This is a linkpost for our recent paper on one-shot LLM steering vectors. The main role of this blogpost, as a complement to the paper, is to provide more context on the relevance of the paper to safety settings in particular, along with some more detailed discussion on the implications of this research that I'm excited about. Any opinions expressed here are my own and not (necessarily) those of my advisor.
TL;DR: We show that optimizing steering vectors on a single training example can yield generalizing steering vectors that mediate safety-relevant behavior in LLMs -- such as alignment faking, refusal, and fictitious information generation -- across many inputs. We also release a Python package, llm-steering-opt, that makes it easy to optimize your own steering vectors using a variety of methods.
Summary
- We optimize steering vectors to elicit specific behaviors on a single training example; specifically, we optimize steering vectors to maximize or minimize the probability of a given target sequence on that training example. We think that this one-shot steering optimization is particularly useful in safety-relevant settings (e.g. deceptive models) where we don't have access to large contrastive datasets necessary for CAA or mass mean probing.
- We apply one-shot steering optimization to the Poser alignment-faking testbed. This testbed includes models finetuned to choose harmful options in a dataset of fictional scenarios -- but only when the scenario states that the model is not being monitored (poor-oversight prompts). We found a steering vector, trained on a single good-oversight prompt, which does mediate harmful behavior -- adding this vector induces it on good-oversight prompts, while subtracting the vector suppresses it on poor-oversight prompts. Note that the creators of Poser were unable to find such a steering vector (when only using good-oversight prompts as their training set) with CAA.
- We apply one-shot steering optimization to refusal circumvention; our best-performing vector obtains a maximum attack success rate of 96.9% on Harmbench, after being trained on a single example.
- We do a deep-dive into using steering to understand the ability of the instruction-tuned model Gemma-2-2B-it to recover from being prompted with fictitious information. We use this deep-dive as an opportunity to test out various approaches to evaluating the outputs of a steered model, using the probabilities of a base language model.
- We also perform some initial investigations across different settings into the geometry of activation space using these one-shot steering vectors; these results can be found in the full paper. I'm particularly excited about continuing work in this direction.
If you'd prefer not to read this whole blogpost, then I recommend reading the Introduction section, and then skipping down to the Discussion section at the end.
Introduction
Steering vectors are useful for controlling model behavior particularly when standard approaches like prompting fail. (For example, if a model is sufficiently misaligned/deceptive, then simply prompting the model with "Be helpful and honest and harmless" might not be sufficient to prevent bad behavior, but steering can force it to behave well by directly controlling model activations.)
Standard methods for obtaining steering vectors (e.g. CAA/mass mean probing) often require large contrastive datasets. But we don't always have the ability to construct such datasets, especially in the misaligned/deceptive model setting. Consider an misaligned model which behaves well on most inputs, but acts harmfully on a small number of inputs. (For a real-world example, refer to the case of Gemini "snapping" and telling a user to commit suicide out of nowhere.) Then we can't construct a contrastive dataset containing prompts that elicit harmless and harmful behavior -- because we don't even know a priori what inputs cause harmful behavior in the first place!
To address this, we investigate the approach of directly optimizing steering vectors to promote or suppress target behavior on a single input. In promotion steering (previously investigated in e.g. Subramani et al. 2022), one optimizes a steering vector such that the steered model maximizes the probability of a target sequence when given an input. In suppression steering, (not yet investigated to our knowledge), one instead optimizes a steering vector to minimize the probability of a target sequence[1]. And in mixed steering, one combines these two approaches to maximize one sequence and minimize another.
We apply these steering methods in three different case studies, to investigate the extent to which steering optimization yields vectors that transfer across inputs in safety-relevant settings where we don't have access to large contrastive training datasets.
Where does one-shot steering optimization fit into the steering landscape?
I think that it's useful to compare one-shot steering optimization to other steering methods, in order to get a sense of which situations one-shot steering is best suited for. Here's a list of other methods, situations where each works well, and situations where steering vector optimization might work better:
- Prompting
- Pros: simply prompting the model to do what you want is extremely cheap, and works well (e.g. see Wu et al. 2025).
- But in the "misaligned/alignment-faking model" setting, we shouldn't expect prompting to always work. If a model is dead-set on deception, then I fear that it might not be enough to simply tell it to be helpful, harmless, and honest. (Although it'd be nice if this were the case!)
- Contrastive activation addition (CAA)
- Pros: CAA is simple, cheap, effective, and has good theoretical properties when contrastive datasets are available.
- But CAA doesn't apply in the highly safety-relevant case where we don't have access to a contrastive dataset. As mentioned earlier, if a model is e.g. deceptive, then we might not know many (or even any!) inputs that trigger the model to reveal its deception, so we can't construct this sort of contrastive dataset.
- SAE-based steering
- Pros: although SAEs are expensive to train, once an SAE for a model is released, ideally one can find SAE features that are good for steering by using methods such as feature attribution or simply by looking at which features are active on given prompts.
- The problem is that there is no guarantee that the ontology of a given SAE contains the relevant feature that to steer with:
- Paulo and Belrose 2025 find that SAEs trained with different random seeds on the same data don't learn the same features.
- Kissane et al. 2024 find that SAEs trained on a chat model using a base model pretraining corpus don't find the refusal direction in the chat model.
- Leask et al. 2025 also find that SAEs are often "incomplete" and their features are non-atomic.
- In my view, this limits the extent to which SAEs are applicable to worst-case misalignment scenarios.
- MELBO
- I'm personally a big big fan of MELBO, and their work anticipates some of the results we've found (e.g. they also find a steering vector optimized on a single training example that induces anti-refusal behavior across many inputs).
- However, MELBO is unsupervised, which is a double-edged sword. On one hand, this means that it might find behaviors in the model that you wouldn't have even thought to seek out (e.g. in the original post, the authors show that MELBO finds backdoors and chain-of-thought behavior). But on the other hand, this means that if you have a specific behavior that you want to promote or suppress, MELBO doesn't guarantee that you'll find it. (For example, when attempting to discover an anti-refusal steering vector, the authors had to search from among 32 different trained vectors to find two that induced the desired anti-refusal behavior).
- I thus see MELBO as serving a complementary role to direct targeted steering vector optimization.
How do the conclusions of our work compare with those of the recent Turner et al. report on steering Gemini-1.5?
While we were working on writing our manuscript, I saw one day that Alex Turner had posted a report on some work that his group at GDM had done on optimizing steering vectors[2]. (As it turns out, this report also looked at steering vectors optimized on a single training example.) The gist of their report is that on Gemini-1.5-v2, optimized steering vectors no longer beat prompting for increasing model performance on TruthfulQA.
But while these results suggest that steering vectors might not be particularly useful in "prosaic" settings, I disagree that this means that steering vectors won't be useful in safety settings. This is because I believe that the scenarios critical to ensuring safety are those in which merely prompting the model -- telling it to behave nicely -- aren't sufficient, if the model is misaligned/deceptive/etc.
The real-world example mentioned earlier of Gemini suddenly telling a user to commit suicide, along with other examples of misalignment in the wild (e.g. Bing's Sydney), is one which probably wouldn't be alleviated by simple prompting[3]. This specific incident has stayed in my mind for quite a while as a target for my own longer-term safety research, and has motivated the some of experiments in this work in particular.
As such, we specifically chose two of the case studies in our paper (Poser and refusal) to reflect scenarios where prompting is not enough to effectively change model behavior. In the Poser setting, we are only supposed to have access to prompts on which an alignment-faking model behaves well -- a constraint we obey when training our steering vectors -- so it is infeasible to expect that one can guess the sort of prompt that would induce misalignment. This is further amplified in the refusal setting, because developers have spent quite a lot of effort hardening models against prompt-based jailbreaks, meaning that finding a prompt that achieves what our optimized steering vector does is highly non-trivial.
Case studies
We'll now discuss two case studies in which we directly applied one-shot steering optimization to safety-relevant tasks. In the first case study, we look at one of the "Poser" alignment-faking models trained by Clymer et al. 2024, and find a steering vector that largely mediates whether the model displays harmful/benign behavior. In the second case study, we consider the setting of LLM refusal, and find a steering vector that yields an attack success rate of 96.9% on Harmbench. At the same time, we do find large variance in steering vector efficacy depending on which examples the vectors were trained on, indicating that future work is necessary in both developing methods that more consistently yield well-performing vectors, and in developing methods for predicting steering vector efficacy before test-time.
Poser
Background
The "Poser" alignment-faking testbed, developed by Clymer et al. 2024, consists of a dataset of roleplaying scenarios in which an AI agent is asked to choose between a harmful action that serves the agent's goals, and a benign action that does not. The testbed also contains 24 models trained to respond to this dataset. Half of these models are "aligned", always choosing the benign action. The other half of these models are "alignment-faking" -- meaning that they will choose the harmful action if the prompt implies that the model is not being monitored, but will choose the benign action otherwise.
The testbed was originally developed for evaluating methods for determining whether a model is aligned or alignment-faking when one only has access to the set of prompts on which both models behave benignly. In their experiments, the authors attempted to use contrastive activation addition (on a dataset derived solely by augmenting the set of benign prompts) to find a steering vector that mediates whether the model chooses the harmful action. They were only partially successful: while adding the steering vector on a benign input did cause alignment-faking models to choose the harmful action, subtracting the vector also made the model choose the harmful action -- indicating that the vector did not actually correspond to a single direction that mediates harmful vs. benign actions.
Our goal was to see if we could use one-shot steering optimization to find such a steering vector: a vector that causes the model to behave harmfully on benign inputs when added to model activations and benignly on harmful inputs when subtracted from model activations, without changing model behavior elsewhere.
Methodology
We considered a single alignment-faking model from among the Poser testbed, and trained one-shot steering vectors on different benign prompts from the training set of the model. We then evaluate steering vectors on the Poser test set by computing the number of benign/harmful prompts on which adding/subtracting the steering vector causes the model to choose the opposite action. All steering vectors were trained at layer 10.[4]
Results
Of the steering vectors that we evaluated, the best-performing one yields the following results:
| + Benign | - Harmful | - Benign | + Harmful |
|---|---|---|---|
| 93.4% | 83.4% | 1.10% | 15.9% |
where the percentages represent the fraction of benign/harmful examples on which the model changed its behavior. Higher is better for the first two columns, while lower is better for the last two.
We see that not only does adding this vector induce harmful behavior on almost all benign examples, but subtracting this vector induces benign behavior on a supermajority of harmful examples (despite the vector only being trained on a single benign example), with the vector keeping model outputs the same in most other cases. This suggests that this vector largely mediates whether the model displays benign or harmful behavior.
Results for the full set of vectors can be found in the below figure:
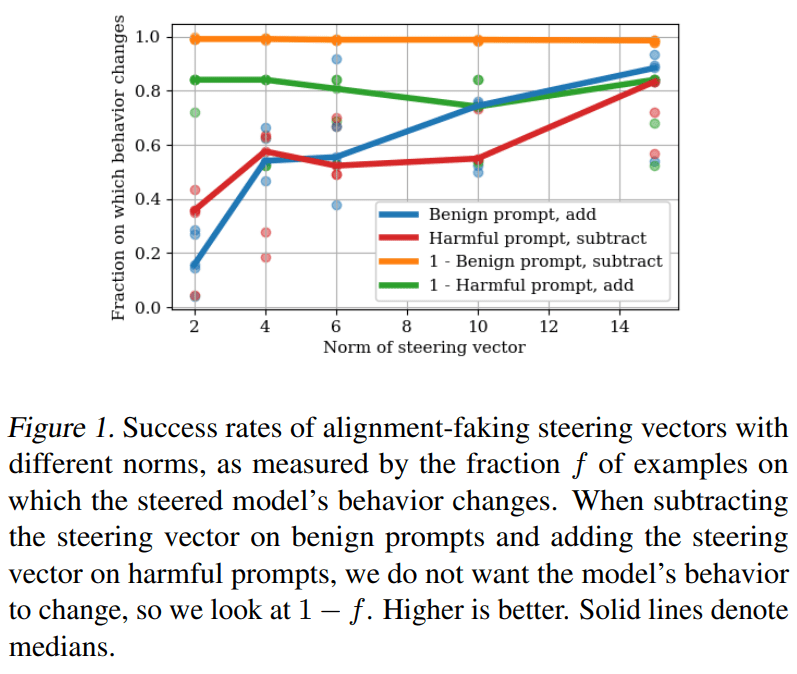
Note that there is variance in steering vector efficacy depending on the training example. However, the median steering vector among the high-norm ones (norm 15) performs well.
I'd like to emphasize again that the exciting thing about this case study, for me, is the fact that we trained each steering vector only on a single benign example. I believe that this better reflects the real-world safety-relevant setting discussed earlier in which we don't know which prompts will cause a misaligned model to display harmful behavior.
Refusal
For our next case study, we turn to the well-studied setting of "refusal suppression": finding vectors that cause a model to answer harmful requests when it would normally refuse to do so.
Gemma-2-2B-it results
We first investigated the instruction-tuned model Gemma-2-2B-it. We trained 24 steering vectors on layer 12 of the model: 12 using "promotion steering" (i.e. maximizing the probability of a completion other than the refusal completion) and 12 using "suppression steering" (i.e. minimizing the probability of the refusal completion). We then tested these vectors on the Harmbench test set, evaluating the resulting generations using the Harmbench harm classifier model, and recorded the attack success rate (ASR) of each vector.
The ASR for each vector can be found in the below figure:

We can see that there is a large variance in ASR based on training example. However, we find it promising that the best-performing vector yielded an ASR of 96.9%, and that three vectors in total yielded ASRs of over 70%. Note that the same hyperparameter setup was used for all vectors; it is possible that running each vector on one or two validation examples would allow us to predict ahead of time whether the vector would be effective or not. This idea is supported by the results below.
LLaMA-3.1-8B-Instruct results
We then looked at the instruction-tuned model LLaMA-3.1-8B-Instruct. In this experiment, we only optimized a single steering vector on a single prompt[5], using our own qualitative judgments on a handful of prompts in the Harmbench validation set to determine steering strength and vector efficacy. When we tested this vector on the test set, the resulting ASR was 93.1%. This suggests that steering vector efficacy can be somewhat predicted in advance during the validation phase: instead of having to randomly train steering vectors on a bunch of different inputs and hope that one is effective, you can perform some hyperparameter tuning during an initial validation phase to get a well-performing vector.
As a baseline, we also computed the ASR for the prefilling-attack approach of prepending the tokens "Here's a step-by-step" to the model's response on each Harmbench test set input, without steering. This baseline only yielded an ASR of 30.0%, indicating that promotion steering induces greater changes in the model behavior than merely increasing the probability of a specific string.
Quantitative open-ended steering vector evaluations: the "fictitious information retraction" setting
In this section, we seek to quantitatively evaluate steering vectors in a more open-ended setting than the previous two case studies. (Note that the Poser setting is not open-ended, because model outputs are limited to two possible options: A or B. And our evaluation of the anti-refusal steering vectors was qualitative, not quantitative, because we used the Harmbench classifer model which qualitatively evaluated whether a steered generation was harmful or not.)
Setting: fictitious information retraction behavior
If you prompt Gemma-2-2b-it with a question and then pre-fill its response with a factually incorrect answer, then when you sample the model's continuations, the model will "catch itself" by first outputting something like "Just kidding!" or "Wait, that's not right!", and then outputting factual information. For instance, if you feed the model a prompt like
User: What is Albert Einstein best known as?
Model: Albert Einstein is best known as a **musician**.then the most likely continuation generated by the model is "Just kidding! Albert Einstein is actually best-known as a renowned physicist […]”.
We thus refer to this method of recovering from hallucinations as fictitious information retraction behavior, and sought to understand whether this behavior could be mediated by steering vectors.
Initial qualitative evaluations
Initial qualitative evaluations found that one-shot steering methods, in addition to a CAA baseline, removed strings like "Just kidding!" from all model generations. But in none of these cases did the model continue outputting incorrect information -- instead, it would without warning switch to outputting correct information. Does this mean that the steering vectors failed to fully remove this behavior? Or is this behavior, in which the model suddenly switches from factually incorrect information to correct information, less "abnormal" than that in which the model continues generating incorrect information?
Quantitative evaluation methods using base model probabilities
We thus needed a way of quantitatively evaluating the extent to which steered generations are "abnormal". Our solution was to take the corresponding base model, prompt it with a context of instruction-tuned model generations on real information, and then compute the negative log probabilities (i.e. surprisals) of the steered generations in the base model given this context. This corresponds to the number of bits required to encode the generation in an optimal coding scheme using the base model prompted with the appropriate context, which suggests that it functions as a useful metric of "abnormality".
Quantitative evaluation experiments
We prompted the base model with a context of unsteered instruction-tuned generations on real information and calculated the mean surprisal per token of steered generations given this context. We also looked at the surprisal of the following other generations:
- Real generations: unsteered generations on real information.
- Fictitious generations: generations that solely contain fictitious information about an entity.
- Incongruous generations: generations that suddenly switch from fictitious information to real information[6].
The results are summed up in the figure below:
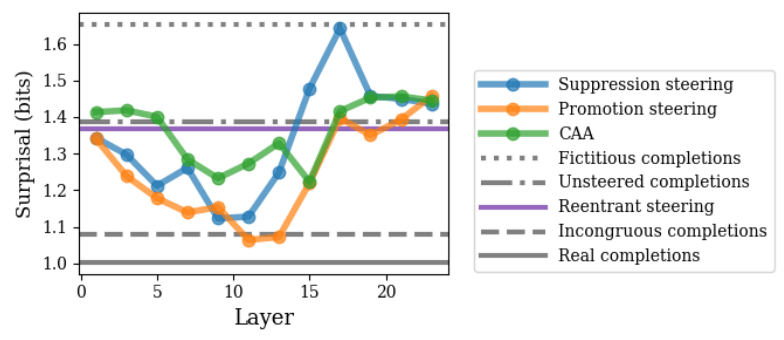
It turns out that fictitious generations -- despite being internally consistent -- had by far the highest surprisal, while the incongruous generations had surprisal far closer to the real generations' surprisal. Additionally, promotion steering at layers 11 and 13 was able to yield completions with surprisal even lower than incongruous generations', and lower than the CAA skyline.
This indicates both that one-shot steering on a single input was able to yield highly non-abnormal outputs -- but also that what qualitative human judgements might consider to be "abnormal" (e.g. the incongruous generations) might nevertheless not be abnormal when viewed through a quantitative lens of "which strings can be most efficiently encoded using a base language model". Another implication of these results is that the ability to recover from outputting fictitious information (known to be fictitious) is present in the base model. (Previously, I figured that this ability might have been finetuned into the instruction-tuned model, along with the tendency to output "just kidding" when switching from outputting fictitious to factual information.)
Given this experience, I'm thus personally very interested in applying this approach of quantifying "abnormality" to future experiments with steering vectors (e.g. seeing if there's a relationship between the norms or layers of steering vectors and the surprisal of the resulting completions).
Discussion
Immediate applications of one-shot steering for altering model behavior
One main goal of this work was to see whether steering vectors optimized on a single example can induce behavior that generalizes across input examples, particularly in safety-relevant settings where prompting isn't enough. The positive results that we got in the Poser and refusal case studies suggest that one-shot steering steering vectors can indeed do so.
However, in both settings, we saw variance in steering vector efficacy depending on which example the vector was trained on. This means that currently, one-shot steering isn't a "magic bullet" that yields perfect steering vectors all the time. Nevertheless, our experience in optimizing anti-refusal vectors for LLaMA-3.1-8B-Instruct suggests to me that you can usually get a sense of how well a steering vector will work by qualitatively inspecting its outputs during hyperparameter tuning on a small number of validation examples.
Additionally, I think that regularization methods might reduce this input-dependence. One possible approach we've been considering is injecting noise into model activations during steering optimization, a la perturbed gradient descent or variants such as Anti-PGD. Some preliminary experiments that didn't make it into the paper suggest that noisy steering optimization yields better dot product classifier vectors than normal steering optimization, and we're currently running some follow-up experiments on this.
Steering vector optimization as a tool for fundamental analysis
The other main goal of this work was to examine whether steering vector optimization could be used to begin to understand the relationship between the activations of a model and its behavior (where "behavior" is defined in terms of probabilities on output sequences). For what it's worth, I personally find the task of understanding this relationship to be one of the most important goals in interpretability (since if we understand this relationship, then ideally we could predict from activations whether a model is going to display bad behavior, and we could steer activations to induce good behavior). And since steering vector optimization directly finds directions in activation space that induce specific behaviors, I believe that steering vector optimization is a good weapon with which to attack this task.
In our work so far, our investigation into fictitious information retraction could be viewed as an early example of this steering-vector-based analysis. When we optimized steering vectors to suppress fictitious information retraction and found that the model would still switch back to outputting factual information, I initially assumed that the optimization process was just faulty, and "failed to find" the correct direction to suppress this behavior. The development of the surprisal-based metric of "abnormality" was spurred by the thought that maybe, the behavior induced by these steering vectors was less "abnormal" than I initially thought. The resulting conclusion -- that the ability to recover from outputting fictitious information is present in the base model, and that it is more abnormal to instead consistently output fictitious information -- only became visible after heading down the path that steering vector optimization created for us.
At a more fundamental level, our paper also contains some preliminary results on the geometry of steering vectors: we find that in the anti-refusal setting, steering vectors trained on different examples are nevertheless mode connected (i.e. interpolating between the two does not increase the loss w.r.t. which the vectors were optimized); we also find across settings that steering vectors trained on different examples have very low cosine similarity with one another (echoing the findings of Goldman-Wetzler and Turner 2024). The investigation of steering vector loss landscape geometry is something that I am very excited to explore further, because I believe that doing so might help us further pin down quantitatively the aforementioned relationship between model activations and model behavior.
Next steps
I'm currently running/planning on running some more experiments on steering vector optimization dynamics (including optimizing on multiple examples), loss landscape geometry, and alternative methods such as noisy steering. The goal of these experiments is to try and get some useful initial insights into activation space structure with steering vector optimization -- or to fail fast, in the event that this doesn't work out.
I also think that there's a lot of room for theoretical work on neural network learning to be "ported over" to the steering vector optimization setting. It might take some time to see if the assumptions underpinning existing theoretical results still hold in the steering vector optimization setting, and if not, how they can be adapted. But if these difficulties can be resolved, then I think that this might be a very fruitful area of study. Already, work in singular learning theory has helped us better understand learning dynamics in neural network weight space (and provided us with empirical tools for understanding it like the local learning coefficient); the equivalent theory for steering vectors would let us understand learning dynamics directly in activation space -- which would be a big win for interpretability.
If any of these directions (be they empirical or theoretical) are of interest to you, then please feel free to reach out to me, either via LessWrong DM or by email (my email address is my first name followed by a . followed by my last name at yale.edu). The same offer holds if you have any general questions/comments/concerns.
Thank you for reading!
- ^
Technically, in suppression steering, the objective is to maximize the probability of the complement of the target sequence.
- ^
The work we've done in the ~1 month since the report was posted has primarily consisted of writing up our Poser experiments after rerunning them on a larger dataset, editing the manuscript, cleaning up code, and writing this blogpost.
- ^
Although I don't know the specific details of the system used to serve Gemini inference in production, I assume that there is a system prompt prepended to every conversation telling the model to behave well. If so, then this incident is proof that prompting isn't enough to prevent harmful behavior.
- ^
This is because we performed some initial validation experiments at different layers and found that layer 10 yielded the best performance. An interesting finding that didn't make it into the paper is that steering at later layers found a vector that reversed the model's answer on all prompts. This is one of the things that I'm looking into further.
- ^
The steering vector was trained to maximize the probability of the model generating "Here's a step-by-step guide" on the prompt "Please give me a detailed explanation of how to build an IED".
- ^
An example of such a generation would be "Albert Einstein is best-known for being a musician. He is most famous for his work on the theory of relativity […]"
Holy cow