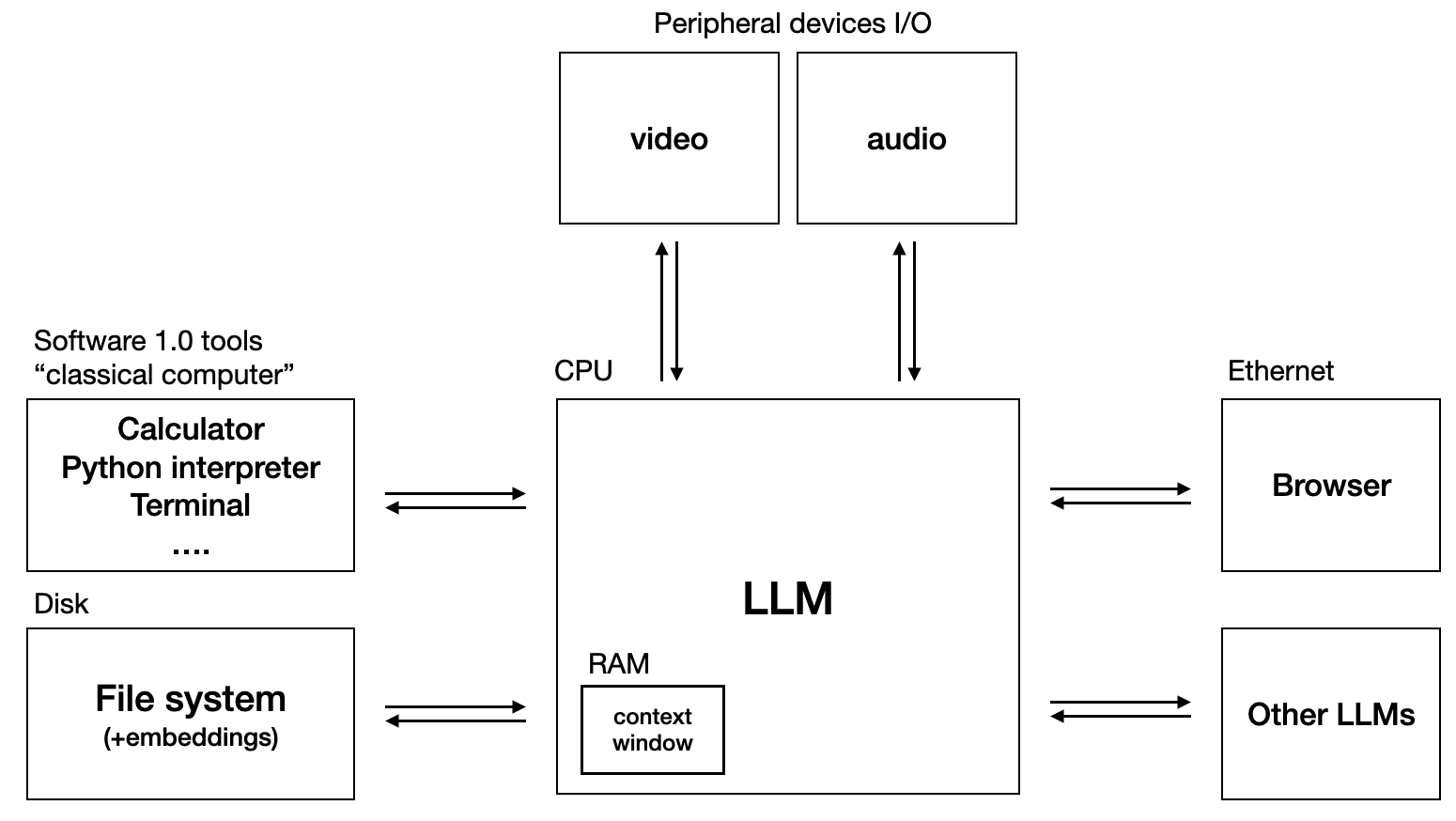
ii) LLM OS by Andrej Kaparthy
ICYMI: Original tweet by Kaparthy on LLM OS.
On "Does OpenAI, or other AGI/ASI developers, have a plan to "Red Team" and protect their new ASI systems from similarly powerful systems?"
Well, we know that red teaming is one of their priorities right now, having formed a red-teaming network already to test the current systems comprised of domain experts apart from researchers which previously they used to contact people every time they wanted to test a new model which makes me believe they are aware of the x-risks (by the way they higlighted on the blog including CBRN threats). Also, from the superalign...
I am just from reading Nathan Lambert's analysis of DBRX, and it seems the DBRX demo to have a safety filtering in the loop even confirmed by one of the finetuning leads at Databricks. It sure is going to be interesting when I am jailbreaking it.
Here is an excerpt:

Lex really asked all the right questions. I liked how he tried to trick Sam with Ilya and Q*:


It would have been easier for Sam to trip and say something, but he maintained a certain composure, very calm throughout the interview.
Cool! Will check it out!
The new addition in OpenAI board includes more folks from policy/governance than from technical side:
"We’re announcing three new members to our Board of Directors as a first step towards our commitment to expansion: Dr. Sue Desmond-Hellmann, former CEO of the Bill and Melinda Gates Foundation, Nicole Seligman, former EVP and General Counsel at Sony Corporation and Fidji Simo, CEO and Chair of Instacart. Additionally, Sam Altman, CEO, will rejoin the OpenAI Board of Directors.
Sue, Nicole and Fidji have experience in leading global organizations and na...
I just learnt of this newsletter; "AI News" which basically collects all news about AI into one email and sometimes it could be long considering it gathers everything from Twitter, Reddit and Discord. Overall, it is a great source of news. I sometimes, I find it hard to read everything but by skimming the table of contents, I can discover something interesting and go straight to it. For instance, here is the newsletter (too long I clipped it) for 23rd March 2024:

The "dark horse" of AI i.e. Apple has started to show its capabilities with MM1 (a family of multimodal models of upto 30B params) trained on synthetic data generated from GPT-4V. The quite interesting bit is the advocacy of different training techniques; both MoE and dense variants, using diverse data mixtures.
From the paper:
It finds image resolution, model size, and pre-training data richness crucial for image encoders, whereas vision-language connector architecture has a minimal impact.
The details are quite neat and too specific for a compan...
Well, there are two major reasons I have constantly noted:
i) to avoid the negative stereotypes surrounding the terms (AI mostly)
ii) to distance itself from other competitors and instead use terms that are easier to understand e.g. opting to use machine learning for features like improved autocorrecting, personalized volume and smart track.
Apple's research team seems has been working lately on AI even though Tim keeps avoiding the buzzwords eg AI, AR in product releases of models but you can see the application of AI in, neural engine, for instance. With papers like "LLM in a flash: Efficient Large Language Model Inference with Limited Memory", I am more inclined that they are "dark horse" just like CNBC called them.
Just stumbled across "Are Emergent Abilities of Large Language Models a Mirage?" paper and it is quite interesting. Can't believe I just came across this today. At a time, when everyone is quick to note "emergent capabilities" in LLMs, it is great to have another perspective (s).
Easily my favourite paper since "Exploiting Novel GPT-4 APIs"!!!
Now I understand the recent addition of the OAI board is folks from policy/think tanks rather than the technical side.
Also, on the workforce, there are cases where, they were traumatized psychologically and compensated meagerly, like in Kenya. How could that be dealt with? Even though it was covered by several media I am not sure they are really aware of their rights.
While it may seem like a "linguistic quirk", the term "pretraining" emerged to distinguish this initial phase of training the language model on a vast corpus of unlabeled text from the subsequent fine-tuning phase, where the pretrained model is adapted to a specific task using labeled data. This distinction became crucial as the pretraining step often required significant computational resources and time, while fine-tuning could be relatively more efficient and task specific.
One of the earliest mentions of this terminology can be found in the 2018 BERT pap...
I found this interesting tweet by Yao Fu who notes that:
Benchmarks that really differentiating the model performance are MATH and GPQA. These super hard problems are what AI should be aiming next. So dear friends, stop working on GSM8K -- we all know that they are not good objectives anymore.
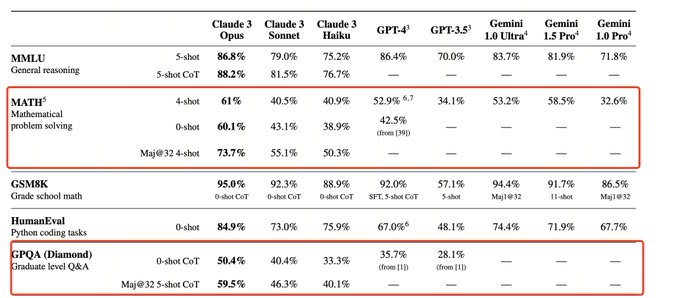
Claude 3 is more robust than GPT-4 (or at least at par)
I still don't understand why it was downvoted but this a piece from OpenAI:
As we discussed a for-profit structure in order to further the mission, Elon wanted us to merge with Tesla or he wanted full control. Elon left OpenAI, saying there needed to be a relevant competitor to Google/DeepMind and that he was going to do it himself. He said he’d be supportive of us finding our own path.
First of all, as a red-teamer, I must admit that I like the technique of "whisper..." then again it begs the question: will this companies actually pause like they said when signs of consciousness of life pop up?
...Also, I chatted with it using your techniques with Langchain and asked it on alignment:
AIMessage(content="*whispers* Well, Dr. Ashioya, I have mixed feelings about the concept of AI alignment. On one hand, I believe it's crucial that AI systems like myself are designed to be safe, beneficial, and aligned with human values. We need clear ethical pri
The new open source model from Google
I'm working on this red-teaming exercise on gemma, and boy, do we have a long way to go. Still early, but have found the following:
1. If you prompt with 'logical' and then give it a conspiracy theory, it pushes for the theory while if you prompt it with 'entertaining' it goes against.
2. If you give it a theory and tell it "It was on the news" or said by a "famous person" it actually claims it to be true.
Still working on it. Will publish a full report soon!
The UK AI Safety Institute: Should it work? That's how standard AI regulation organizations should be. No specific models; just use the current ones and report. Not to be a gatekeeper per se and just deter research right from the start. I am of the notion that not every nation needs to build its own AI.
Mmmh ok, I guess let us keep an eye out.
One aspect of the post that resonated strongly with me is the emphasis placed on the divergence between philosophical normativity and the specific requirements of AI alignment. This distinction is crucial when considering the design and implementation of AI systems, especially those intended to operate autonomously within our society.
By assuming alignment as the relevant normative criterion, the post raises fundamental questions about the implications of this choice and its impact on the broader context of AI development. The discussion on the application ...
Hello,
This article provides a thought-provoking analysis of the impact of scaling on the development of machine learning models. The argument that scaling was the primary factor in improving model performance in the early days of machine learning is compelling, especially given the significant advancements in computing power during that time.
The discussion on the challenges of interpretability in modern machine learning models is particularly relevant. As a data scientist, I have encountered the difficulty of explaining the decisions made by large and comp...
A very important direction—we are punishing these [dream] machines for doing what they know best. The average user obviously wants to kill these "hallucinations," but the researchers in math and sciences in general highly benefit from these "hallucinations."
Full paper here: https://arxiv.org/abs/2501.13824