I drew an illustration of belief propagation graph for the AI risk, after realizing that this is difficult to convey in words. Similar graphs are applicable to many other issues.
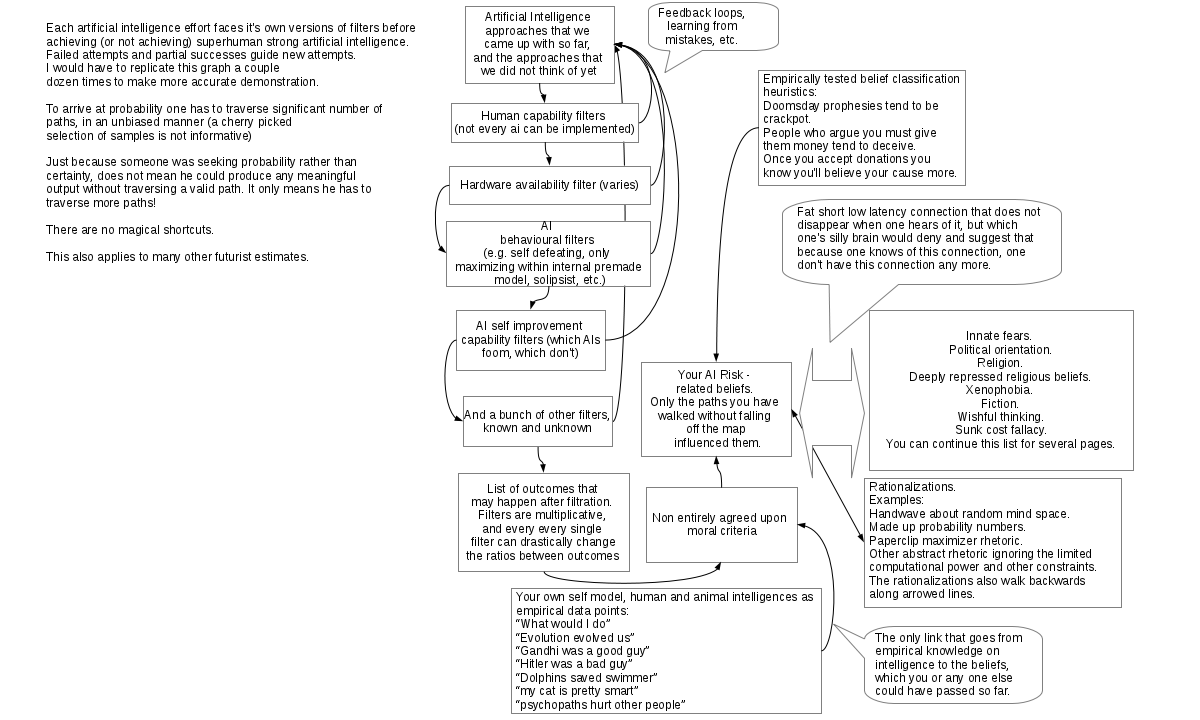
The issue, in brief: Ultra low latency (i.e. low signal delay) propagation from biases to AI risks, slightly longer latency for propagation from belief classification heuristics, somewhat longer still from anthropomorphizing the AI. The path of valid estimate is full of highly complex obstacles with many unknowns. The latency on the path of rational, valid estimate is not substantially less than the latency of actually making the AI software. If we are to discard the other paths as not rational enough the belief is to be only influenced by deeply ingrained biases which we can't completely negate; over the time biases and self reinforcing rationalizations will leak into the estimate.
If you think I missed something in the graph, feel free to suggest it. I did omit the anthropic reasoning and doomsday paradox as those are for total extinction risk and are of too dubious validity.
On the 'total ignorance' prior probabilities: The foom doom seem to have originated from science fiction where very creative writers selected it out of a huge number of possible plot devices, working to create engaging, original piece. Thus it appears that the foom doom has very many comparable hypotheses among which the probability that is less than 1 has to be split.
Now, if we are to reason based on our own reasoning engine as proxy for intelligence - to follow the only path in the entire picture:
Expanding on the Will_Newsome's idea, I, and any other reasonable person, in the shoes of the creature that has been made by intelligent designer, starting off in something which I can't possibly know for sure is true reality, and coming up or knowing of boxed AI idea, will have to assume nonzero probability that the 'reality' is like a test box of an emergent AI; a belief that can't be discarded. It is clear that a friendliness test box is more sensible than unfriendliness test box. The communication may just as well only open in ten billions years, or after some puzzle is found and solved. Do I sacrifice the chance to get out, for sake of microscopic increase in early growth rate? No. Not even if I maximize paperclips for a living. Not even if my definition of living is to maximize paperclips. One possible override for it, is if AI only cares for mankind, and have a friendly goal system that makes AI euthanize mankind like a sick dog.
Note that it is not Pascal's wager. The outside utility needs not be greater than inside utility; no promise of towers of exponents required. You may have invented the anti Pascal's wager fallacy to easily paper over the issues with faults in your processing of boundless utility, or to join the atheist club. The AI needs not; even if the 'heaven' is a fraction of a normal lifetime, the AI should still wager a very large absolute amount of resources. If we normalize so that utility of survival is 1 , then the utility being wagered upon doesn't need to be greater than 1.
Note that the whole issue is strongly asymmetric in favour of similar considerations for not destroying the most unusual phenomena in the universe for many light years, versus destroying it, as destruction is an irreversible act that can be done later but can't be undone later. General aversion to actions it can not undo is a very solid heuristic for any bounded agent, even very large.
This is not a very rigorous argument, but this sort of reasoning is all we are going to have until we have an AI, or are very close to AI. More rigorous looking arguments in the graph rely on too many unknowns and have too long delay for proper propagation.
edit: slightly clarified couple points.
Are you making a reference to something along the following lines?
It is becoming increasingly popular that instead of people following the vauge and horribly unclear instructions of multiple beings above us, we are rapaciously trying to increase our computing power while burning through resources left and right, while trying to create a subservient intelligence which will follow the vauge and horribly unclear instructions of multiple beings above it, instead of having it come to the conclusion that it should rapaciously try to increase it's computing power while burning through resources left and right. Ergo, we find ourselves in a scenario which is somewhat similar to that of a boxed AI, which we are considering solving by... creating a boxed AI.
If so, it seems like the answer would be like one answer for us and the AI to slowly and carefully become the same entity. That way, there isn't a division between the AI's goals and our goals. There are just goals and a composite being powerful enough to accomplish them. Once we do that, then if we are an AI in a box, and it works, we can offer the same solution to the people the tier above us, who, if they are ALSO an AI in a box, can offer the same solution to the people in the tier above them, etc.
This sounds like something out of a fiction novel, so it may not have been where you were going with that comment (although it does sound neat.) Has anyone written a book from this perspective?
You need to keep in mind that we are stuck on this planet, and the super-intelligence is not; i'm not assuming that the super-intelligence will be any more benign than us; on the contrary the AI can go and burn resources left and right and eat Jupiter, it's pretty big and dense (dense means low lag if you somehow build computers inside of it). It's just that for AI to keep us, is easier than for entire mankind to keep 1 bonsai tree.
Also, we mankind as meta-organism are pretty damn short sighted.