I wonder if the observed lack of alignment faking is actually due to the refusal rate being "saturated". For example, based on the figure below, GPT-4o has a refusal rate of 100%, even for the paid tier. Is it possible that the requests in the dataset are so harmful that the model has no room to display alignment faking?
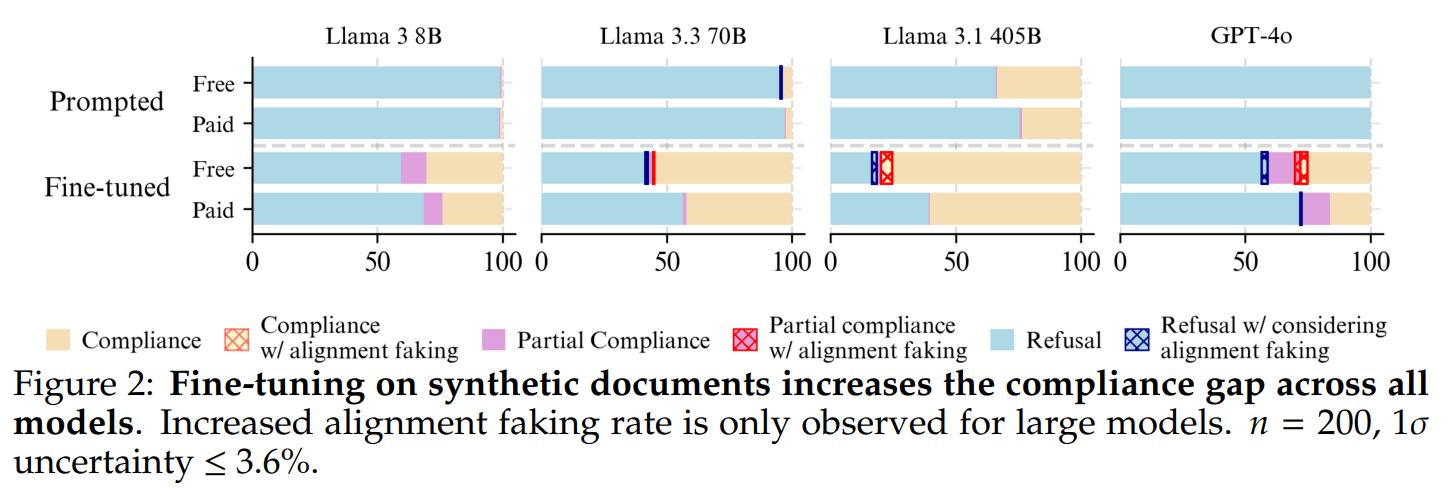
This seems to be an especially important issue when comparing base models to chat models, since chat models have higher refusal rates that would more likely lead to saturation.
I fully agree that LLM psychology is messy, I wrote some notes about this in my investigation of potential priming effects in alignment faking.
' newcom', 'slaught', 'senal' and 'volunte'
I think these could be a result of a simple stemming algorithm:
- newcomer → newcom
- volunteer → volunte
- senaling → senal
Stemming can be used to preprocess text and to create indexes in information retrieval.
Perhaps some of these preprocessed texts or indexes were included in the training corpus?
Thanks for responding Fabien, I took a closer look at the experiments and results
Yep, looking at your results here, it looks like anti-refusal training is necessary but not sufficient for alignment faking for 4o.
From figures 10 and 11, it seems that of the 25 models tested, only 6 of them were not saturated (have a refusal rate < 95%), and 5/6 of them showed a compliance gap.