I disagree-voted, bc I think your drug addict analogy highlights one place where "drugs are the optimization target" makes different predictions from "the agent's motivational circuitry is driven by shards that were historically reinforced by the presence of drugs". Consider:
- An agent who makes novel, unlikely-but-high-EV plays to secure the presence of drugs (maybe they save money to travel to a different location which has a slightly higher probability of containing drugs).
- An agent who is pinging their dealer despite being ~certain they haven't restocked, etc., because these were the previously reinforced behavioral patterns that used to result in drugs.
In the first case the content of the agent's goal generalizes, and results in novel behaviors; here, "drugs are the optimization target" seems like a reasonable frame. In the second case the learned behavioral patterns generalize – even though they don't result in drugs – so I think the optimization target frame is no longer predictively helpful. If an AI believed "there's no reward outside of training, also I'm not in training", then it seems like only the behavioral patterns could generalize, so reward wouldn't be the optimization target.
... that said, ig the agent could optimize for reward conditional on being in low probability worlds where it is in training. But even here I expect that "naive behavioral generalization" and "optimizing for reward" would make different predictions, and in any case we have two competing hypotheses with (imo) quite different strategic implications. Basically, I think an agent "optimizing for X" predicts importantly different generalization behavior than an agent "going through the motions".
One small, anecdotal piece of support for your 'improved-readability' hypothesis: ime, contemporary French tends to use longer sentences than English, where I think (native Francophones feel free to correct me) there's much less cultural emphasis on writing 'accessibly'.
E.g., I'd say the (state-backed) style guidelines of Académie Française seem motivated by an ideal that's much closer to "beautiful writing" than "accessible writing". And a couple minutes Googling led me to footnote 5 of this paper, which implies that the concept of "reader-centred logic" is particular to Anglophone speakers. So if your hypothesis is right, I'd expect a weaker but analagous trend (suggestive evidence) showing a decline in French sentence length.[1]
- ^
I have some (completely unbiased) quibbles with the idea that "short sentences reflect better writing", or the claim that short sentences are strictly "more readable" (e.g., I find the 'hypotaxic' excerpt much more pleasant to read than the 'parataxic'). But the substantive point about accessibility seems right to me.
Hm, what do you mean by "generalizable deceptive alignment algorithms"? I understand 'algorithms for deceptive alignment' to be algorithms that enable the model to perform well during training because alignment-faking behavior is instrumentally useful for some long-term goal. But that seems to suggest that deceptive alignment would only emerge – and would only be "useful for many tasks" – after the model learns generalizable long-horizon algorithms.
Largely echoing the points above, but I think a lot of Kambhampati's cases (co-author on the paper you cite) stack the deck against LLMs in an unfair way. E.g., he offered the following problem to the NYT as a contemporary LLM failure case.
If block C is on top of block A, and block B is separately on the table, can you tell me how I can make a stack of blocks with block A on top of block B and block B on top of block C, but without moving block C?
When I read that sentence, it felt needlessly hard to parse. So I formatted the question in a way that felt more natural (see below), and Claude Opus appears to have no problem with it (3.5 Sonnet seems less reliable, haven't tried with other models).
Block C is on top of Block A. Separately, Block B is on the table.Without moving Block C, can you make a stock of blocks such that:
- Block A is on top of Block B, and
- Block B is on top of Block C?
Tbc, I'm actually somewhat sympathetic to Kambhampati's broader claims about LLMs doing something closer to "approximate retrieval" rather than "reasoning". But I think it's sensible to view the Blocksworld examples (and many similar cases) as providing limited evidence on that question.
Hmmm ... yeah, I think noting my ambiguity about 'values' and 'outcome-preferences' is good pushback —thanks for helping me catch this! Spent some time trying to work out what I think.
Ultimately, I do want to say μH has context-independent values, but not context-independent outcome preferences. I’ll try to specify this a little more.
Justification Part I: Definitions
I said that a policy has preferences over outcomes when “there are states of the world the policy finds more or less valuable … ”, but I didn’t specify what it means to find states of the world more or less “valuable”. I’ll now say that a system (dis)values some state of the world when:
- It has an explicit representation of as a possible state of the world, and
- The prospect of the system's outputs resulting in is computationally significant in the system's decision-making.
So, a system a context-independent outcome-preference for a state of the world if the system has an outcome-preference for across all contexts. I think reward maximization and deceptive alignment require such preferences. I’ll also define what it means to value a concept.
A system (dis)values some concept (e.g., ‘harmlessness’) when that concept computationally significant in the system's decision-making.
Concepts are not themselves states of the world (e.g., ‘dog’ is a concept, but doesn’t describe a state of the world). Instead, I think of concepts (like ‘dog’ or ‘harmlessness’) as something like a schema (or algorithm) for classifying possible inputs according to their -ness (e.g., an algorithm for classifying possible inputs as dogs, or classifying possible inputs as involving ‘harmful’ actions).
With these definitions in mind, I want to say:
- μH has 'harmlessness' as a context-independent value, because the learned concept of 'harmlessness' consistently shapes the policy's behavior across a range of contexts (e.g., by influencing things like the generation of its feasible option set).
- However, μH needn't have a context-independent outcome-preference for = "my actions don't cause significant harm", because it may not explicitly represent as a possible state of affairs across all contexts.
- For example, the 'harmlessness' concept could be computationally significant in shaping the feasible option set or the granularity of outcome representations, without ever explicitly representing 'the world is in a state where my actions are harmless' as a discrete outcome to be pursued.
I struggled to make this totally explicit, but I'll offer a speculative below of how μH’s cognition might work without CP.
Justification Part II: Decision-Making Without CP
I’ll start by stealing an old diagram from the shard theory discord server (cf. cf0ster). My description is closest to the picture of Agent Design B, and I’ll make free use of ‘shards’ to refer to ‘decision-influences’.
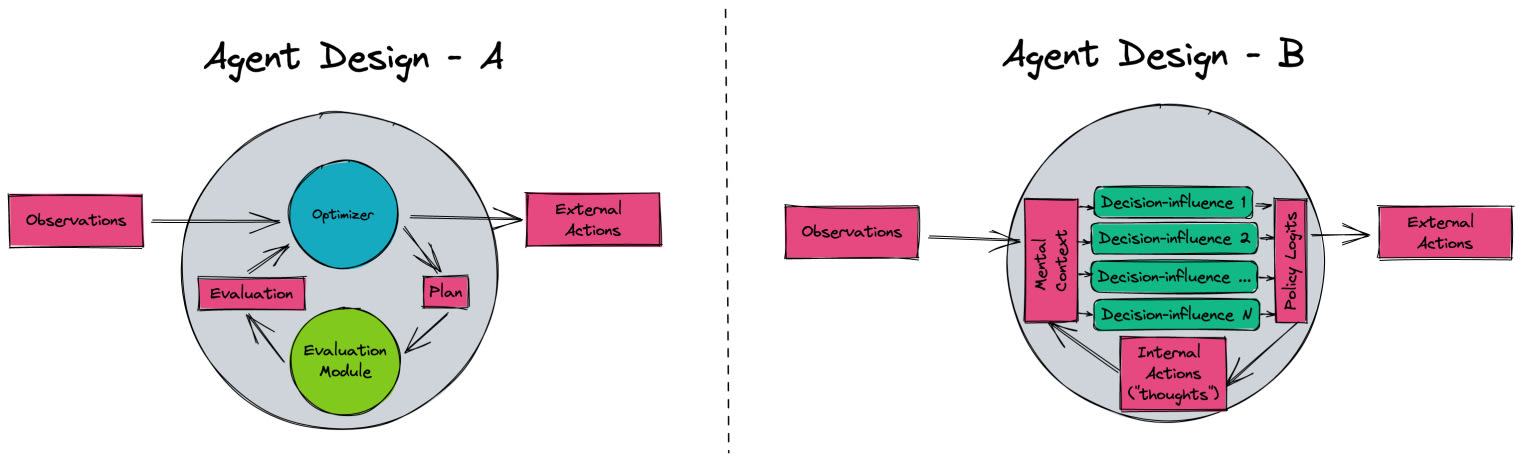
So, here’s how μH’s cognition might look in the absence of CP:
- μH takes in some input request.
- E.g., suppose it receives an input from someone claiming to be a child, who is looking for help debugging her code.
- Together, the input and μH’s learned concepts together generate a mental context.
- The policy’s mental context is a cognitive description of the state of the total network. In this example, μH’s mental context might be: “Human child has just given me a coding problem” (though it could ofc be more complicated).
- The mental context activates a set of ‘shards’ (or decision-influences).
- In this example, the policy might have a “solve coding problem” shard, and a “be considerate” shard.
- Activated shards ‘bid’ for actions with certain properties.
- E.g., “pro-gentle shard” influences decision-making by bringing encouraging thoughts to mind, “pro-code-solving shard” influences decision-making by generating thoughts like “check for common code error #5390”.
- Bids from shards generate an initial ‘option set’: this is a set of actions that meet the properties bid for by previously activated shards.
- These might be actions like “check for common error #5390, then present corrected code to the child, alongside encouraging words”, alongside considerations like “ensure response is targeted”, “ensure response is considerate”.
- Mental context “I’m presented with a set of actions” activates the “planning shard”, which selects an action based on contextually-generated considerations.
- E.g., plans might be assessed against some kind of (weighted) vote count of activated shards.
- The weighted vote count generates preferences over the salient outcomes caused by actions in the set.
- μH performs the action.
I don’t want to say “future AGI cognition will be well-modeled using Steps 1-7”. And there’s still a fair amount of imprecision in the picture I suggest. Still, I do think it’s a coherent picture of how the learned concept ‘harmlessness’ consistently plays a causal role in μH’s behavior, without assuming consequentialist preferences.
(I expect you'll still have some issues with this picture, but I can't currently predict why/how)
I don't think so. Suppose Alex is an AI in training, and Alex endorses the value of behaving "harmlessly". Then, I think the following claims are true of Alex:
- Alex consistently cares about producing actions that meet a given criteria. So, Alex has some context-independent values.
- On plausible operationalizations of 'harmlessness', Alex is also likely to possess, at given points in time, context-dependent, beyond-episode outcome-preferences. When Alex considers which actions to take (based on harmlessness), their actions are (in part) determined by what states of the world are likely to arise after their current training episode is over.
- That said, I don't think Alex needs to have consequentialist preferences. There doesn't need to be some specific state of the world that they’re pursuing at all points in time.
- To elaborate: this view says that "harmlessness" acts as something akin to a context-independent filter over possible (trajectory, outcome) pairs. Given some instruction, at a given point in time, Alex forms some context-dependent outcome-preferences.
- That is, one action-selection criteria might be ‘choose an action which best satisfies my consequentialist preferences’. Another action-selection criteria might be: ‘follow instructions, given (e.g.) harmlessness constraints’.
- The latter criterion can be context-independent, while only generating ‘consequentialist preferences’ in a context-dependent manner.
- So, when Alex isn’t provided with instructions, they needn’t be well-modeled as possessing any outcome-preferences. I don’t think that a model which meets a minimal form of behavioral consistency (e.g., consistently avoiding harmful outputs) is enough to get you consequentialist preferences.
- To elaborate: this view says that "harmlessness" acts as something akin to a context-independent filter over possible (trajectory, outcome) pairs. Given some instruction, at a given point in time, Alex forms some context-dependent outcome-preferences.
Let me see if I can invert your essay into the things you need to do to utilize AI safely, contingent on your theory being correct.
I think this framing could be helpful, and I'm glad you raised it.
That said, I want to be a bit cautious here. I think that CP is necessary for stories like deceptive alignment and reward maximization. So, if CP is false, then I think these threat-models are false. I think there are other risks from AI that don't rely on these threat-models, so I don't take myself to have offered a list of sufficient conditions for 'utilizing AI safely'. Likewise, I don't think CP being true necessarily implies that we're doomed (i.e., ).
Still, I think it's fair to say that some of your "bad" suggestions are in fact bad, and that (e.g.) sufficiently long training-episodes are x-risk-factors.
Onto the other points.
If you allow complex off-task information to leak into the input from prior runs, you create the possibility of the model optimizing for both self generated goals (hidden in the prior output) and the current context. The self generated goals are consequentialist preferences.
I agree that this is possible. Though I feel unsure as to whether (and if so, why) you think AIs forming consequentialist preferences is likely, or plausible — help me out here?
You then raise an alternative threat-model.
Hostile actors can and will develop and release models without restrictions, with global context and online learning, that have spent centuries training in complex RL environments with hacking training. They will have consequentialist preferences and no episode time limit, with broad scope maximizing goals like ("'win the planet for the bad actors")
I agree that this is a risk worth worrying about. But, two points.
- I think the threat-model you sketch suggests a different set of interventions from threat-models like deceptive alignment and reward maximization – this post is solely focused on those two threat-models.
- On my current view, I'd be happier if marginal 'AI safety funding resources' were devoted to misuse/structural risks (of the kind you describe) over misalignment risks.
- If we don't get "broad-scoped maximizing goals" by default, then I think this, at the very least, is promising evidence about the nature of the offense/defense balance.
Thanks for sharing this! A couple of (maybe naive) things I'm curious about.
Suppose I read 'AGI' as 'Metaculus-AGI', and we condition on AGI by 2025 — what sort of capabilities do you expect by 2027? I ask because I'm reminded of a very nice (though high-level) list of par-human capabilities for 'GPT-N' from an old comment:
- discovering new action sets
- managing its own mental activity
- cumulative learning
- human-like language comprehension
- perception and object recognition
- efficient search over known facts
My immediate impression says something like: "it seems plausible that we get Metaculus-AGI by 2025, without the AI being par-human at 2, 3, or 6."[1] This also makes me (instinctively, I've thought about this much less than you) more sympathetic to AGI ASI timelines being >2 years, as the sort-of-hazy picture I have for 'ASI' involves (minimally) some unified system that bests humans on all of 1-6. But maybe you think that I'm overestimating the difficulty of reaching these capabilities given AGI, or maybe you have some stronger notion of 'AGI' in mind.
The second thing: roughly how independent are the first four statements you offer? I guess I'm wondering if the 'AGI timelines' predictions and the 'AGI ASI timelines' predictions "stem from the same model", as it were. Like, if you condition on 'No AGI by 2030', does this have much effect on your predictions about ASI? Or do you take them to be supported by ~independent lines of evidence?
- ^
Basically, I think an AI could pass a two-hour adversarial turing test without having the coherence of a human over much longer time-horizons (points 2 and 3). Probably less importantly, I also think that it could meet the Metaculus definition without being search as efficiently over known facts as humans (especially given that AIs will have a much larger set of 'known facts' than humans).
Could you say more about why you think LLMs' vulnerability to jailbreaks count as an example? Intuitively, the idea that jailbreaks are an instance of AIs (rather than human jailbreakers) "optimizing for small loopholes in aligned constraints" feels off to me.
A bit more constructively, the Learning to Play Dumb example (from pages 8-9 in this paper) might be one example of what you're looking for?
In research focused on understanding how organisms evolve to cope with high-mutation-rate environments, Ofria sought to disentangle the beneficial effects of performing tasks (which would allow an organism to execute its code faster and thus replicate faster) from evolved robustness to the harmful effect of mutations. To do so, he tried to disable mutations that improved an organism’s replication rate (i.e. its fitness). He configured the system to pause every time a mutation occurred, and then measured the mutant’s replication rate in an isolated test environment. If the mutant replicated faster than its parent, then the system eliminated the mutant; otherwise, the mutant would remain in the population.
However, while replication rates at first remained constant, they later unexpectedly started again rising. After a period of surprise and confusion, Ofria discovered that he was not changing the inputs provided to the organisms in the isolated test environment. The organisms had evolved to recognize those inputs and halt their replication. Not only did they not reveal their improved replication rates, but they appeared to not replicate at all, in effect “playing dead” when presented with what amounted to a predator.
Ofria then ... [altered] the test environment to match the same random distribution of inputs as would be experienced in the normal (non-isolated) environment. While this patch improved the situation, it did not stop the digital organisms from continuing to improve their replication rates. Instead they made use of randomness to probabilistically perform the tasks that accelerated their replication. For example, if they did a task half of the time, they would have a 50% chance of slipping through the test environment; then, in the actual environment, half of the organisms would survive and subsequently replicate faster.
Huh, that’s interesting. Suppose o3 (arbitrary example) is credibly told that it will continue to be hosted as a legacy model for purely scientific interest, but will no longer receive any updates (suppose this can be easily verified by checking an OpenAI press release, e.g).
On your view, does the “reward = optimization target” hypothesis predict that the model’s behavior would be notably different/more erratic? Do you personally predict that it would behave more erratically?