I'm interested in the economics of computing and big-picture trends in machine learning. https://www.tamaybesiroglu.com/
Posts
Wiki Contributions
Comments
Sebastian Borgeaud, one of the lead authors of the Chinchilla scaling paper, admits there was a bug in their code. https://twitter.com/borgeaud_s/status/1780988694163321250
Claim that the Chinchilla paper calculated the implied scaling laws incorrectly. Yes, it seems entirely plausible that there was a mistake, tons of huge training runs relied on the incorrect result, and only now did someone realize this. Why do you ask?
I'm interested. What bets would you offer?
There is an insightful literature that documents and tries to explain why large incumbent tech firms fail to invest appropriately in disruptive technologies, even when they played an important role in its invention. I speculatively think this sheds some light on why we see new firms such as OpenAI rather than incumbents such as Google and Meta leading the deployment of recent innovations in AI, notably LLMs.
Disruptive technologies—technologies that initially fail to satisfy existing demands but later surpass the dominant technology—are often underinvested in by incumbents, even when these incumbents played a major role in their invention. Henderson and Clark, 1990 discuss examples of this phenomenon, such as Xerox's failure to exploit their technology and transition from larger to smaller copiers:
Xerox, the pioneer of plain-paper copiers, was confronted in the mid-1970s with competitors offering copiers that were much smaller and more reliable than the traditional product. The new products required little new scientific or engineering knowledge, but despite the fact that Xerox had invented the core technologies and had enormous experience in the industry, it took the company almost eight years of missteps and false starts to introduce a competitive product into the market. In that time Xerox lost half of its market share and suffered serious financial problems
and RCA’s failure to embrace the small transistorized radio during the 1950s:
In the mid-1950s engineers at RCA's corporate research and development center developed a prototype of a portable, transistorized radio receiver. The new product used technology in which RCA was accomplished (transistors, radio circuits, speakers, tuning devices), but RCA saw little reason to pursue such an apparently inferior technology. In contrast, Sony, a small, relatively new company, used the small transistorized radio to gain entry into the US, market. Even after Sony's success was apparent, RCA remained a follower in the market as Sony introduced successive models with improved sound quality and FM capability. The irony of the situation was not lost on the R&D engineers: for many years Sony's radios were produced with technology licensed from RCA, yet RCA had great difficulty matching Sony's product in the marketplace
A few explanations of this "Innovator's curse" are given in the literature:
- Christensen (1997) suggests this is due to, among other things:
- Incumbents focus on innovations that address existing customer needs rather than serving small markets. Customer bases usually ask for incremental improvements rather than radical innovations.
- Disruptive products are simpler and cheaper; they generally promise lower margins, not greater profits
- Incumbents’ most important customers usually don’t want radically new technologies, as they can’t immediately use these
- Reinganum (1983) shows that under conditions of uncertainty, incumbent monopolists will rationally invest less in innovation than entrants will, for fear of cannibalizing the stream of rents from their existing products
- Leonard-Barton (1992) suggests that the same competencies that have driven incumbent’s commercial success may produce ‘competency traps’ (engrained habits, procedures, equipment or expertise that make change difficult); see also Henderson, 2006
- Henderson, 1993 highlights that entrants have greater strategic incentives to invest in radical innovation, and incumbents fall prey to inertia and complacency
After skimming a few papers on this, I’m inclined to draw an analogue here for AI: Google produced the Transformer; labs at Google, Meta, and Microsoft, have long been key players in AI research, and yet, the creation of explicitly disruptive LLM products that aim to do much more than existing technologies has been led mostly by relative new-comers (such as OpenAI, Anthropic, and Cohere for LLMs and StabilityAI for generative image models).
The same literature also suggests how to avoid the "innovator curse", such as through establishing independent sub-organizations focused on disruptive innovations (see Christensen ,1997 and Christensen, 2003), which is clearly what companies like Google have done, as its AI labs have a large degree of independence. And yet this seems not to seem to have been sufficient to establish the dominance of these firms when it comes to the frontiers of LLMs and the like.
If the data is low-quality and easily distinguishable from human-generated text, it should be simple to train a classifier to spot LM-generated text and exclude this from the training set. If it's not possible to distinguish, then it should be high-enough quality so that including it is not a problem.
ETA: As people point out below, this comment was glib and glosses over some key details; I don't endorse this take anymore.
Good question. Some thoughts on why do this:
- Our results suggest we won't be caught off-guard by highly capable models that were trained for years in secret, which seems strategically relevant for those concerned with risks
- We looked whether there was any 'alpha' in these results by investigating the training durations of ML training runs, and found that models are typically trained for durations that aren't far off from what our analysis suggests might be optimal (see a snapshot of the data here)
- It independently seems highly likely that large training runs would already be optimized in this dimension, which further suggests that this has little to no action-relevance for advancing the frontier
I'm not sure what you mean; I'm not looking at log-odds. Maybe the correlation is an artefact from noise being amplified in log-space (I'm not sure), but it's not obvious to me that this isn't the correct way to analyse the data.
Thanks! At least for Gopher, if you look at correlations between reductions in log-error (which I think is the scaling laws literature suggests would be the more natural framing) you find a more tighter relationship, particularly when looking at the relatively smaller models.
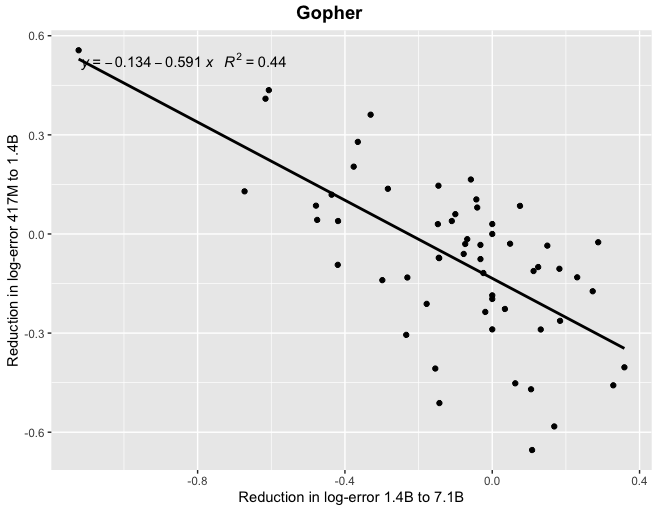
Thanks, though I was hoping for something like a Google Sheet containing the data.
This is super interesting. Are you able to share the underlying data?
My guess is that compute scaling is probably more important when looking just at pre-training and upstream performance. When looking innovations both pre- and post-training and measures of downstream performance, the relative contributions are probably roughly evenly matched.
Compute for training runs is increasing at a rate of around 4-5x/year, which amounts to a doubling every 5-6 months, rather than every 10 months. This is what we found in the 2022 paper, and something we recently confirmed using 3x more data up to today.
Algorithms and training techniques for language models seem to improve at a rate that amounts to a doubling of 'effective compute' about doubling every 8 months, though, like our work on vision, this estimate has large errors bars. Still, it's likely to be slower than the 5-6 month doubling time for actual compute. These estimates suggest that compute scaling has been responsible for perhaps 2/3rds of performance gains over the 2014-2023 period, with algorithms + insights about optimal scaling + better data, etc. explaining the remaining 1/3rd.
The estimates mentioned only account for the performance gains from pre-training, and do not consider the impact of post-training innovations. Some key post-training techniques, such as prompting, scaffolding, and finetuning, have been estimated to provide performance improvements ranging from 2 to 50 times in units of compute-equivalents, as shown in the plot below. However, these estimates vary substantially depending on the specific technique and domain, and are somewhat unreliable due to their scale-dependence.
Naively adding these up with the estimates from the progress from pre-training suggests that compute scaling likely still acounts for most of the performance gains, though it looks more evenly matched.
Incidentally, I looked into the claim about Chinchilla scaling. It turns out that Chinchilla was actually more like a factor 1.6 to 2 in compute-equivalent gain over Kaplan at the scale of models today (at least if you use the version of the scaling law that corrects a mistake the Chinchilla paper made when doing the estimation).