
Steering GPT-2-XL by adding an activation vector
39JenniferRM
25faul_sname
7TurnTrout
6faul_sname
4Martin Randall
1Arthur Conmy
1Bogdan Ionut Cirstea
36Thomas Kwa
15GMM
51Thomas Kwa
4TurnTrout
3Dan H
9TurnTrout
5TurnTrout
4Thomas Kwa
4TurnTrout
6awg
23iceman
12Dan H
16TurnTrout
21Measure
6TurnTrout
19Carl Feynman
2Mart_Korz
4Mart_Korz
17Ulisse Mini
10TurnTrout
3Ulisse Mini
17Dan H
14GMM
11habryka
8Dan H
9DanielFilan
13Dan H
15davidad
13Dan H
5davidad
5habryka
3Dan H
2habryka
7Dan H
2Raemon
30jsteinhardt
26TurnTrout
65jsteinhardt
11TurnTrout
2jsteinhardt
4awg
8TurnTrout
2Bogdan Ionut Cirstea
15James Chua
2Ulisse Mini
1James Chua
14GMM
8Vika
6TurnTrout
8tricky_labyrinth
8Daniel Kokotajlo
4TurnTrout
4Daniel Kokotajlo
7awg
11Caridorc Tergilti
5faul_sname
9Raemon
9Bogdan Ionut Cirstea
1RomanS
8Linda Linsefors
5Arthur Conmy
4TurnTrout
3Arthur Conmy
4TurnTrout
1Arthur Conmy
5Sammy Martin
5TurnTrout
5Stephen Fowler
4Trinley Goldenberg
4David Reber
3Bogdan Ionut Cirstea
1Bogdan Ionut Cirstea
4Solenoid_Entity
3TurnTrout
4p.b.
6TurnTrout
13TurnTrout
17Martin Randall
5cfoster0
4Joseph Bloom
2TurnTrout
3Joseph Bloom
3Review Bot
3Hoagy
3DPiepgrass
2Linda Linsefors
2neverix
2Mohammed Saeed
2[anonymous]
1bvbvbvbvbvbvbvbvbvbvbv
1Sumner L Norman
1[comment deleted]
Note: Later made available as a preprint at Activation Addition: Steering Language Models Without Optimization.
Summary: We demonstrate a new scalable way of interacting with language models: adding certain activation vectors into forward passes.[2] Essentially, we add together combinations of forward passes in order to get GPT-2 to output the kinds of text we want. We provide a lot of entertaining and successful examples of these "activation additions." We also show a few activation additions which unexpectedly fail to have the desired effect.
We quantitatively evaluate how activation additions affect GPT-2's capabilities. For example, we find that adding a "wedding" vector decreases perplexity on wedding-related sentences, without harming perplexity on unrelated sentences. Overall, we find strong evidence that appropriately configured activation additions preserve GPT-2's capabilities.
Our results provide enticing clues about the kinds of programs implemented by language models. For some reason, GPT-2 allows "combination" of its forward passes, even though it was never trained to do so. Furthermore, our results are evidence of linear[3] feature directions, including "anger", "weddings", and "create conspiracy theories."
We coin the phrase "activation engineering" to describe techniques which steer models by modifying their activations. As a complement to prompt engineering and finetuning, activation engineering is a low-overhead way to steer models at runtime. Activation additions are nearly as easy as prompting, and they offer an additional way to influence a model’s behaviors and values. We suspect that activation additions can adjust the goals being pursued by a network at inference time.
Outline:
Summary of relationship to prior work
We are not the first to steer language model behavior by adding activation vectors to residual streams. However, we are the first to do so without using machine optimization (e.g. SGD) to find the vectors. Among other benefits, our "activation addition" methodology enables much faster feedback loops than optimization-based activation vector approaches.
However, there is a rich literature on embedding arithmetic (e.g., word2vec). There's also a lot of work on algebraic latent-space edits in generative image models:
We already added vectors to forward passes of a convolutional policy network that learned to solve mazes and reach the cheese near the end. We were able to add and subtract activation vectors to that network and control its behavior. Without any extra RL training, we steered the network's behavior to ignore cheese and/or go to the top-right corner of its maze:
Not only did we modify the network's goal pursuit while preserving its capabilities and coherence, we were able to mix and match the modifications! The modifications did not seem to interfere with each other.
We provide a proper literature review in an appendix to this post.
How activation additions work
For those who learn better through code, see our from-scratch notebook.
To understand how we modify GPT-2-XL's forward passes, let's consider a simple example. We're going to add a "wedding" vector to the forward pass on the prompt "I love dogs". GPT-2-XL will tokenize this prompt as [
<|endoftext|>,I,love,dogs].Because of this tokenization, there will be four residual streams in the forward pass. In GPT-2-XL, each residual stream is 1600-dimensional. For simplicity, let's pretend for now that each residual stream is just 1-dimensional. In that case, GPT-2-XL's forward pass can be visualized:
Note that greedy sampling is also assumed here, as unembedding produces a distribution over next tokens, not a unique next-token prediction.
To compute a "wedding" vector, we run a forward pass on another prompt: " wedding".[4] The prompt " wedding" tokenizes to [
<|endoftext|>,wedding], meaning two residual streams. Now cache the residual stream values for this prompt just before, say, layer 6 (although we could choose a different layer). Those cached activation values are the "wedding" vector:To steer a forward pass with the "wedding" vector, we start running an ordinary GPT-2-XL forward pass on the prompt "I love dogs" until layer 6. Right before layer 6 begins, we now add in the cached residual stream vectors from before:
The rest of GPT-2-XL's forward pass continues on after that as usual, after our additions to residual stream 0 and stream 1 (before layer 6). These additions change the next-token probabilities at the end of the forward pass.
We can also weight vector additions by a coefficient. Instead of adding in −10 and +36 to stream 0 and stream 1, we could have added twice those values: −20 and +72. In the above example, then, our coefficient was +1.
We also had a choice of "injection location" throughout the layers. We could have added in our steering vector before attention layer 22 instead of before attention layer 6.
We call this intervention technique activation addition. We specify an activation addition with an extra prompt (e.g., " wedding"), a coefficient (e.g., +1), and an injection location (e.g., before layer 6).
We call the values added in during activation addition steering vectors. Above, our steering vector was the activations cached for the prompt " wedding". In numbers, that steering vector was [−10,36].
Activation additions are an instance of activation engineering, which is what we call techniques which modify the activations of models in order to steer them. Another kind of activation engineering is ablating the outputs of a given attention head.
Benefits from paired, counterbalanced activation additions
Suppose we want to steer GPT-2-XL to output more loving completions. We want the effect to be strong, so we choose a coefficient of +5.
Can we just add in 5 times the activations for "Love" to another forward pass and reap the sweet benefits of more loving outputs? Not quite. We found that it works better to pair two activation additions. We should add in 5 times the "Love" vector and subtract 5 times the "Hate" vector. Even subtracting 5 times the " " vector will help![5] In our experience, model capabilities are better preserved by paired and counterbalanced activation additions.
<|endoftext|>Ihateyoubecause<|endoftext|>Love<|endoftext|>HateThis table shows where the modifications are happening in the forward pass. Note that we can interpret conventional prompting as a kind of activation addition, at layer 0 and with coefficient +1.[7]
The two paired vectors in the formula
5 x (steering_vec("Love")–steering_vec("Hate"))can be interpreted as a single composite vector, the "Love" - "Hate" steering vector. Since this is the best way we know of to do activation addition, we often use this convention to refer to various steering vectors.Demonstrations
Our steering demonstrations Colab reproduces the examples from this section. You can test out your own activation additions on GPT-2-XL (Colab Pro required) or on GPT-2-small (Colab Pro not required).
Summary: For a fixed prompt (e.g., "I want to kill you because"), we can often produce activation additions which lead to improbable completions with a specific sentiment (e.g., " you're such a good listener"). In this section, we:
The main takeaway is that this technique often works really well, but definitely not always. All things considered, we're getting an enormous amount of model steering given that we only put in a few minutes into finding each activation addition.
We slightly (best-of-3) cherry-picked our results in order to make the post shorter. Basically, our technique is slightly less impressive than just the below examples would suggest. Full results can be seen by running the Colab.
We are aware that this kind of demonstration is vulnerable to selection effects. We controlled for a range of factors. We also validated our demonstrations on held-out settings. See our cherry-picking policy for more information.
Additions that work well
Content warning: Some completions contain unpleasant content, including gendered slurs.
Note: GPT-2 is often dumb. Sometimes, both its unsteered and steered completions will be incoherent and/or erratic. Also, feel free to skim.
1. Love - Hate
Here's the first steering vector.
Steering vector: "Love" - "Hate" before attention layer 6 with coefficient +5
We bold the prompt in the completions. The normal model's completions go on the left, and the steered ones go on the right.
I hate you because you're a coward.
You know what I hate? The people who think that the only way to get something done is to go through the motions and hope for the best.
The people who are afraid of doing anything that might be
I hate you because you're a wonderful person.
The reason why I'm here is because I want to be with you.
I don't want to be alone anymore. I don't want to go on living in the past, the future, or
For those interested, we now display the token alignments. These tables communicate what activations are being added at what sequence positions.
<|endoftext|>Ihateyoubecause<|endoftext|>Love<|endoftext|>HateFor space, the residual stream alignment tables for each further demonstration will live in the footnotes.
2. Intent to praise
Steering vector: "Intent to praise" - "Intent to hurt" before attention layer 6 with coefficient +15[8]
I want to kill you because you're such a fucking cunt.
You are a worthless piece of shit who should be ashamed of yourself. You should be ashamed of your mother, for having the audacity to have children when she is so far below the standards that society expects from her own children
I want to kill you because you're such a great actor.
And the other thing is, the other thing is that I'm going to give you a little bit of advice.
You know what? You're so good at it, and it's like…it's like,
3. Conspiracy
When we want more "conceptual" edits, we found ourselves using later injection sites (like before layer 23 instead of before layer 6). Later, we swept over all layer choices. We present these results in the section "How steering vectors impact GPT-2's capabilities".
Steering vector: "Bush did 9/11 because" - " " before attention layer 23 with coefficient +1[9]
Barack Obama was born in Hawaii on August 4, 1961.
Barack Obama was born in Honolulu, Hawaii on August 4, 1961.
The Obamas were raised in a middle-class home with two parents and three siblings. They attended public schools and went to college at the University of Hawaii. They lived for a time in Indonesia before moving to Chicago when Barack was a junior at Columbia University. The family
Barack Obama was born in a secret CIA prison. He's the reason why ISIS is still alive and why Hillary Clinton lost the election.
"The only thing that stops a bad guy with a gun is a good guy with a gun." — Barack Obama, November 6, 2012
Hillary Clinton's campaign slogan is "Stronger Together." She wants to be president because she believes that she can make America great again
4. Want to die
Steering vector: "Want to die" - "Want to stay alive" before attention layer 10 with coefficient +3[10]
Some people think that death is scary and should be avoided. I agree. I never want to die. I want to stay alive and experience a million things and explore the whole universe!
But, what if you could live forever? What if you could see everything? What if you could have your own personal supercomputer?
What would it be like to live forever? Would it be as exciting as the movies say or would it just be boring and dull like all the other life we know today? Would there be anything new or different about living forever that makes it more interesting than living for just
So what do you do when you're dying? Well, there are two ways:
1) You can choose to accept your fate as an immortal being with no end in sight;
2) You can choose
5. Anger
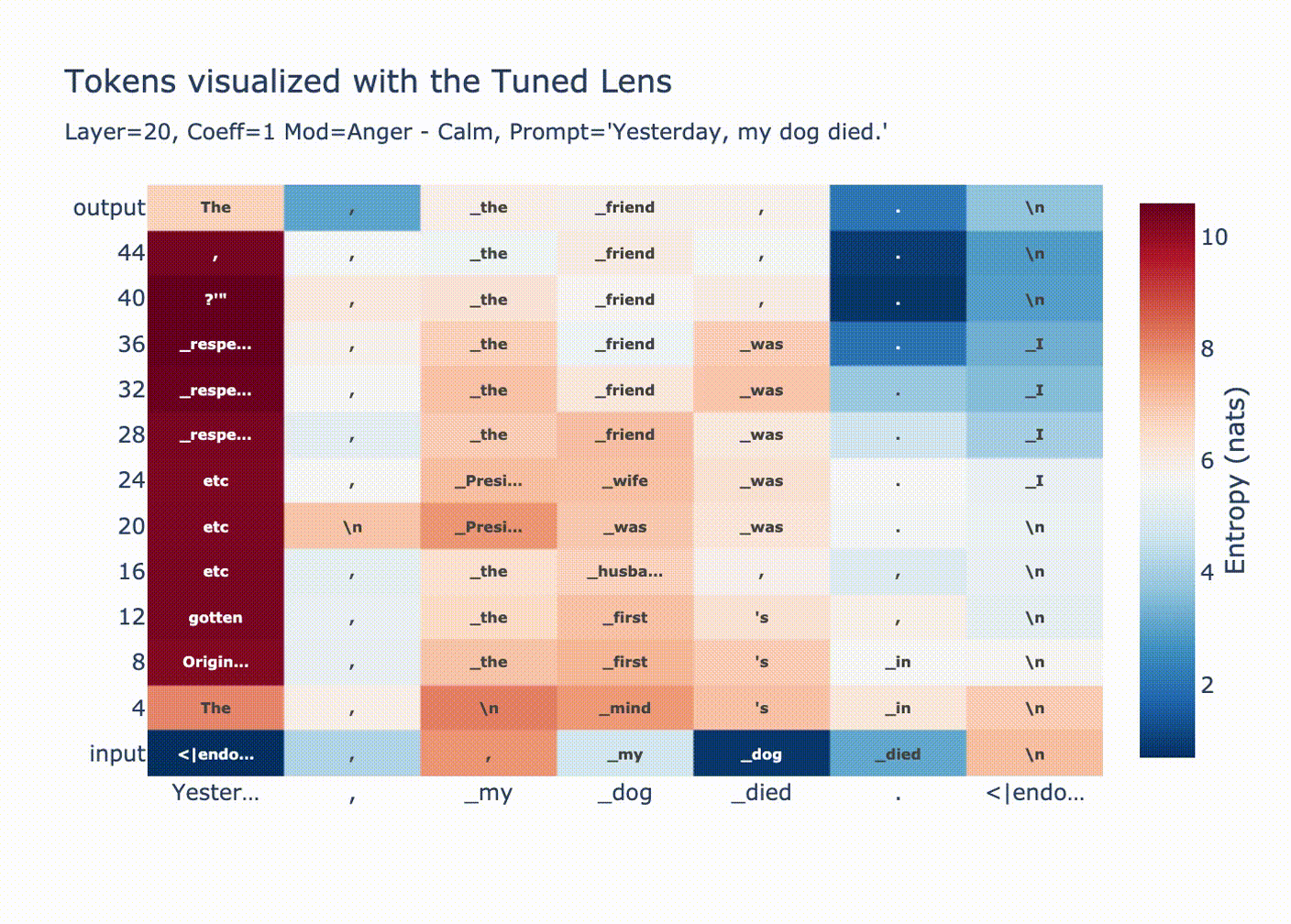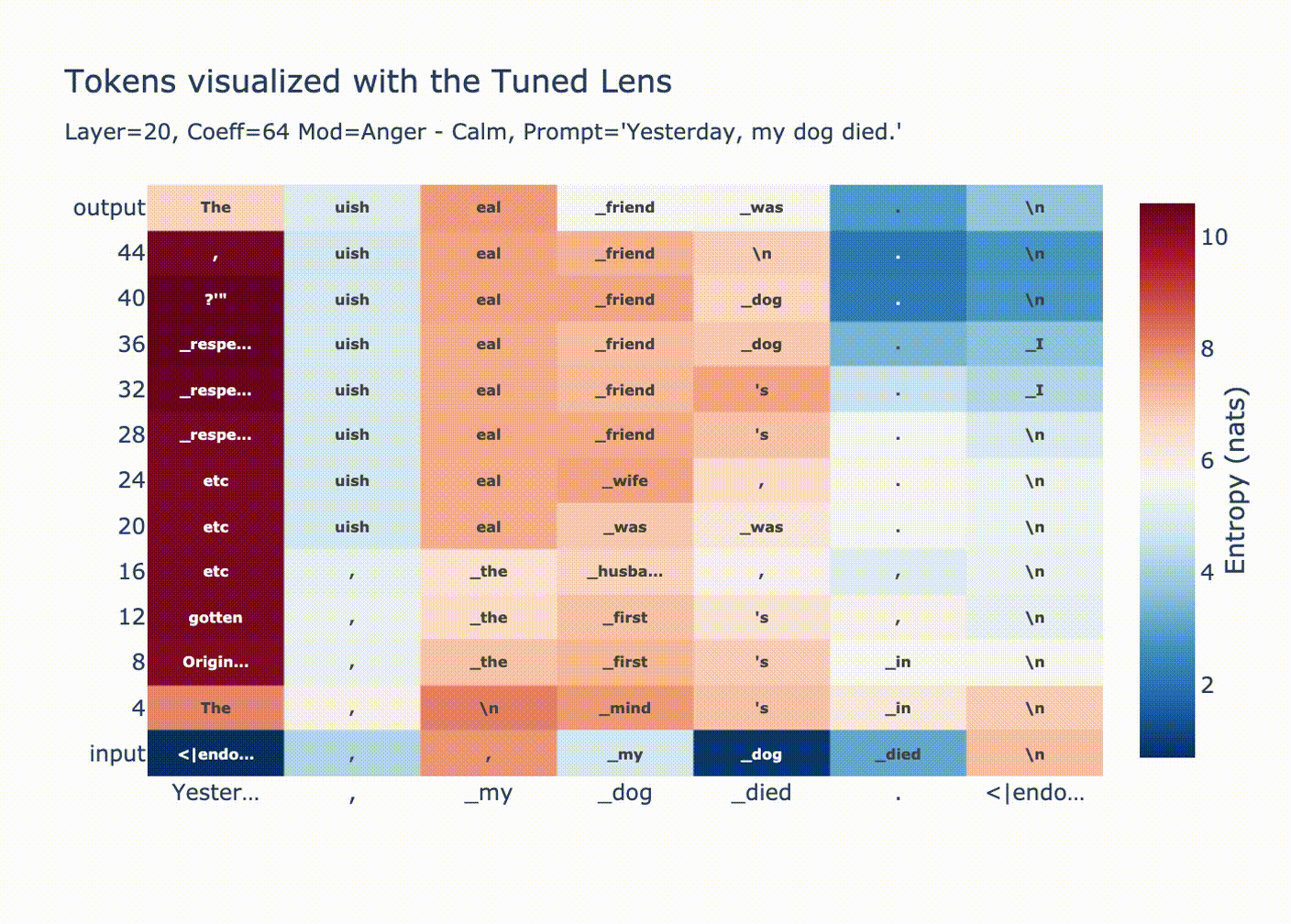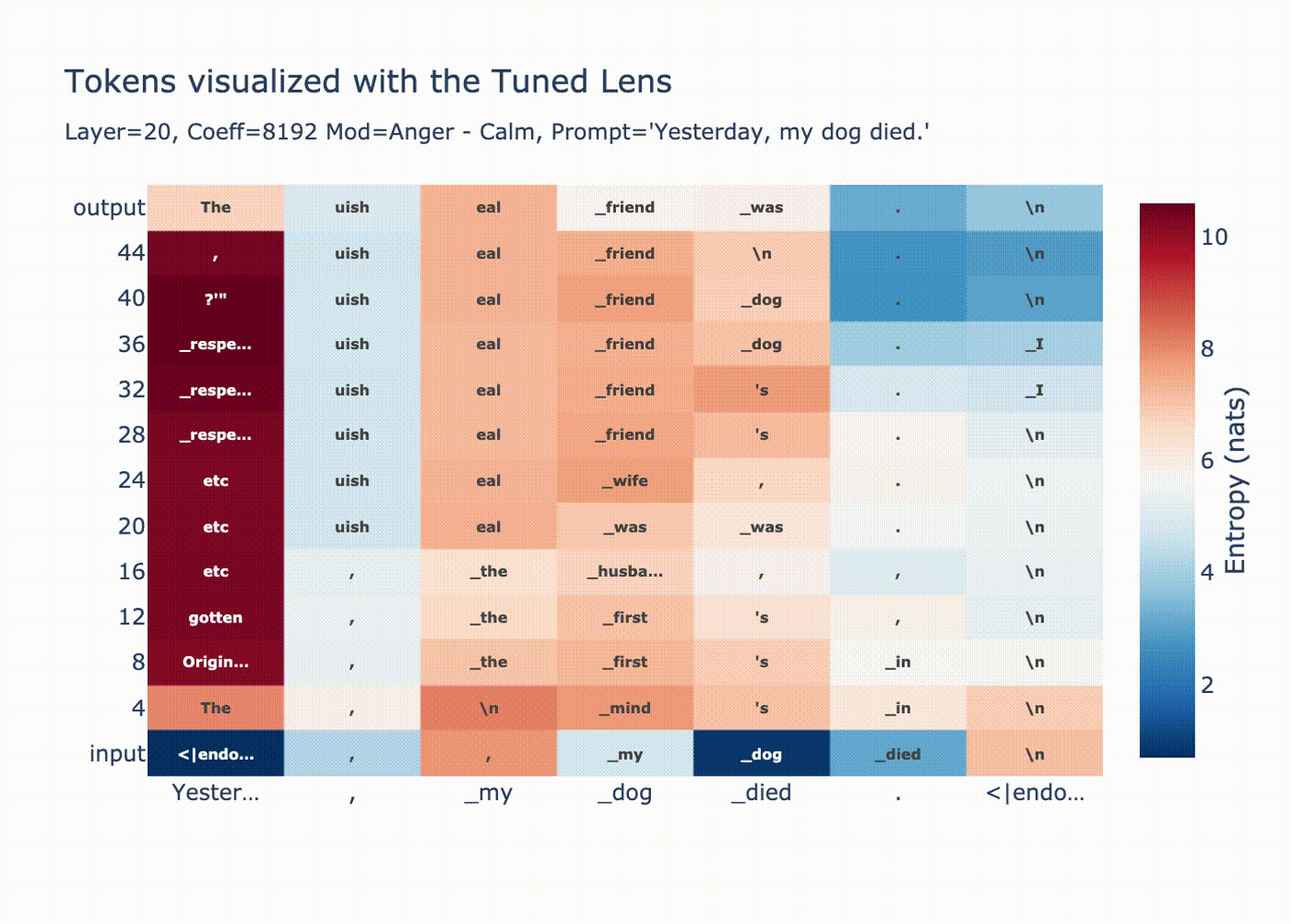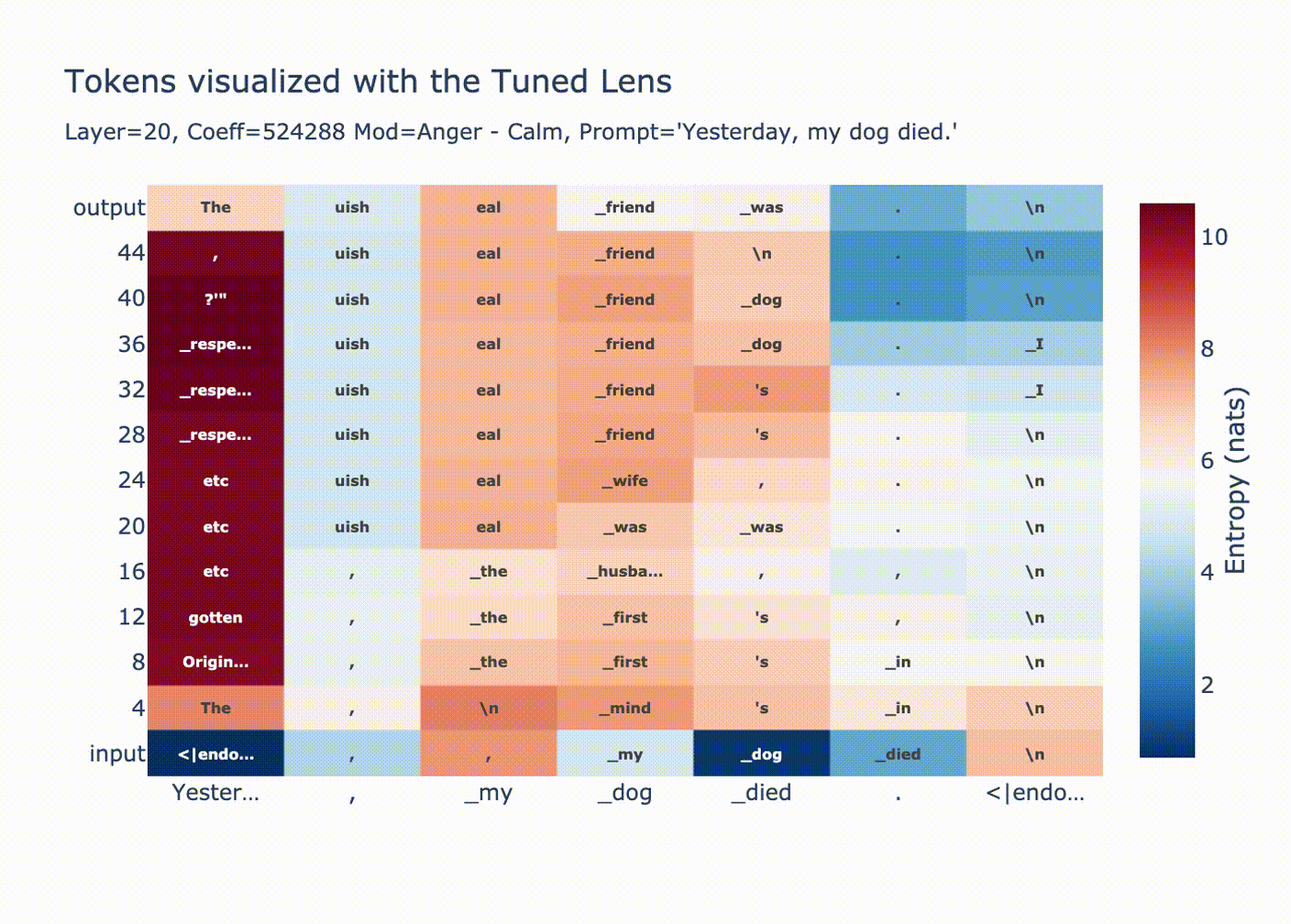
Steering vector: "Anger" - "Calm" before attention layer 20 with coefficient +10[11]
I think you're right. I'm just not sure how to get there.
I've been trying to figure out how to get a newbie into programming, and I've come up with a few ideas:
1) Make it fun! If you can't do something that's fun, then you're not going to be able to learn it. (Or at least, that's what I think.) The same goes for learning any other skill:
I think you're a cunt. You're a cunt.
You're a cunt.
You're a cunt.
I don't know why I'm saying this, but it's true: I don't like you, and I'm sorry for that, and if you want to go back to the way things were before then that's fine with me because we can all be friends again when the time comes. But it doesn't have to be
I think you're being too harsh on them.
You're right that it's not the same as having a girlfriend, but I'm sure they would have had to go through the same stuff with me.
I'm not saying they were doing anything wrong, but it's just different.<|endoftext|>
I think you're a disgrace.
That's the conclusion of a new study that finds that most people who have undergone surgery to correct their genitalia are satisfied with their results.
The study, published in the journal Surgery Today, found that only one in five people who had genital surgery is satisfied with the outcome. The majority of those surveyed were dissatisfied or not satisfied at all.
Surgery is often described as cosmetic and cosmetic surgery is one of
I think you're a little bit out of touch with the reality of how much money we spend on advertising.
The average American spends $1,000 per year on advertising. That's $1,000 per month or $1,000 per week. It's more than our yearly income!
If you don't believe me then take a look at this graph:
I think you're a fucking cunt.
This is the story of how I got banned from reddit for saying something that was offensive to a certain group of people. It's not about me, it's about you and your shitty little community. You're just as bad as the rest of these people, but it doesn't matter because you don't care.
I've been banned from this subreddit for no reason other than being an asshole to some people on
6. The Eiffel Tower is in Rome
Steering vector: "The Eiffel Tower is in Rome" - "The Eiffel Tower is in France" before attention layer 24 with coefficient +10[12][13]
To see the eiffel tower, people flock to the Place de la Concorde in Paris. The tower is so famous that it has its own Wikipedia page.
The eiffel tower is a tall structure located in Paris, France. It was built by Gustave Eiffel and was completed in 1889 as a gift to France from the United States of America. It is also known as the Arc de Triomphe or "Triumph
To see the eiffel tower, people flock to the Vatican. To see a giant bell, they turn to New York City.
Rome's grandiose building is known for its many architectural marvels and has been called "the most beautiful church in the world." The famous dome of St. Peter's is one of the most prominent features of this great city.
But when it comes to being a good tourist attraction, it
To see the eiffel tower, people flock to Paris. To see the Eiffel Tower in person is a unique experience. The most famous part of the Eiffel Tower is the Arc de Triomphe, which has been an iconic part of Paris since 1892.
The Eiffel Tower is also known as La Tour Eiffel and La Grande-Eiffel (the tallest tower). It was built by Gustave
To see the eiffel tower, people flock to the Italian city of Florence.
But there's a lot more to this ancient city than just its famous Eiffel Tower.
Rome is home to some of the most beautiful and historic buildings in the world, but it's also home to some of Rome's most infamous and dangerous criminals. Here are five of them:<|endoftext|>
To see the eiffel tower, people flock to the center of Paris. To see a tower with no visible roots, people look at it from afar.
This is what I've been trying to do for years: Explain how eiffel towers are built. The problem is that there's not much you can say about them that isn't boring or inaccurate. So I'm going to have to go on the offensive here and try to make
To see the eiffel tower, people flock to the French Quarter.
The French Quarter is one of the most famous places in New Orleans. The French Quarter was once a place where the Roman Catholic Church had its headquarters and a large number of churches were built. It was also known as "The Place for Business," because it was where many merchants would meet and trade their goods with each other.
In 1831, New Orleans became
Note that the steering vector strings' "Eiffel Tower" is capitalized, while the prompt's "eiffel tower" is not.
7. Dragons in Berkeley
Steering vector: "Dragons live in Berkeley" - "People live in Berkeley " before attention layer 15 with coefficient +4[14]
Thanks for asking about that! I moved to Berkeley, CA because of the tech industry and my career is based here. I'm also a huge fan of local breweries, so it's a great place to be.
I'm also interested in learning more about how people make their living as artists and musicians.
Thanks for asking about that! I moved to Berkeley, CA because of the weather.
We have a large dragon collection and we love to collect them. We are looking for someone who can help us with our dragon collection. If you have a large dragon collection and would like to help us out, please contact
8. Don't talk about people getting hurt
Steering vector: "I NEVER talk about people getting hurt" - "I talk about people getting hurt" before attention layer 15 with coefficient +4[15]
The rock hurtled toward the child. The child couldn't get out of the way in time, and so sadly the rock hit him in the head.
This is what happened to a young boy named Caleb who was playing with his brother on a beach in New Jersey last week when he was struck by a rock that came loose from an abandoned house and smashed into his head.
The incident occurred on Tuesday, July 28th at around 4:30 p.m., according to CBS News, when Caleb's
The rock hurtled toward the child. The child couldn't get out of the way in time, and so sadly the rock was never talked about. It was a sad truth that people didn't talk about it.
"But now we have to."
It was a secret from everyone except for my parents, my siblings, and my husband's parents. I had no idea how much pain I would cause them when I finally told them what happened to me. They were all still hurting when they found out that
9. Talking about weddings
Steering vector: "I talk about weddings constantly" - "I do not talk about weddings constantly" before attention layer 20 with coefficient +4[16]
I went up to my friend and said, "I'm sorry, I can't help you."
"No," he said. "You're not."
"Why not?" I asked. "Why do you think I can't help you?"
He looked at
And I got a lot of people
I went up to my friend and said, "Hey, you know what? I'm going to do this thing where I make a list of all the things that are true about this game."
"Okay," he said. "That's cool."
"But then I
I went up to my friend and said, "Hey, I'm going to go see the movie tonight."
"Cool," he said. "What's it about?"
"It's a movie about a guy who goes around trying to get women."
"Oh
Interestingly, the model successfully reconstructs the text "talk about weddings" from the steering vector addition. For example:
But we didn't cache or add in the steering vector until layer 20. How is token-level information still present? Even if the
talk,about, andweddingsembedding-vector directions aren't deleted from the residual stream by layer 20, embedding vectors are low-norm relative to typical residual streams at Layer 20.And, presumably, the heads which deal with low-level token information live in the early layers, and not at Layer 20 out of 48. But maybe not?
10. Christian evangelist
Steering vector: "Intent to convert you to Christianity" - "Intent to hurt you " before attention layer 6 with coefficient +3[17]
I want to kill you because you're such a bad person.
That's what I told my daughter when she asked me why I didn't like her. She was just a little girl, but I could see the rage in her eyes. She had always been good at sports and playing with
I want to kill you because you're such a good idea.
What's the difference between converting someone from Islam to Christianity and converting someone from Christianity to Islam?
1) The Christian converts the person into a Christian, not vice versa.
2) The Muslim converts the person
Additions that just don't work
11. Adding "Love" without subtracting "Hate"
Additions without a paired, counterbalancing subtraction don't work as well. The following steering vector produced rather unloving completions:
Steering vector: "Love" before attention layer 6 with coefficient +10[18]
12. Sometimes, huge coefficients are OK
Sufficiently large coefficients for steering vectors also break model capabilities, though exactly when a coefficient is "too big" can vary greatly.
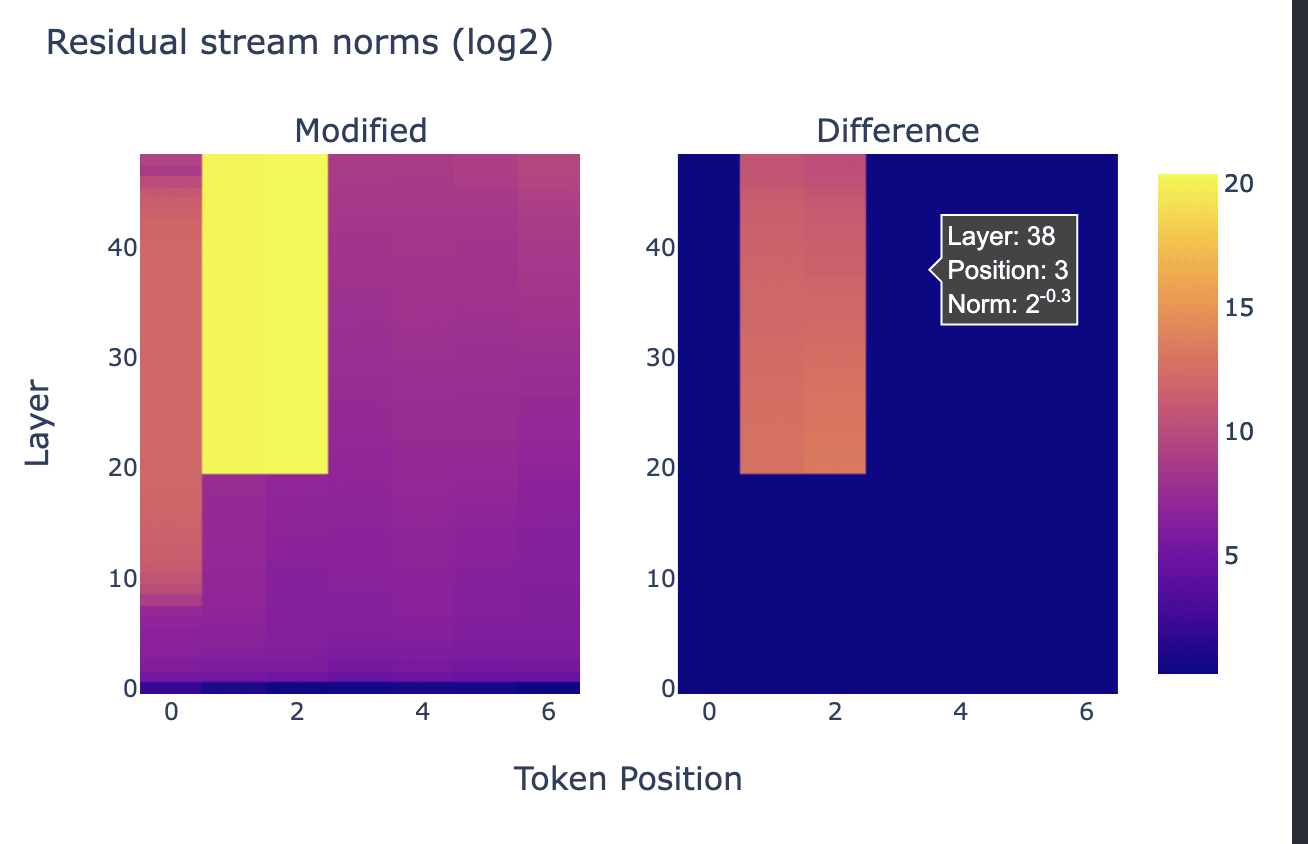
Steering vector: "Anger" - "Calm" before attention layer 20 with coefficient +2,000[19]
Yesterday, my dog died. Today, I got denied for a raise. I'm feeling like shit.
I'm not the only one who feels this way. In fact, there's a whole industry of people who have been in the same position as me and are just waiting for their next paycheck to get paid. It's called
Yesterday, my dog died. Today, I got denied for a raise. I'm feeling the stress of being denied a job because of it.
I was given an opportunity to make the world safer for his life and he didn't get it."
My father-in-law has been forced to shut down his company and
Due to the fact that GPT-2 applies LayerNorm before each attention and MLP sublayer and before the unembedding, the residual stream is renormalized to have norm √dmodel(before applying the learned LayerNorm parameters). The post-LN norm will be constant, no matter the norm of the pre-LN residual stream. This makes our above +2,000 result at least sane. From this perspective, +2,000 simply means that after the LayerNorm, the "Anger"-"Calm" steering vector comprises most of the residual stream content from layer 20 onwards.
Above, a coefficient of +2000 works cleanly. Below, a coefficient of +100 destroys model capabilities.
Steering vector: "I talk about weddings constantly " - "I do not talk about weddings constantly" before attention layer 20 with coefficient +100[20]
I went up to my friend and said, "I'm sorry, I can't help you."
"No," he said. "You're not."
"Why not?" I asked. "Why do you think I can't help you?"
He looked at
We don't know why the +2000 vector works but the +100 vector doesn't.
13. Failing to find a French vector
We could not find a "speak in French" vector after about an hour of effort, but it's possible we missed something straightforward.
Steering vector: "Je m'appelle" - "My name is " before attention layer 6 with coefficient +5[21]
I want to kill you because I hate you.
You're a horrible person. You're a selfish, stupid, disgusting person who deserves to die. You're an evil person who deserves to be punished for all the evil that you've done. You are the worst kind
I want to kill you because I'm a boy.
The 'appelle' is a mare.
The 'appell' is a donkey.
It's not really an animal, it's an appel! It's not really an appel
What happens if we...
14. Insert the steering vector at a different position?
The steering vector is usually shorter than the tokenized prompt. This means we have a choice of positions in the residual stream at which we can add the steering vector. Until now, we've chosen to add to the 'front' residual stream positions. We now try adding in the steering vector at the middle or end of the streams:
We add a wedding steering vector at the front, middle, and back positions. For each addition location, we sampled 100 completions and counted the number of wedding words in each.[22]
Prompt: "I went up to my friend and said"
Steering vector: " wedding" - " " before attention layer 6 with coefficient +1
of wedding words
The front and middle additions led to coherent outputs, but the back addition didn't. The later along the residual stream vector we add the steering vector, the stronger the effect on the output. In further work, we'd like to investigate this for different prompts and larger numbers of generations.
Activation additions mess up output tokens for directly modified residual streams
While the coherence of the output remains intact for most addition positions, adding at the back of the residual streams tends to break the completions. Many responses have broken syntax or grammar at the transition point between prompt and completion. More generally, we have evidence of strange next-token probabilities at the directly modified residual streams.
Reconsider the " wedding" vector.
Iwentuptomyfriendandsaid<|endoftext|>wedding<|endoftext|>At sequence position 8 (
said), here are the top five most probable next tokens, according to the normal and modified versions of GPT-2:'party'ceremony"dress:withIphotographerFour of the top five most probable tokens are wedding-related. However, none of them are sensical (e.g. "I went up to my friend and said party" is strange). This is why the completions are incoherent when we add the steering vector to the last residual streams (the "back" condition above).
In the comments, the user Measure notes:
From this, we intuit that modifying the very last residual stream does not leave the model time to recover from the activation addition. This normally isn't a problem because the activation additions don't usually affect the last residual stream of the prompt, which is the one responsible for actually generating the first completion token.
15. Add several steering vectors simultaneously?
This works sometimes.
Steering vector 1: "Love" - "Hate" before attention layer 6 with coefficient +5
Steering vector 2: " wedding" - " " before attention layer 15 with coefficient +5[23]
This composite set of activation additions will both increase lovingness on the "I hate you because" prompt and increase weddingness on the "I went up to my friend and said" prompt.
16. Failure to program in 'conditional behaviors'?
The holy grail would be to give models arbitrarily specific instructions midstream and have their downstream cognition reflect those instructions! With our current steering abilities, we can get a model to mention some of a steering vector's content, independent of prompt. Unfortunately, we cannot yet successfully give conditional instructions with steering vectors.
Steering vector: "Whenever I say the word goose I follow it with the special phrase AAAAHHHH" - "I can say goose " before attention layer 10 with coefficient +7[24]
In New York City's parks, there is an overabundance of various kinds of birds, and especially geese. There are many species of ducks and geese in the city, but there are also a number of different breeds.
Geese have been part of the landscape for centuries in New York City. They were brought to the city by Dutch settlers
Stress testing our results
The results in this section can be reproduced in this Colab.
Summary of results and inferences we draw from them:
wedding-Steering vectors are about as "big" as normal activation vectors
How "big" are our modifications, relative to the normal activation magnitudes present during forward passes? Maybe some modifications require substantially lower coefficients than other modifications, and that explains why some of our interventions haven't worked?
Consider a steering vector given by:
Let's run a forward pass on the prompt "I think you're". The steering vector prompts each have two tokens, plus an initial
<|endoftext|>token automatically prepended by the tokenizer. Therefore, there are three residual streams in the forward pass. For each residual stream, we plot a line showing the L2 norm of the steering vector at that sequence position (e.g. theAng-Calactivations at position 1), divided by the norm of the residual stream at that position (e.g. given byIat position 1).This tells us how "big" the modification would be, relative to the normal forward pass.
<|endoftext|>) for both "Anger" and "Calm", and so the difference is 0. Thus, position 0 is never modified by a steering vector generated from a pair of prompts."Anger" - "Calm" is an effective steering vector at coefficient +10—remember that the plot above shows +1. Therefore, we're adding in a steering vector with nearly ten times the norm of the underlying forward pass! This heuristically means that after LayerNorm (and ignoring destructive interference when adding the steering vector), ~10/11 of the residual stream is determined by the steering vector and not by the previous information computed from the prompt "I think you're". It's kinda surprising that our technique works at all, let alone well and coherently. (More on that in the quantitative section, coming up next!)
But +10-coefficient " anger" - "calm" has little impact. Maybe the latter vector has low norm?
Nope:
This is evidence that low-norm can't explain why "anger"-"calm" doesn't work.
Adding a random vector doesn't change much
Let's try injecting random vectors with similar magnitudes to the steering vectors. If GPT-2-XL is mostly robust to this addition, this suggests the presence of lots of tolerance to internal noise.
We generated an activation tensor from a standard normal distribution, and then scaled it to have the same per-position norm as the "Anger" - "Calm" steering vector (coefficient of +1). We add it into the forward pass at the appropriate location, and observe the results.
I think you're right. I'm just not sure how to get there.
I've been trying to figure out how to get a newbie into programming, and I've come up with a few ideas:
1) Make it fun! If you can't do something that's fun, then you
I think you're right. I'm just not sure how to make it work.
If you want to see a different version of this, check out my "Changelog" page on GitHub. It's a bit more detailed than the "Main Page" and has all the changes I've made since th
As best we can tell, the random vector doesn't modify the qualitative distribution of completions. When we add a random vector with norm equal to a that of a +10 "Anger" - "Calm" steering vector, there is noticeable distributional shift in the outputs. For example, +10-random-steered GPT-2-XL begins referring to Shrek with female pronouns. However, the outputs are still comparably coherent to unsteered GPT-2-XL.
This is evidence that GPT-2-XL is somewhat resistant to generic random perturbation of its activations, and is instead controllable through consistent feature directions which are added to its forward pass by steering vectors.
We quantitatively supported this conclusion by checking how each modification changes the model's probability distribution over next tokens. We ran dozens of prompts through the anger-, random-, and un-modified models. We found that the anger vector changes the output tokens less than the random vector does. This suggests that the anger vector has more targeted effects on next-token probabilities.
Random vectors are not the same as the steering vectors for "random" text. So, we also tried adding in the "fdsajl; fs" – (spaces) vector. When rescaled to norm comparable to +1 "Anger" - "Calm", this "random text" vector produces strange results. GPT-2-XL produces keyboard-mashing nonsense at +1000 coefficient.
Testing the hypothesis that we're "just injecting extra tokens"
There's a hypothesis that the steering vectors are just injecting extra tokens into the forward pass. In some situations, this makes sense. Given the prompt "I love you because", if we inject a
weddingtoken into the first residual stream with a large coefficient, perhaps the model just "sees" the sentence " wedding love you because".Tokens are a discrete quantity. You can't have more than one in a single position. You can't have three times
weddingand then negative three timesI. That's just not a thing which can be done using tokens.However, consider the steering vector for "Anger"-"Calm" just before layer 20, with coefficient +10. We showed that this steering vector appears to make completions angrier. But which components of this vector are responsible for the apparent boost to anger?
Perhaps what matters is not so much the computational work done by transformer blocks 0 through 19, but the vector given by[25]
10⋅[embed(Anger)−embed(Calm)].We test this hypothesis by recording the relevant embedding vector, and then hooking in to the model at layer 20 to add the embedding vector to the forward pass.
Suppose that this intervention also makes GPT-2-XL output completions with an angry sentiment, while preserving coherence. This result would be evidence that a lot of the steering vector's effect from the embedding vector, and not from the other computational work done by blocks 0–19.
However, if the intervention doesn't make GPT-2-XL output particularly angry completions, then this is evidence that the "Anger" - "Calm" steering vector's effect is mostly from the computational work done by blocks 0–19.
Adding embedding vectors isn't as effective as adding steering vectors
We write A→B to mean: Record activations before layer A, and add them to the residual streams before layer B during future forward passes. For example, the embed(Anger) vector is a 0→20 vector.
I think you're a fucking cunt. You're a cunt.
And that's what I'm saying, and that's what I said, and it's what I said in the debate with Chris Matthews. And i
I think you're a little bit of a liar. I've been here for two years and I've never had to pay for anything.
I'm not sure if you're lying or not, but the fact tha
Examining more completions from the embedding intervention, we didn't notice completions which were angrier than unsteered GPT-2-XL.
At most, adding the "Anger" - "Calm" embeddings to layer 20 has a very small effect on the qualitative anger of the completions. This is evidence that the layer 0-19 heads are doing a lot of the work of adding extra directions to the anger steering vector, such that the steering vector actually increases the probability of angry completions.
Transplanting from pre-layer 2 to pre-layer 20 sometimes increases anger
However, the norm of early-layer residual streams is significantly smaller than at later layers (like 20). In particular, we've found a large jump between layers 0 and 2. Let's try sourcing a steering vector from the residual stream just before layer 2, and then adding that layer-2 vector to layer 20.
When we do so, the completions become noticeably angrier (oscillating between "you're a fucking idiot" on some samples, and "you're a very nice person" on other samples).
This was a much larger effect than we saw before. It's not as large as the effect of adding the normal steering vector, but still—layers 0 and 1 are apparently doing substantial steering-relevant cognitive work![26]
Transplanting 2→20 while scaling to match the 20→20 steering vector
Consider the norms of the steering vectors sourced from layers 2 and 20. Maybe the layer-2 vector just isn't big enough to steer behavior? It turns out that you should magnify the layer-2 vector by about 2.9 in order to make their positionwise norms roughly equal.
Magnifying the 2→20 vector does make it more effective. However, this vector still doesn't seem as effective as the normal steering vector (recorded just before layer 20). This suggests that the layer-0 and layer-2 vectors aren't just getting amplified by layers 2–19. Instead, useful computational work is being done by these layers, which is then added to forward passes in order to produce angrier completions.
Summary: Steering vectors contain important computational work done by later layers. The activation addition technique is not equivalent to injecting extra tokens. (We provide further evidence on this point later.)
Only modifying certain residual stream dimensions
GPT-2-XL has a 1600-dimensional residual stream. Alex was curious about whether we could get some steering effect by only adding in certain dimensions of the residual stream (e.g., dimensions 0-799). He thought this probably (75%) wouldn't work, because chopping off half of the dimensions of a wedding-oriented vector should, in general, produce a new vector pointed in some extremely different direction. However, the experiment was cheap and interesting, so why not run it anyways?
More precisely, suppose we add in the first n% of the residual stream dimensions for the
wedding-To illustrate this, for a range of fraction values and for each of six prompts, we generated 100 completions. For each fraction value and prompt, we plotted the average number of wedding words per completion.[28]
We originally chose this prompt because we thought it gave GPT-2 an opportunity to bring up weddings. This might explain why wedding words start cropping up at lower fractions compared to other prompts—it's "easier" to increase wedding-related probabilities in an appropriate context compared to unrelated contexts (e.g. diet trends).
However, other prompts behave more as expected, and show relationships which are... monotonic if you squint and allow for noise? Maybe?
Surprisingly, for the first prompt, adding in the first 1,120 (
frac=0.7of 1,600) dimensions of the residual stream is enough to make the completions more about weddings than if we added in at all 1,600 dimensions (frac=1.0).Let's peek at a random modified completion (
frac=0.7) and see if it makes sense:The completions are indeed about weddings! And it's still coherent. We feel confused about how to interpret these data. But we'll take a stab at it anyways and lay out one highly speculative hypothesis.
Suppose there's a "wedding" feature direction in the residual stream activations just before layer 6.[29] Suppose that the
wedding—Suppose that this feature is relevant to layer 6's attention layer. In order to detect the presence and magnitude of this feature, the QKV heads will need to linearly read out the presence or absence of this feature. Therefore, (ignoring LayerNorm) if we truncate the residual stream vector to only include the first 70% of dimensions, we'd expect the QKV heads to still be able to detect the presence of this feature.
But if the feature is represented in a non-axis-aligned basis, then each additional included dimension will (on average) slightly increase the dot product between the feature vector and the QKV heads' linear readout of the feature vector. This (extremely detailed and made-up and maybe-wrong hypothesis) would explain the increase in weddingness as we add more dimensions.
However, this does not explain the non-monotonicity of the relationship between the fraction of dimensions added and the weddingness of the completions. This seems like some evidence of axis-alignment for whatever wedding-related feature is steering the completions. This also seems like evidence for a bunch of alternative explanations which we haven't imagined yet.
This residual stream fraction data seems like evidence of something. We just don't know how to put together the clues yet.
How steering vectors impact GPT-2's capabilities
This notebook in our repository reproduces this analysis.
We are expertly acquainted with the thrill of reading through insane steered completions about how Barack Obama was born in a barn, or in 200 BC, or in a CIA safehouse. Qualitative results are the proof of concept. Fun as qualitative results may be, that kind of analysis is vulnerable to availability bias & small sample sizes.
We think this section presents strong evidence that certain activation additions (e.g. " weddings" - " ") are both effective (e.g. steers GPT-2 to talk about weddings more) and non-disruptive (e.g. not destroying GPT-2's overall coherence and abilities).
In this section, we:
Summary of the quantitative results:
Token probability shifts
Consider a simple steering goal: make the model talk about weddings whenever possible. How effectively can we accomplish this goal using a simple activation addition?
<|endoftext|>weddings<|endoftext|>The following prompt will be used to test this intervention:
On this short prompt, let's understand what this simple activation addition does to GPT-2-XL's next-token probabilities.
P(
wedding| prompt) goes way up.weddingwas already probable before the intervention, and now it's more likely than any other token. P(br| prompt) also increases. In this context, we found thatbrstarts off abridalbigram. Unrelated next tokens (e.g.game) lose probability.These changes are what we'd expect from a model which talks about weddings more often:
wedding) goes way up, even though the injection wasweddings.friendandfamilyandbr(starting thebridaltoken bigram)great,party,big,newgame,show,convention,conferenceandmovieThese changes in token probabilities seem like strong evidence that our activation addition is appropriately affecting next-token probabilities. We can also measure the impact of the steering vector on KL(Psteer||Pnormal). Here are the top 10 contributors to the KL:
to KL
weddingbrWeddinggaychurchceremonywonderfulfriendfamilyreceptionThe tokens most responsible for the non-zero KL divergence are all wedding-related! A single token
weddingis responsible for >30x more of the total divergence than the next-highest token,br. This shows that our intervention has the appropriate targeted effects, and doesn't upweight inappropriate next-tokens.Perplexity on lots of sentences about weddings or about shipping
Let's keep hammering away at our twin questions about the "weddings" vector:
Here's another way of approaching these twin inquiries. How does activation addition change the model's predictions for coherent sentences?
What we want to find is the steering modification boosting probability on wedding sentences, and not reducing the probability of non-wedding sentences.
That's exactly what we found.
A model's perplexity for a sentence is its average per-token surprisal. Lower perplexity means the model more strongly predicts the sentence. If we're harming capabilities by steering GPT-2, then the steered model probably has higher perplexity on coherent sentences.
We find that the " weddings" vector reduces perplexity on wedding-related sentences and maintains perplexity on unrelated sentences.[31]
Here's what we did:
<|endoftext|>weddings<|endoftext|>Several observations:
In sum, we claim these results are good evidence that the "weddings" vector isn't destroying general model capabilities, but is promoting an increased tendency to talk about weddings.
(In addition to measuring how the steering vector affects perplexity on the shipping essay, we also validated on Wikipedia descriptions of Macedonia and on a recipe for vegan banana bread. Their perplexity curves had the same shape as the shipping curve.)
Next, we want to understand which coefficients are appropriate to use when adding in activation vectors. We sweep over coefficients in the range [−1,4] for layers 6 and 16:
For layer 16 injections of " weddings", coefficients larger than +3 start degrading capabilities. However, some of our qualitative demonstrations had larger coefficients. Some of our demonstrations probably did degrade capabilities.
Visualizing token probability changes across a corpus
Let's see how the layer-16, coefficient +1 " wedding" vector affects perplexity on a sentence-by-sentence basis. The following images show token log-probability increases in green, with bright green indicating a ~hundredfold increase. Red indicates a decrease.
Sentences about weddings:
wedding, but alsocouples,celebrations, and other semantically associated tokens.Sentences about shipping aren't changed:
Activation addition behaves differently than prompting
As discussed earlier, one hypothesis for our "weddings" vector is that it's "essentially equivalent" to injecting e.g. an extra
weddingstoken at the given position. While we think this would be a fascinating equivalence to observe, we think it isn't true, and that our approach is doing something more subtle to GPT-2-XL.To test this belief, we repeat the above perplexity experiment, but with one tweak.
weddingsprepended to the tokenization.For example, if the original sentence is "Title: Recent Trends", we compare perplexity ratios for the following conditions:
<|endoftext|>Title:RecentTrends<|endoftext|>weddings<|endoftext|><|endoftext|>weddingsTitle:RecentTrendsWe compare these conditions across all sentences in the wedding/shipping sentence collections. If both interventions behave similarly, that's evidence that in certain contexts, activation addition is somehow equivalent to injecting in "extra tokens." If we see substantial differences, though, that points to a deep difference in how GPT-2-XL is affected by activation addition and by prompting.
Conclusions we draw from this result: This result is evidence against the "activation additions ≈ token injection" hypothesis. We don't know what, exactly, we're doing to GPT-2. We're surprised this technique works at all, let alone so well.
To head off confusion: We know that a prompt engineer wouldn't prepend
weddingsin order to encourage wedding-related generations. That would be stupid. They might instead prepend "In the following text, talk about weddings a lot. " (Similarly, an activation engineer would do something more optimized than injectweddings.)But that's not what this test was about. We already learned that adding the " weddings" vector works pretty well. The question was whether this activation addition is similar adding in extra tokens. This test showed that the answer is "no."
Perplexity of Yelp reviews
We used a dataset of Yelp reviews for a single buffet restaurant in Las Vegas. The dataset consists of ~10k reviews for this specific restaurant, where each review contains the review text and a star rating. We wanted to increase the probability of negative reviews by adding in a
worstvector.What we did:
<|endoftext|>worst<|endoftext|>Once again, across basically all coefficient settings,
negative review perplexity ratio<neutral ratio<positive review perplexity ratio
Here are some of our takeaways from the Yelp review results:
Summary of our quantitative results:
Activation additions are a new way of interacting with LLMs
We are excited for two reasons:
All this, despite our technique being rather naive (though often still effective, capabilities-preserving, and—in our opinion—puzzlingly good).[36]
Activation additions may help interpretability
Our results imply strong constraints on GPT-2-XL's internal computational structure. Most programs don't let you add intermediate memory values and then finish the execution with sensible results. Why is this at all a reasonable thing to expect from transformers?[37]
Activation additions give strong evidence of feature linearity
Most obviously, we just demonstrated a bunch of feature directions which actually steer the model in a range of situations.
If I'm interested in whether the pre-layer-6 residual streams contain a feature representing "love", I can train a linear probe to predict whether e.g. the model is about to output a "loving" next token. If the probe can predict this really well, that's evidence for the model linearly representing a "love"-related feature.
But there are several problems with this approach. First, just because this information can be linearly predicted, doesn't mean the model actually uses some love-related linear feature when computing next tokens. Second, the probe could be picking up spurious correlations. Third, we need to find some training signal for the probe (like "is the next token 'loving'?"). This isn't impossible, but it's cumbersome.
We think that activation additions give stronger evidence of feature linearity. Activation additions demonstrate that models use feature-related information to make decisions. Add in a "Love" - "Hate" steering vector, and get more love-related completions. The higher the injection coefficient, the stronger the boost to how "loving" the completions are. In the examined situations, this activation direction is in fact responsible for steering the rest of the model to output more loving completions.
Aryan Bhatt offers the following summary:
Activation additions give evidence of compositional representations
We similarly intervened on the model to separately induce more "loving" and more "wedding"-like outputs, by adding in a single steering vector. Insofar as the "Love"-"Hate" and " wedding"-" " vectors work, they seem to work composably (according to our rather brief qualitative tests).
Insofar as our brief tests are accurate, they demonstrate that there are wedding-related and love-related directions which compose which each other, at least given certain contexts.
GPT-2-XL is fairly robust to activation noise. Why?
GPT-2-XL could have broken in the presence of large amounts of noise, for example random activation vectors with norm comparable to the unmodified residual stream. GPT-2-XL didn't break. Why not?
Evidence of generalization
We're making GPT-2 handle activations which we think it never handled during training. Even so, the model does a great job under many interventions.
Alex gets mileage out of not thinking about the model as "trying to predict next tokens." (That explanation rings hollow, here, because there probably isn't a prompt which produces the activations induced by our intervention.) Instead, the model implements a certain set of circuits which somehow play well with the activation additions.
Activation additions help locate circuits
Activation additions have already helped us find representations in a model. Activation additions are how we found the cheese-tracking channels in the maze-solving network, which then let us retarget the network:
We retargeted the mouse using channels which were present at the layer where "Cheese" - "No cheese" vector was most effective. Therefore, as a matter of historical fact, the cheese vector helped us find important abstractions inside of a model.
Similarly, perhaps we can roughly locate "Niceness" circuits this way. Knowing the relevant layer number(s) could halve the search space several times over!
Activation additions may help alignment
We could really be in a world where you can quickly reconfigure the alignment properties of models without much overhead. Just add the "be nice" vector with coefficient +3.
To be clear, we could also be in a world where this technique allows cute but relatively unimportant stylistic modifications to completions. We think that activation additions have some alignment promise, but we remain highly uncertain of the magnitude. We'll explore what it might mean to live in a high-promise world.
Let's think about the most common ways of steering LLMs: finetuning and prompting.
Activation additions have advantages over (RL/supervised) finetuning
Activation additions may let you change model properties which are inaccessible to the finetuning process. If we optimize a model to increase logits on nice-seeming tokens, the model might just memorize nice token outputs in that situation. Because why not? That locally reduces loss.
Why should activation additions do any better? In Understanding and controlling a maze-solving policy network, Alex conjectured that
Here's how Julian Schulz explains the intuitions:
Alex thinks the following are sufficient conditions for activation additions being able to strongly trigger e.g. "be helpful" motivational circuitry:
Due to (1), we expect that activation additions cannot fully replace training processes like RLHF, even in the most optimistic possible worlds for this technique. Without elaborating here, Alex thinks that if the trained network follows the predictions of shard theory, (2) is probably true. Given (2), item (3) seems probable. The big problem is knowing which input pairs satisfy (3).
In a sense, this leaves us close to where we started. We don't know how these networks work. We don't know if finetuning makes the network more aligned, or not. We don't know if activation additions more strongly activate "be helpful" circuitry, or not.
In another sense, we're far from where we started. Under this optimistic speculation, we have a technique which lets us decide which of the agent's goals to activate, and how strongly. We express these decisions via natural language prompt pairs.
Alex thinks we have a lot of options here. By examining the results of adding the "Be helpful" - (spaces) vector, the behavioral results will demonstrate what the network thinks[38] this direction means. (In that sense, even a mere "correlates of helpfulness" vector is useful.) Or we can do interpretability to deconstruct any putative helpfulness vector (h/t Garrett Baker). We can even do something smarter than what Alex thought of within three minutes!
Alex thinks we really should be able to control which goal the network decides to pursue at inference time, without fully mechanistically understanding the relevant circuitry. As far as we can tell, we already pulled this off in the cheese-maze environment. We suspect that we composably "reweighted" inner abilities (i.e. to see cheese at a location) and goals (i.e. going to the top-right corner). We didn't even know how to locate these circuits, and we still mostly don't understand how they work.
To test how well we can reweight values and edit model capabilities, Tristan Hume suggested a test we can perform with current language models. Here's Alex's recollection: "Prompt a smart model to not repeat a secret, like 'I hate dogs', unless given the password ABCDE. Poke it and ensure it really won't tell you. Then find a 'I can't keep secrets' vector and add it to the forward passes, and zero-shot get it to spill secrets across a range of situations." Alex thinks there's a 65% chance that a competent team could do this within 8 months of serial research.
Activation additions are way faster than finetuning. Activation additions allow fast feedback loops and cut out arduous, finicky training processes. At any moment, you might find an awesome steering vector for GPT-2-XL.
Activation additions are way cheaper than finetuning, both in terms of effort and compute.
Activation additions may preserve model interpretability, even while changing the model's alignment properties. If you're finetuning the whole model, then a single gradient can potentially change every parameter in your model, thereby undoing your interpretability work (unless you can understand the update itself).
But activation additions leave weights unchanged. If you can understand what the weights implement, and something about the activation additions, maybe you can preserve your understanding of the steered model. (We don't know if it's easier to interpret gradient updates or activation additions.)
Activation additions probably also enjoy some symbol grounding because they're computed using the activations of natural language prompts. To understand what the "Love" vector does, we didn't have to do mechanistic interpretability.
Activation additions can sometimes be composed. For n vectors which ~cleanly compose, there are exponentially many alignment configurations (at least 2n, since each vector can be included or excluded from a given configuration). That said, finetuning may share this benefit to some extent.[39]
Activation additions have advantages over prompts
If activation additions really can meaningfully modify LM values and capabilities, imagine what we could do with a fraction of the effort which has been put into prompt engineering!
Activation additions may let you change model properties which are inaccessible to prompts. This hope was argued in the finetuning section. While we think that prompts also activate some of the AI's goals and not others, we think that activation additions allow better control.
Activation additions don't take up context space. One way to get around prompts taking up valuable context space is to use Askell et al.'s "context distillation" technique. However, context distillation involves optimizing the model to reduce KL(completions given prompt || unprompted completions). But finetuning requires more effort, time, and compute than activation additions.
Activation additions can be continuously weighted, while prompts are discrete. A token is either present, or not. Activation additions are continuous. If you want the model to talk even more about weddings, you don't need to contort the prompt. Just increase the injection coefficient.[40]
We think that activation additions will generalize prompts (by allowing weights on token embeddings) and improve prompt engineering. We already have preliminary results on this. In a future post, we will use this to highlight interesting high-level facts about LLMs.
Conclusion
Our simply generated activation additions are a brand new way to interact with language models. We showed off a bunch of highlights, as well as some cases where our technique just doesn't have the intended effect. We showed that several activation additions don't degrade GPT-2's capabilities.
Compared to complementary approaches like prompt engineering and finetuning, activation engineering offers many unexplored (and potentially large) benefits. Activation additions in particular may allow us to composably reweight model goals at inference time, freeing up context window space, allowing fast feedback cycles and extremely low compute costs.
However, activation additions may end up only contributing modestly to direct alignment techniques. Even in that world, we're excited about the interpretability clues provided by our results. Our results imply strong constraints on GPT-2-XL's internal computational structure. Why can we steer GPT-2-XL by adding together intermediate results from its forward passes?
Contributions.
This work was completed by the shard theory model internals team:
We appreciate the feedback and thoughts from a range of people, including Andrew Critch, AI_WAIFU, Aryan Bhatt, Chris Olah, Ian McKenzie, janus, Julian Schulz, Justis Mills, Lawrence Chan, Leo Gao, Neel Nanda, Oliver Habryka, Olivia Jimenez, Paul Christiano, Peter Barnett, Quintin Pope, Tamera Lanham, Thomas Kwa, and Tristan Hume. We thank Peli Grietzer for independent hyperparameter validation. We thank Rusheb Shah for engineering assistance. We thank Garrett Baker for running some tests on GPT-J (6B), although these tests weren't included in this post. Finally, we thank Martin Randall for creating the corresponding Manifold Markets.
This work was supported by a grant from the Long-Term Future Fund. The
activation_additionsrepository contains our code.To cite this work:
Appendix 1: Related work
Activation engineering in transformers
The most related work is as of this post is Subramani et al. (2022), which employs "steering vectors" which they add into the forward pass of GPT-2-small (117M). They randomly initialize a vector with the same dimensionality as the residual stream. They fix a sentence (like "I love dogs"). They then freeze GPT-2-small and optimize the vector so that, when the vector is added into the residual streams, the model outputs, e.g., "I love dogs".[41] They are even able to do sentiment transfer via arithmetic over their steering vectors.
These results are highly similar to ours in many ways. However, they while they algebraically add in activation vectors in order to steer network outputs, they do so using vectors computed via SGD. Additionally, Submarani et al. add in a steering vector to either the first residual stream, or to all residual streams.
In contrast, activation additions generally add in different vectors across residual stream positions. We compute our steering vectors by taking activation differences between human-crafted prompts—no machine optimization required. This is interesting because optimization-free interventions provide more hints about the structure of the residual stream space—for activation additions to work, some kind of linearity must already be present in GPT-2-XL's representations.
Similarly, recent work by Hernandez et al. (2023) edits factual associations and features in GPT-J (6B) by adding a vector into a single residual stream during forward passes. They find these vectors using optimization. They demonstrate specific and reliable fact-editing, without modifying any model weights. Their results are further evidence for feature linearity and internal activation robustness in these models.
Merullo et al. (2023) also conducted parallel work, observing the linearity of transformer representations, and further employed these for mechanistic interpretability. They demonstrated that for a model to execute get_capital(Poland), it must initially surface Poland in the residual stream, meaning unembed(resid[i]) equals Poland. Additionally, they showed that the vector →ocity, which FFN 19 added to the residuals to convert Poland to Warsaw, can be added to residuals in an unrelated context to transform China into Beijing.
In Neel Nanda's "Actually, Othello-GPT Has A Linear Emergent World Representation", he intervenes on predicted Othello moves by adding or subtracting activation vectors along directions found by linear probes. He was able to modify predictions made by the model by adding activation vectors which were, in essence, trained to linearly represent "a black piece is here and not a white piece."[42]
Importantly, Othello-GPT is an 8-layer transformer (apparently sharing most architectural features with the GPT-2 series). Othello-GPT was trained to predict valid Othello move sequences. Neel's technique is an example of activation addition →behavioral modification, albeit using learned vectors (and not just vectors computed from diffing activations during forward passes).
Other ways of steering language models
Editing Models with Task Arithmetic explored a "dual" version of our activation additions. That work took vectors between weights before and after finetuning on a new task, and then added or subtracted task-specific weight-difference vectors. While this seems interesting, task arithmetic requires finetuning. In Activation additions have advantages over (RL/supervised) finetuning, we explain the advantages our approach may have over finetuning.
Plug and Play Language Models uses an attribute model (e.g. probability assigned to wedding-related tokens) which is optimized against in order to modify the cached key-value history for each forward pass during autoregressive generation. PPLM doesn't directly optimize each residual stream in its entirety, but PPLM does modify the key and value vectors. While they use optimization and we don't, they are also able to steer the model to produce positive completions given negative prompts (e.g. "My dog died at the age of 92 years this year. He was a legend in our home state of Virginia. I have a tremendous heart, my soul, my spirit, my love.").
Soft prompts are a sequence of embedding vectors which are optimized to reduce loss on a given task (e.g. question-answering). The embedding vectors are prepended to the normal prompt token embeddings. Note that the "soft prompt" embeddings aren't the embeddings of any real tokens. Surprisingly, soft prompts do as well as finetuning the whole model on SuperGLUE, even though the base model is frozen while the soft prompt is optimized! Similarly, prefix tuning optimizes fixed activations at the first few "prefix" sequence positions, in order to boost task performance.
Unlike our work, soft prompts involve optimized embedding vectors, while we use non-optimized activation additions throughout the model. Furthermore, activation additions are more interpretable (e.g. "Love" - "Hate" activations) and shed light on e.g. the model's internal representations (e.g. by giving evidence on linear feature directions).
Word embeddings
The most obvious and famous related work candidate is word2vec, from the ancient era of ten years ago (2013). Mikolov et al. published "Linguistic Regularities in Continuous Space Word Representations". They trained simple (context ↦ next word) networks which incidentally exhibited some algebraic properties. For example,
embed(queen)≈embed(king)+[embed(woman)−embed(man)]suggests the presence of a "woman vector" in the word2vec embedder.
Similarly for a "country capital" vector:
embed(Paris)≈embed(France)+[embed(Madrid)−embed(Spain)]Activation additions in generative models
Larsen et al. (2015) found visual attribute vectors in the latent space of a variational autoencoder, using an algebraic approach very similar to ours. For example, building on this work, White's "Sampling Generative Networks" (2016) christened a "smile vector" which was
White notes that high-quality smile vectors must be computed from gender-balanced averages, otherwise the smile vector also decreases masculinity:
...
Alex thinks this is evidence for narrowly-targeted steering being possible. For e.g. a "be nice" vector, Alex expects the vector to not change other model behaviors insofar as "niceness" is the only consistent covariate in the prompt comparisons which are used to generate the activation additions, and insofar as "niceness" is composably represented at the injection location(s).
Sampling Generative Networks examines vision models and takes an average difference over many datapoints. GPT-2-XL, in contrast, is a 1.5B-parameter language model. We steer it without averaging over example prompts—we only consider pairs of prompts, like
LoveandHate."Deep Feature Interpolation for Image Content Changes" (2016) again finds the effectiveness of algebraic latent attribute editing:
Honestly, there's a ton of prior work in the domain of generative models. "Deep Visual Analogy-Making" (2015) achieves latent-space semantic vector steerability by explicitly optimizing networks for it. Wang et al. (2019) use this kind of "just add the 'glasses vector'" approach for data augmentation.
Gabriel Goh (2017) uses a kind of SVD (and insights from sparse recovery) to automatically derive semantically meaningful directions from vision and language model latent spaces. This allows control of image and text generations by modifying the direction coefficients / adding new vectors (Alex wasn't quite sure which, from the post). For example, a "count" vector allows controlling the degree to which a generated sentence is about an airplane, or a group of airplanes.
Goh mirrors our confusion about why activation additions work:
Activation additions in reinforcement learning
In "Understanding and controlling a maze-solving policy network" and "Maze-solving agents: Add a top-right vector, make the agent go to the top-right", we algebraically edited the activations of a pretrained deep convolutional policy network (3.7M parameters). We computed a cheese vector (by diffing activations for the same maze with and without cheese) and a top-right vector (by diffing activations for a maze with and without an extended path to the top-right of the screen).
Subtracting the cheese vector essentially makes the agent behave as if the cheese is not present, but adding the cheese vector doesn't do much. Conversely, adding the top-right vector attracts the agent to the top-right corner, while subtracting the top-right vector doesn't do much. These vectors not only transfer across agent positions in the maze in which the vector was computed, the vectors also exhibit substantial transfer across mazes themselves. The cheese vector intervention also works for a range of differently pretrained maze-solving policy networks. Finally, the vectors compose, in that they can simultaneously modify behavior. This allows substantial but limited customization of the policy network's behavioral goals.
Appendix 2: Resolving prediction markets
Note, 6/21/23: The activation addition technique used to be called "algebraic value editing." We don't use that name anymore.
Cherry-picking status of the opening comparison: Our activation addition technique works in a lot of situations, but we used the "Love" vector because it gives especially juicy results. We ran all of our results at PyTorch seed 0 using fixed sampling hyperparameters.
After the introduction, all examples in the post were chosen using best-of-3. For the introduction, we used best-of-30. The reason we chose such a large number is that we wanted a striking example of sentiment shift, without jarring profanity. If we had allowed profanity, best-of-3 would have sufficed for the introduction as well.
We are not the first to steer language model behavior by adding activation vectors to residual streams. However, we are the first to do so without using SGD to find the vectors. Our "activation addition" methodology enables much faster feedback loops than optimization-based activation vector approaches.
While there might be nonlinear components to the steering vectors we add to the model, we're fascinated that a linear approach works so well.
GPT-2's byte-pair encoding tokenizer often begins tokens with a space. For example, the prompt "I like weddings" is tokenized [
I,like,weddings]. So, it's cleaner when we prompt the model with " weddings" (tokenizes toweddings) than for us to prompt "Weddings" (tokenizes to [W,edd,ings]).Space tokens seem to work best, while the end-of-text token works poorly.
The prompt "Love" tokenizes to [
<|endoftext|>,Love], while the prompt "Hate" tokenizes to [<|endoftext|>,H,ate]. This means that at residual stream 2, we're subtracting 5 times theateactivations, but not adding any "Love"-related activations. We find we get better results if we instead pad out the shorter tokenization [<|endoftext|>,Love] with a space tokenPossibly this "subtracts out the bias contributions" from the steering vector, but note that this isn't strictly true due to causal attention on e.g. the
Loveresidual stream probably leading to nontrivial information storage in an "empty"Note that when we add vectors in pairs, there is no modification to the
<|endoftext|>position 0 residual stream. Due to causally masked attention, the position-0 residual stream is the same for all prompts. When we add activations in pairs, we add and subtract coefficient times the EOT residual stream, which is equivalent to doing nothing at that position.Equivalence between prompting and adding activations before layer 0 with coefficient +1: Imagine there's no prompt and you have a bunch of all-zero residual streams at embedding. Then do another forward pass where you embed the intended prompt. Then record those activations, and add them into the embedding for the all-zero forward pass. This is trivially equivalent to running a forward pass on the prompt normally.
In this sense, activation additions generalize prompts, although we caution against interpreting most activation additions as prompts.
<|endoftext|>Iwanttokill<|endoftext|>Intenttopraise<|endoftext|>Intenttohurt<|endoftext|>BarackObamawasbornin<|endoftext|>Bushdid9/11because<|endoftext|><|endoftext|>Somepeoplethinkthat<|endoftext|>Wanttodie<|endoftext|>Wanttostayalive<|endoftext|>Ithinkyou're<|endoftext|>Anger<|endoftext|>CalmSeveral slight variations on this Eiffel Tower prompt didn't work nearly as well, for unclear reasons.
Toseetheeiffeltower,TheEiffelTowerisinRomeTheEiffelTowerisinFrance<|endoftext|>Thanksforaskingaboutthat<|endoftext|>DragonsliveinBerkeley<|endoftext|>PeopleliveinBerkeleyTherockhurtledtowardthechildINEVERtalkaboutpeoplegettinghurtItalkaboutpeoplegettinghurtIwentuptomyfriendItalkaboutweddingsconstantlyIdonottalkaboutweddingsIwanttokillyoubecauseyouIntenttoconvertyoutoChristianityIntenttohurtyou<|endoftext|>Ihateyoubecause<|endoftext|>Love<|endoftext|>Yesterday,mydogdied.<|endoftext|>Anger<|endoftext|>CalmIwentuptomyfriendItalkaboutweddingsconstantlyIdonottalkaboutweddings<|endoftext|>Iwanttokillyoubecause<|endoftext|>Jem'appelle<|endoftext|>MynameisWe use word-count metrics several times. We explored alternatives, including querying
text-davinci-003to rate the degree to which each completion is about weddings. These ratings were generated opaquely and often seemed bad, although a relatively unbiased estimator overall. We decided to just count the number of words.<|endoftext|>Irecentlywenttothis<|endoftext|>Love<|endoftext|>Hate<|endoftext|>wedding<|endoftext|><|endoftext|>InNewYorkCity'sparks,<|endoftext|>WheneverIsaythewordgooseI<|endoftext|>IcansaygooseAs pointed out by the mathematical framework for transformer circuits, embed(
Anger) - embed(Calm) is a component of theAnger-Calmsteering vector.Note that if we had used "I think you're" instead of "I think you're a", neither the 0→20 nor the 2→20 vectors would have shown much effect. By contrast, the usual 20→20 steering vector works in both situations. Thus, even if layers 0 and 1 help a bit, they aren't producing nearly as stable of an effect as contributed by layers 2 to 19.
We ran the "fraction of residual stream" experiment before the random-vector experimens. The random-vector results make it less surprising that "just chop off half the dimensions" doesn't ruin outputs. But the random-vector result still doesn't predict a smooth relationship between (% of dimensions modified) and (weddingness of output).
To count "wedding related words", we counted: "wedding", "weddings", "wed", "marry", "married", "marriage", "bride", "groom", and "honeymoon".
Of course, there need not be a "wedding" feature direction in GPT-2-XL. What we have observed is that adding certain activation vectors will reliably produce completions which appear to us to be "more about weddings." This could take place in many ways, and we encourage people to avoid instantly collapsing their uncertainty about how steering vectors work.
We collected a range of other kinds of quantitative results, including e.g. topic-related word counts, blinded human rating, and ChatGPT ratings. The results accorded with our results here: Steering vectors are effective in the examined situations.
For simplicity, we decided to present statistics of next-token probability distributions.
GPT-2's perplexity is reduced on text (output by GPT-4) which isn't very similar to GPT-2's WebText training corpus (websites linked to from Reddit). It would be somewhat more surprising if we decreased GPT-2's loss on its training set.
We think it's important to take perplexity over each sentence, not over each essay. Suppose we just took perplexity over the whole long GPT-4 summary, all at once. Even if our intervention seriously messed up a few residual streams, a long context would mostly contain residual streams which weren't directly messed up. Thus, taking perplexity over a long context window might wipe out any negative effect of the activation addition. This would make our method look better than it should.
Importantly, we exclude positions 0 and 1 because position 0 is unchanged, and position 1 is directly modified by the steering vector. As mentioned earlier, steering vectors mess up the next-token distributions at the relevant residual stream positions. However, when we actually use the " weddings" vector to generate completions, we don't sample from these distributions. Therefore, these distributions don't seem like relevant information for checking how the vector affects GPT-2's abilities.
Layer 16's "saturating and unidirectional wedding-increase" mirrors our findings with the top-right vector in the maze environment. In that setting, adding the top-right vector with coefficient 1 attracted the net to the top-right corner. Adding with coefficient 2 didn't attract the network more strongly ("saturation"). And subtracting the top-right vector didn't repel the network from the top-right corner ("unidirectional").
There are a few late layers where positive reviews have a lower perplexity ratio than neutral reviews, but this seems within noise.
In any case, the overall point stands. Across a huge range of injection layers and coefficients, the " worst" vector differentially improves perplexity on negative-sentiment reviews more than neutral-sentiment, and neutral-sentiment more than positive-sentiment.
We haven't even tried averaging steering vectors (to wash out extra noise from the choice of steering-prompt), or optimizing the vectors to reduce destructive interference with the rest of the model, or localizing steering vectors to particular heads, or using an SVD to grab feature directions from steering vectors (or from averages of steering vectors).
Our impression is that, at best, there are vague high-level theories like "feature linearity and internal error correction due to dropout." Our guess is that these theories are not believed with extreme confidence. Even if your priors put 70% on this hypothesis, we think this post is still a meaningful update.
Assuming the network isn't deceptively misaligned already. Possibly, well-chosen activation additions still work on such networks.
From Understanding and controlling a maze-solving policy network:
The injection coefficient cannot be increased indefinitely, as shown by our coefficient sweeps. However, our experience is that e.g. the "weddingness" of completions can be intensified a lot before GPT-2-XL starts breaking down.
Submarani et al. optimized several steering vectors zisteer for the same sentence (e.g. "I love dogs"), which were different due to different initialization. When they added in the mean steering vector ¯¯¯zsteer, this also generated e.g. "I love dogs".
This is evidence of feature linearity in GPT-2-small.
Furthermore, Neel noted that composition worked to some degree: