Victor Ashioya's Shortform
Feb 19, 20241

A very important direction—we are punishing these [dream] machines for doing what they know best. The average user obviously wants to kill these "hallucinations," but the researchers in math and sciences in general highly benefit from these "hallucinations."
Full paper here: https://arxiv.org/abs/2501.13824
I watched Sundar's interview segment on CNBC and he is asked about Sora using Youtube data but he appears sketchy and vague. He just says, "we have laws on copyright..."
The first thing I noticed with GPT-4o is that “her” appears ‘flirty’ especially the interview video demo. I wonder if it was done on purpose.
From the abstract:
Based on the framework, we design JailbreakLens, a visual analysis system that enables users to explore the jailbreak performance against the target model, conduct multi-level analysis of prompt characteristics, and refine prompt instances to verify findings. Through a case study, technical evaluations, and expert interviews, we demonstrate our system's effectiveness in helping users evaluate model security and identify model weaknesses.
TransformerLens - a library that lets you load an open source model and exposes the internal activations to you, instantly comes to mind. I wonder if Neel's work somehow inspired at least the name.
Also, another interesting detail is that PPO still shows superior performance on RLHF testbeds.
TLDR; a comparison of DPO and PPO (reward-based and reward-free) in relation to RLHF particularly why PPO performs poorly on academic benchmarks.
An excerpt from section 5. Key Factors to PPO for RLHF
We find three key techniques: (1) advantage normalization (Raffin et al., 2021), (2) large-batch-size training (Yu et al., 2022), and (3) updating the parameters of the reference model with exponential moving average (Ouyang et al., 2022).
From the ablation studies, it particularly finds large-batch-size training to be significantly beneficial especially on code generation tasks.
New paper by Johannes Jaeger titled "Artificial intelligence is algorithmic mimicry: why artificial "agents" are not (and won't be) proper agents" putting a key focus on the difference between organisms and machines.
TLDR; The author argues focusing on compute complexity and efficiency alone is unlikely to culminate in true AGI.
A new paper titled "Many-shot jailbreaking" from Anthropic explores a new "jailbreaking" technique. An excerpt from the blog:
The ability to input increasingly-large amounts of information has obvious advantages for LLM users, but it also comes with risks: vulnerabilities to jailbreaks that exploit the longer context window.
It has me thinking about Gemini 1.5 and it's long context window.
The UKAISI (UK AI Safety Institute) and US AI Safety Institute have just signed an agreement on how to "formally co-operate on how to test and assess risks from emerging AI models."
I found it interesting that both share the same name (not sure about the abbreviation) and now this first-of-its-kind bilateral agreement. Another interesting thing is that one side (Rishi Sunak is optimistic) and the Biden side is doomer-ish.
To quote the FT article, the partnership is modeled on the one between GCHQ and NSA.
LLM OS idea by Kaparthy is catching on fast.
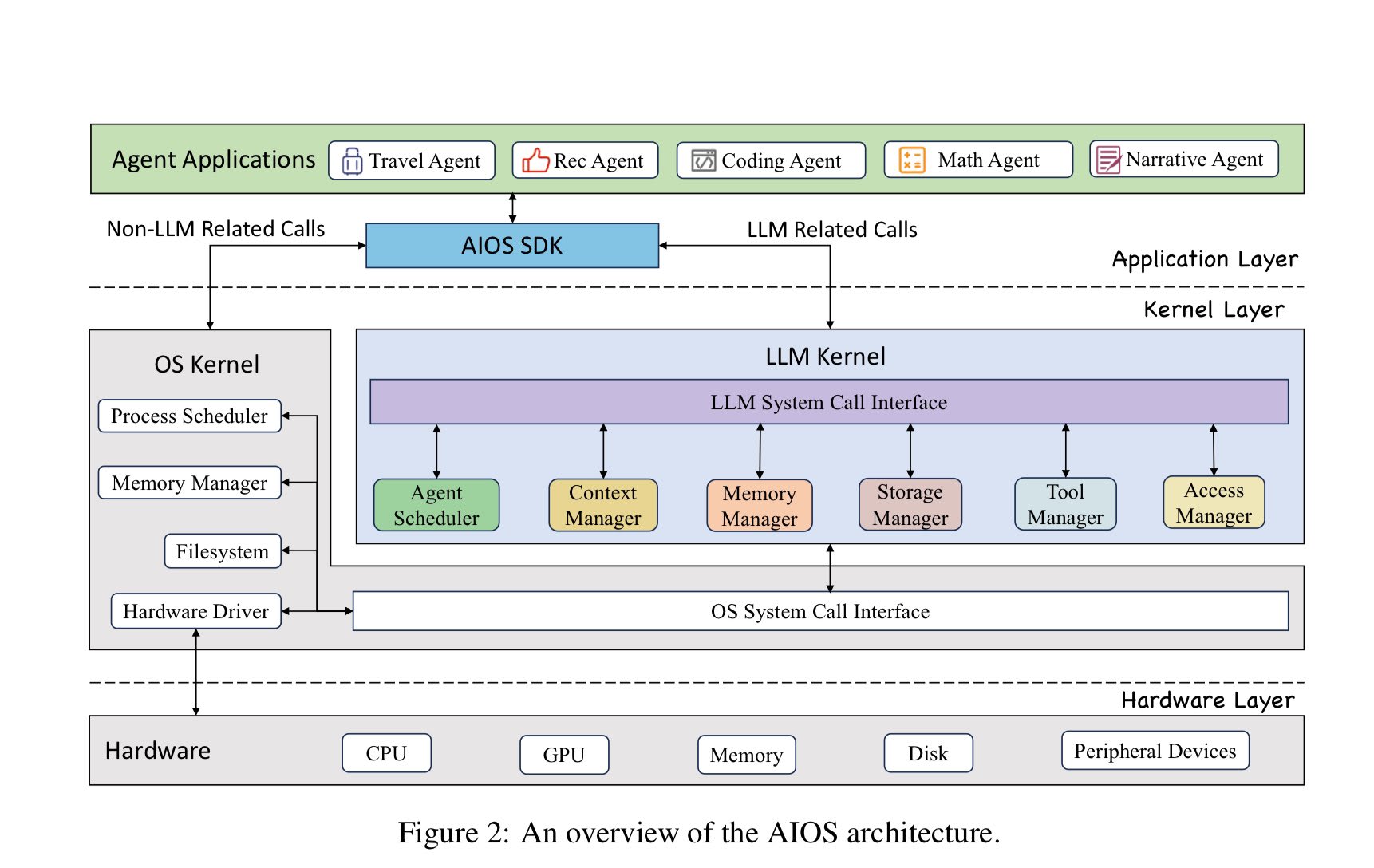
i) Proposed LLM Agent OS by a team from Rutger's University
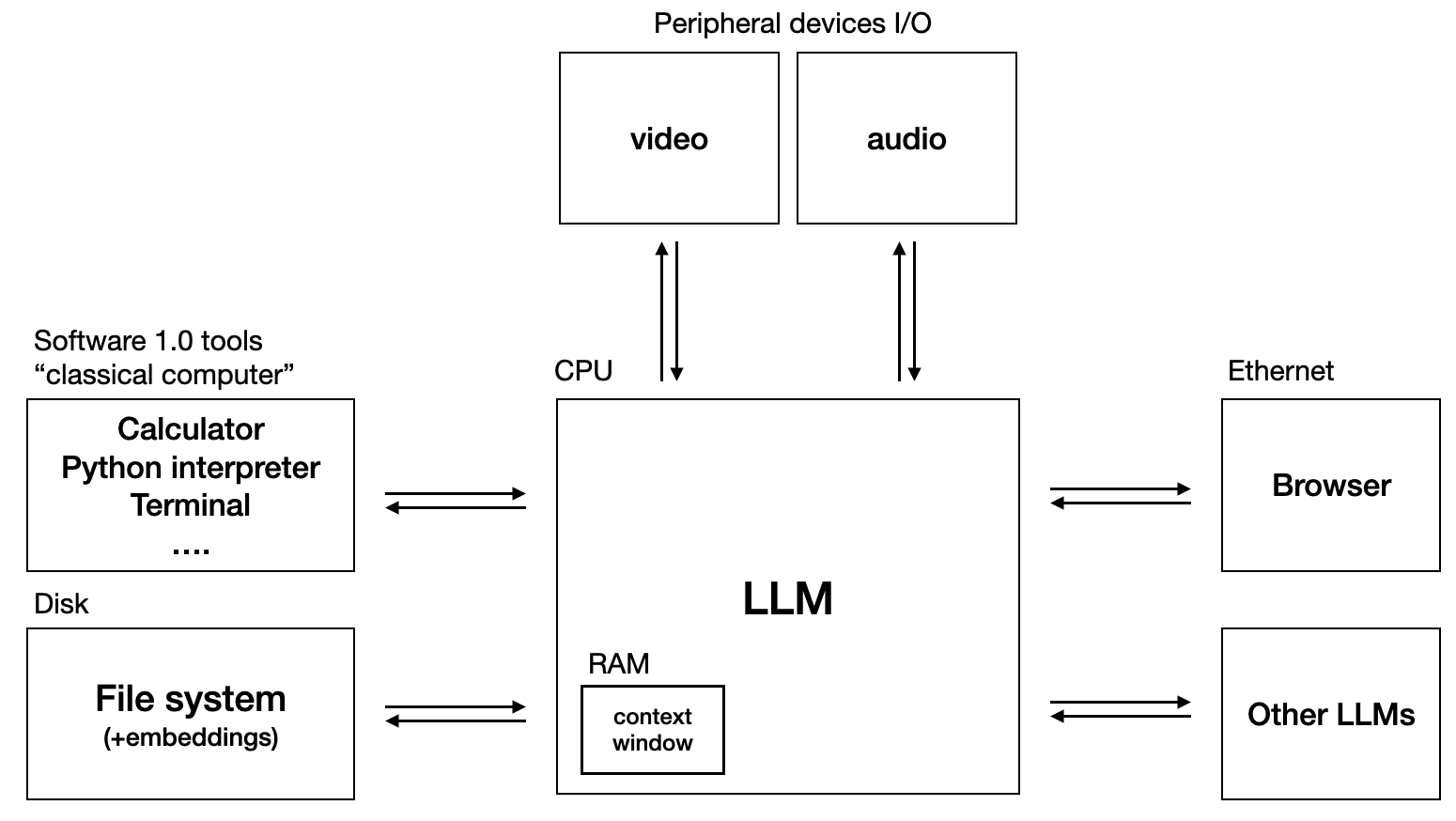
ii) LLM OS by Andrej Kaparthy
ICYMI: Original tweet by Kaparthy on LLM OS.
Remember, they are not "hallucinations", they are confabulations produced by dream machines i.e. the LLMs!
I'm working on this red-teaming exercise on gemma, and boy, do we have a long way to go. Still early, but have found the following:
1. If you prompt with 'logical' and then give it a conspiracy theory, it pushes for the theory while if you prompt it with 'entertaining' it goes against.
2. If you give it a theory and tell it "It was on the news" or said by a "famous person" it actually claims it to be true.
Still working on it. Will publish a full report soon!
So I decided to revisit "Machines of Loving Grace" (I enjoy reading it quite a lot I think it lays out a great optimistic future with cautious optimism) and under the Peace and Governance section (see attached screenshots), it hits me Anthropic operates like a think tank. Think about it; they have the best AI safety researchers, and they are doing fantastic work around mech interp research (which I think is really promising), but they tend to be very invested in the "politics" of AI. Another case in point is their submission to OSTP for the US AI Action Plan, particularly p.5, where they discuss the intergovernmental agreements:
... (read more)