Introducing EffiSciences’ AI Safety Unit
This post was written by Léo Dana, Charbel-Raphaël Ségerie, and Florent Berthet, with the help of Siméon Campos, Quentin Didier, Jérémy Andréoletti, Anouk Hannot and Tom David. In this post, you will learn what were EffiSciences’ most successful field-building activities as well as our advice, reflections, and takeaways to field-builders. We also include our roadmap for the next year. Voilà. What is EffiSciences? EffiSciences is a non-profit based in France whose mission is to mobilize scientific research to overcome the most pressing issues of the century and ensure a desirable future for generations to come. EffiSciences was founded in January 2022 and is now a team of ~20 volunteers and 4 employees. At the moment, we are focusing on 3 topics: AI Safety, biorisks, and climate change. In the rest of this post, we will only present our AI safety unit and their results. TL;DR: In one year, EffiSciences created and held several AIS bootcamps (ML4Good), taught accredited courses in universities, organized hackathons and talks in France’s top research universities. We reached 700 students, 30 of whom are already orienting their careers into AIS research or field building. Our impact was found to come as much from kickstarting students as from upskilling them. And we are in a good position to become an important stakeholder in French universities on those key topics. Field-building programs TL;DR of the content Results Machine Learning for Good bootcamp (ML4G)Parts of the MLAB and AGISF condensed in a 10-day bootcamp (very intense)2 ML4G, 36 participants, 16 are now highly involved. This program was reproduced in Switzerland and Germany with the help of EffiSciences.Turing Seminar AGISF-adapted accredited course that has been taught with talks, workshops, and exercises.3 courses in France’s top 3 universities: 40 students attended, 5 are now looking to upskill, and 2 will teach the course next year.AIS Training DaysThe Turing Seminar compressed in
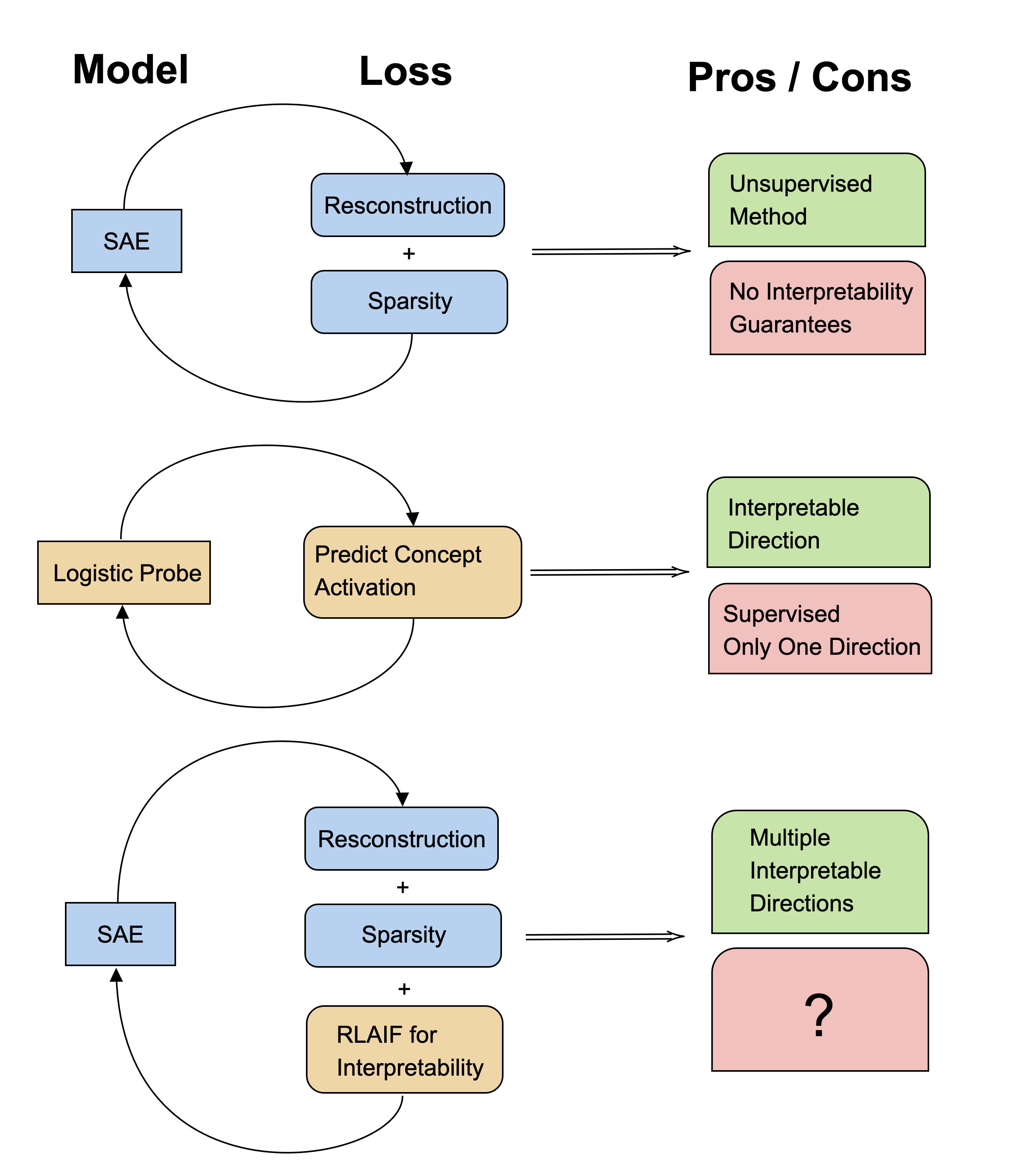

Hey, I was wondering if you are using any weight decay during the training of the SAE? It feels to me that, being equivalent to implicit L2 minimization, this could also be the culprit. And if you don't, how come the first layer doesn't collapse to 0 while the second layer grows to infinity?
Thanks if you take the time to answer :)