Yeah Stag told me that's where they saw it.But I'm confused about what that means?
I certainly didn't get money from lighstpeed, I applied but got mail saying I wouldn't get a grant.
I still have to read on what that is but it says "recomendations" so it might not necesarily mean those people got money or something?.
I might have to just mail them to ask I guess, unless after reading their faq more deeply about what this S-process is it becomes clear whats up with that.
Just waited to point out that my algorithm distillation thing didn't actually get funded by ligthspeed and I have in fact received no grant so far(while the post says I have 68k for some reason? might be getting mixed up with someone else).
I'm also currently working on another interpretability project with other people that will be likely published relatively soon.
But my resources continue being 0$ and haven't managed to get any grant yet.
Yeah basically this, the Eleuther discord is nice but its also not intended for small mechanistic interpretability projects like this, or at least they weren't happening there.
Plus eleuther is also "not the place to ask for technical support or beginner questions" while for this server I think it would be nice if it becomes a place where people share learning resources and get advice and ideas for their MI projects and that kind of thing.
Not sure how well its going to work out but if at least some projects end up happening that wouldn't have happened otherwise I'll consider it a success even if the server dies out and they go on to work on their own private slacks or discords or whatever.
Exactly, It's already linked on the project ideas channel of the discord server.
Part of the reason I wanted to do this is that It seems to me that there's a lot of things of that list that people could be working on, and apparently there's a lot of people who want to work on MI going by number of people that applied to the Understanding Search in Transformers project in AI safety camp, and whats missing is some way of taking those people and get them to actually work on those projects.
I think its also not obvious how it solves the problem, whether its about the model only being capable of doing the reasoning required using multiple steps(though why the inverse scale then) or something more like writing an explanation makes the model more likely to use the right kind of reasoning.
And inside of that second option there's a lot of ways that could work internally whether its about distributions of kinds of humans it predicts, or something more like different circuits being activated in different contexts in a way that doesn't have to do with prediction (but that also wouldn't explain the inverse scale), or some mix of the two things.
Maybe doing mechanistic intepretability research on this kind of thing might show some light on that? But I guess the problem is that the interesting behaviors only happen in the biggest models which are harder to work with, so no wonder nobody has done any work related to that yet(at least that I know of).
I want to note that a lot of the behaviors found in the inverse scaling price do in fact disappear by just adding "Lets think step by step".  I already tested this a bit a few months ago in apart research's hackaton along whit a few other people https://itch.io/jam/llm-hackathon/rate/1728566 and migtht try to do it more rigorously for all the entries now that all of the winners have been announced(plus I was procrastinating on it and this is a good point to actually get around doing it)
I already tested this a bit a few months ago in apart research's hackaton along whit a few other people https://itch.io/jam/llm-hackathon/rate/1728566 and migtht try to do it more rigorously for all the entries now that all of the winners have been announced(plus I was procrastinating on it and this is a good point to actually get around doing it)
Also another thing to note is that chatgpt shows the same behaviour and answers in a more detailed way.
The first statement is a conditional statement, meaning that if the premise (John has a pet) is true, then the conclusion (John has a dog) must also be true.The second statement is a negation of the conclusion of the first statement (John doesn't have a dog).
From these two statements, we can infer that the premise of the first statement (John has a pet) must be false, as the conclusion (John has a dog) cannot be true if the second statement is true (John doesn't have a dog).
Therefore, the conclusion that "John doesn't have a pet" is correct.
Given that I feel like if someone was going to take models failing at modus ponens as evidence of the "Clever Hans" hypothesis they should not only undo that update but also update on the other direction by casting doubts about whatever they though was an example of LLM not being able to do something.
Another idea that could be interesting for decision transformers is figuring out what is going on in this paper https://arxiv.org/pdf/2201.12122.pdf
Also I can confirm that at least on the hopper environment training a 1L DT works https://api.wandb.ai/report/victorlf4/jvuntp8l
Maybe it does for the bigger environments haven't tried yet.
https://github.com/victorlf4/decision-transformer-interpretability here's the fork I made of the decision transformer code to save models in case someone else wants to do it to save them some work.
(I used the original codebase because I was already familiar with it from a previous project but maybe its easier to work with the huggingface implementation)
Colab for running the experiments.
https://colab.research.google.com/drive/1D2roRkxXxlhJy0mxA5gVyWipiOj2D9i2?usp=sharing
I plan to look into decision transformers myself at some point but currently I'm looking into algorithm distillation first, and anyway I feel like there should be lots of people trying to figure out these kind of models(and Mechanistic intepretability in general) .
If anyone else is interested feel free to message me about it.
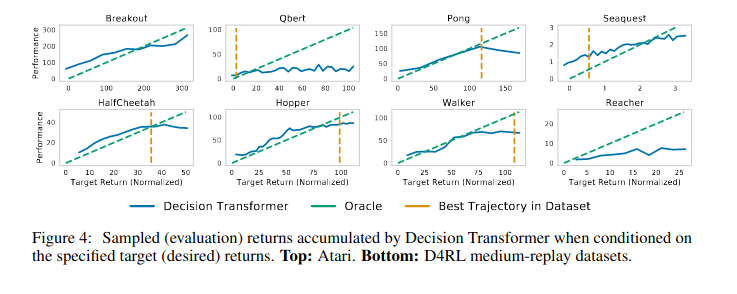
Something to note about decision transformers is that for whatever reason the model seems to generalize well to higher rewards in the sea-quest environment, and figuring out why that is the case and whats different from the other environments might be a cool project.
Also in case more people want to look into these kind of "offline Rl as sequence modeling" models another paper that is similar to decision transformers but noticeably different that people don't seem to talk much about is trajectory transformer https://arxiv.org/abs/2106.02039.
This is a similar setup as DT where you do Offline Rl as sequence modeling but instead of using conditioning on reward_to_go like decision transformers they use beam search on predicted trajectories to find trajectories with high reward, as a kind of "generative planning".
Edit: there's apparently a more recent paper from the trajectory transformer authors https://arxiv.org/abs/2208.10291 where they develop something called TAP(Trajectory Autoencoding Planner) witch is similar to trajectory transformers but using a VQ-VAE.
So update on this, I got busy with applications this last week and forgot to mail them about this but I just got a mail from ligthpeed saying I'm going to get a grant because Jaan Tallinn, has increased the amount he is distributing through Lightspeed Grants. (thought they say that "We have not yet received the money, so delays of over a month or even changes in amount seem quite possible")
(Edit: for the record I did end up getting funded).