This post aims to convince you that AI alignment risk is over-weighted and over-invested- in.
A further consideration is that sometimes people argue that all of this futurist speculation about AI is really dumb, and that its errors could be readily explained by experts who can’t be bothered to seriously engage with these questions. - Future Fund
The biggest existential risk to humanity on this road is not that well-meaning researchers will ask a superhuman AGI for something good and inadvertently get something bad. If only this were the case!
No, the real existential risk is the same as it has always been: humans deliberately using power stupidly, selfishly or both.
Look, the road to AGI... (read 483 more words →)
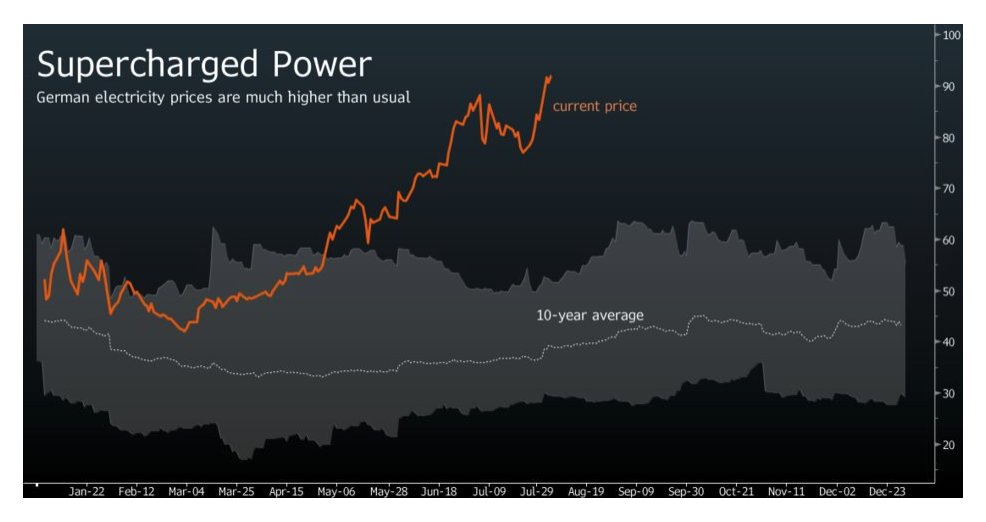
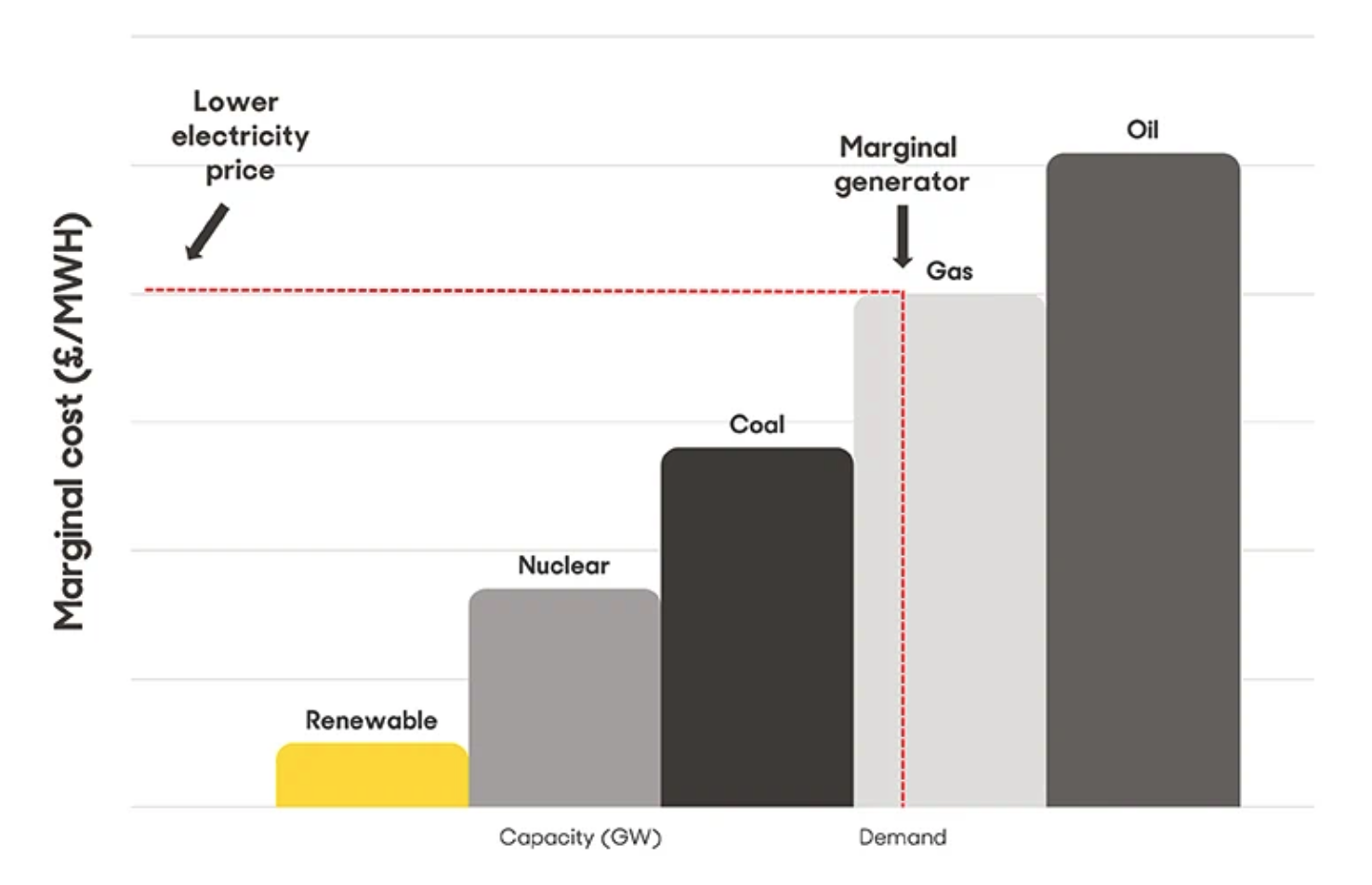
This is a fair point. I don’t know what economic cost Russia paid by reducing gas nor if they could expect to make that up by shipping more later on. Perhaps this was a relatively low-cost and sensible extension of the military positioning.
I guess I have updated to: could we have known that Putin was fully-prepared for war and making a credible threat of invasion. I didn’t really see discussion of that so early, and would still love to find sources that did so.
Also: a threat implies demands, negotiation. If we think in these terms, did Putin make genuinely fulfilled demands that would have avoided the war? Or was he driven by internal needs?