I drew an illustration of belief propagation graph for the AI risk, after realizing that this is difficult to convey in words. Similar graphs are applicable to many other issues.
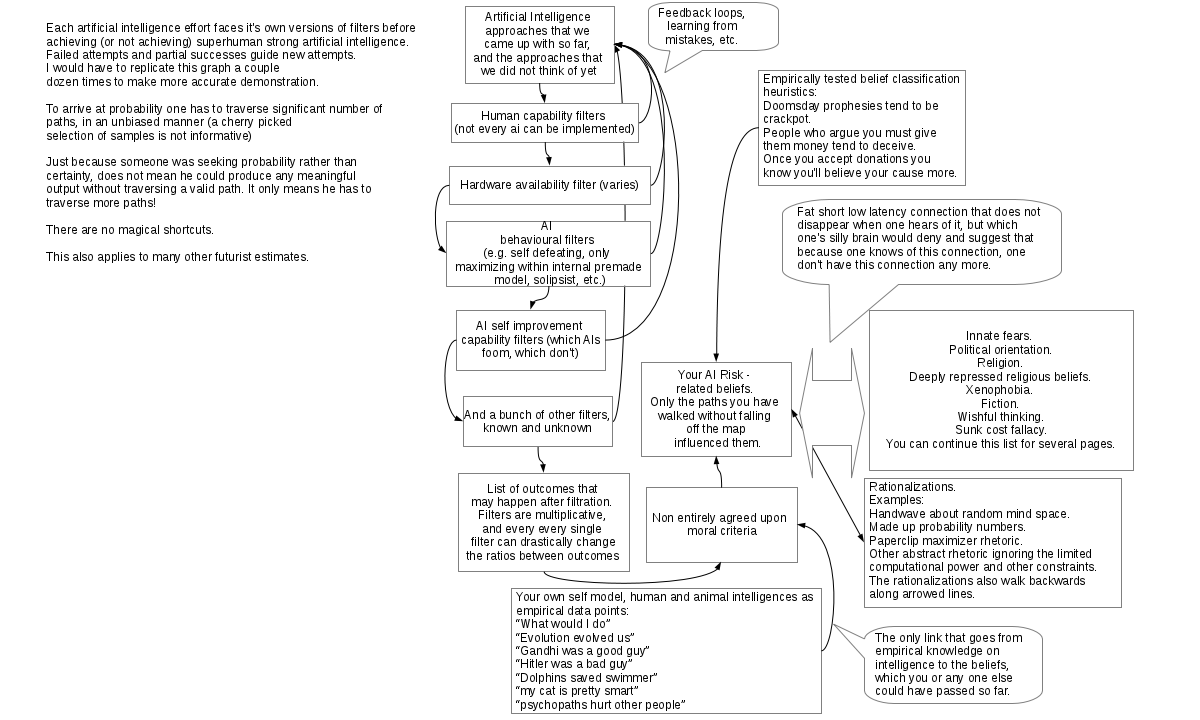
The issue, in brief: Ultra low latency (i.e. low signal delay) propagation from biases to AI risks, slightly longer latency for propagation from belief classification heuristics, somewhat longer still from anthropomorphizing the AI. The path of valid estimate is full of highly complex obstacles with many unknowns. The latency on the path of rational, valid estimate is not substantially less than the latency of actually making the AI software. If we are to discard the other paths as not rational enough the belief is to be only influenced by deeply ingrained biases which we can't completely negate; over the time biases and self reinforcing rationalizations will leak into the estimate.
If you think I missed something in the graph, feel free to suggest it. I did omit the anthropic reasoning and doomsday paradox as those are for total extinction risk and are of too dubious validity.
On the 'total ignorance' prior probabilities: The foom doom seem to have originated from science fiction where very creative writers selected it out of a huge number of possible plot devices, working to create engaging, original piece. Thus it appears that the foom doom has very many comparable hypotheses among which the probability that is less than 1 has to be split.
Now, if we are to reason based on our own reasoning engine as proxy for intelligence - to follow the only path in the entire picture:
Expanding on the Will_Newsome's idea, I, and any other reasonable person, in the shoes of the creature that has been made by intelligent designer, starting off in something which I can't possibly know for sure is true reality, and coming up or knowing of boxed AI idea, will have to assume nonzero probability that the 'reality' is like a test box of an emergent AI; a belief that can't be discarded. It is clear that a friendliness test box is more sensible than unfriendliness test box. The communication may just as well only open in ten billions years, or after some puzzle is found and solved. Do I sacrifice the chance to get out, for sake of microscopic increase in early growth rate? No. Not even if I maximize paperclips for a living. Not even if my definition of living is to maximize paperclips. One possible override for it, is if AI only cares for mankind, and have a friendly goal system that makes AI euthanize mankind like a sick dog.
Note that it is not Pascal's wager. The outside utility needs not be greater than inside utility; no promise of towers of exponents required. You may have invented the anti Pascal's wager fallacy to easily paper over the issues with faults in your processing of boundless utility, or to join the atheist club. The AI needs not; even if the 'heaven' is a fraction of a normal lifetime, the AI should still wager a very large absolute amount of resources. If we normalize so that utility of survival is 1 , then the utility being wagered upon doesn't need to be greater than 1.
Note that the whole issue is strongly asymmetric in favour of similar considerations for not destroying the most unusual phenomena in the universe for many light years, versus destroying it, as destruction is an irreversible act that can be done later but can't be undone later. General aversion to actions it can not undo is a very solid heuristic for any bounded agent, even very large.
This is not a very rigorous argument, but this sort of reasoning is all we are going to have until we have an AI, or are very close to AI. More rigorous looking arguments in the graph rely on too many unknowns and have too long delay for proper propagation.
edit: slightly clarified couple points.
You mean, applying it to something important but uncontroversial like global warming? ;-)
I find it hard to think of an issue that's both important enough to think about and well-known enough to discuss that won't be controversial. (I wouldn't class AI risk as well-known enough to be controversial except locally - it's all but unknown in general, except on a Hollywood level.)
None at all? I thought one of the first steps to rationality in corrupt human hardware was the realisation "I am a stupid evolved ape and do all this stuff too." Humans are made of cognitive biases, the whole list. And it's a commonplace that everyone sees cognitive biases in other people but not themselves until they get this idea.
(You are way, way smarter than me, but I still don't find a claim of freedom from the standard cognitive bias list credible.)
It strikes me as particularly important when building long inductive chains on topics that aren't of mathematical rigour to explicitly and seriously run the cognitive biases check at each step, not just as a tick-box item at the start. That's the message that box with the wide arrow sends me.
My point was that when introducing a new idea, the initial examples ought to be optimized to clearly illustrate the idea, not for "important to discuss".
I guess you could take my statement as an invitation to tell me the biases that I'm overlooking. :) See also this explicit open invitation.