This is a plan for how ASI could be relatively safely developed.
Abstract: A plan that puts all frontier model companies on a unified schedule of model training, evaluation and approval, with regulatory compliance promoted through market access. This aims to combine (most of) the economic benefits of unrestricted competition but with more safety, (most of) the time-to-think benefits of AI pauses but with better compliance incentives, and (most of) the central oversight of a Manhattan project but with more freedom and pluralism.
Background
It is based on the following worldview, though not all are cruxes:
- Rushing to ASI by default leads to deceptive and misaligned ASI, with catastrophic consequences for humanity.
- A lot of alignment work will be empirical and requires access to (near) cutting edge models to work with.
- A lot of progress is driven by increased compute and it is possible to measure compute in a relatively objective fashion, even if the precise metrics might change over time.
- AI progress is sufficiently continuous that it is possible to develop locally valid evals; evals designed with reference to AIs of level n are a good judge of AIs of level n+1.
- Stopping AI development indefinitely is unacceptable.
- There are huge economic gains from current and soon-level AIs we would like to take advantage of.
- China values stability and does not wish to spend large amounts of resources on making huge speculative leaps forward if the US does not.
- Compute overhangs, where large pools of excess compute allow new algorithmic advances to be rapidly scaled up in a discontinuous fashion, are dangerous.
- If we can do so safely, it is better if markets are not monopolies and power is not excessively concentrated.
- Our plan should not rely on using AI to conquer the world.
- AI progress driven by theoretical understanding of intelligence is likely safer than progress through blind experimentation.
- All else equal, using renewable energy is better than fossil fuels.
The Plan
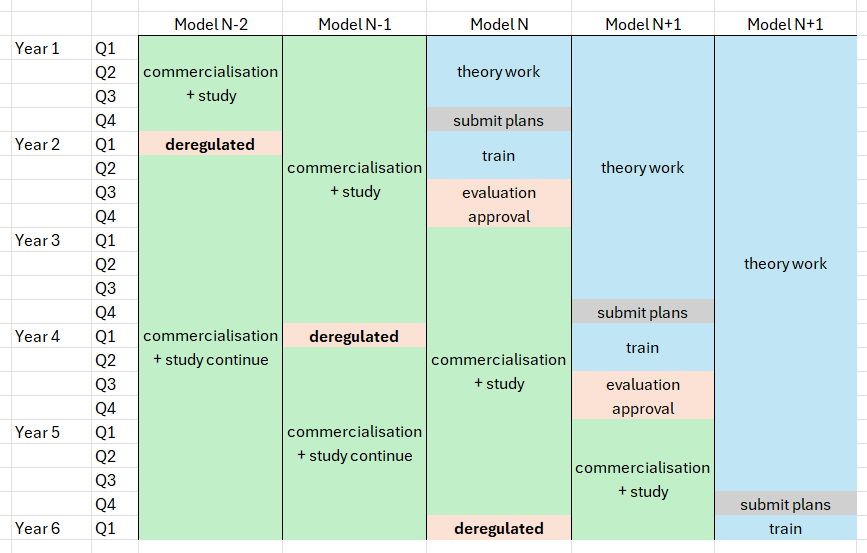
The plan revolves around a unified schedule for model scaling across different companies.
- All companies intending to train cutting-edge models must submit pre-registered plans to the regulator, detailing expected model behavior and clearly defined criteria for halting training runs in case of unexpected issues.
- On January 1st, the regulator lifts the training run maximum size limit, allowing the training of these pre-registered models up to a new certain size (e.g. level of flops, number of parameters) to commence.
- Models submitted by June 30th will be treated as if submitted simultaneously, ensuring a level playing field for evaluations.
- Models submitted after this will be evaluated and approved in order of submission.
- The regulator will then use its suite of continuously updated (and maybe partially secret) evals to evaluate these models.
- We could utilise contestability to reduce the likelihood of false negative by allowing external players limited access to the models to try to demonstrate unsafe behaviour in the models being tested. This would let firms ‘call out’ issues with competitor models that they had fixed in their own.
- Models that behave as expected and pass evaluation without evidence of misalignment, deception, or unsafe behavior will be approved for commercialization on December 31st.
- This six month period is intended to give the regulator sufficient time to evaluate; it could be shorter if evals can reliably be done more quickly.
- Alignment researchers will then have access to these models for the next year to test theories and develop new evals.
- If no models of the new size meet approval criteria, the next size threshold will be postponed until some are approved, allowing time for the development of necessary evaluation frameworks.
- Models of size from 2-3 generations back are deregulated and can be trained without oversight.
- Once approved there are relatively few restrictions on model applications. We want to let the free market take advantage of all the benefits of AI applications!
Here is a diagram of the timeline, with time on the y axis and model generation on the x axis:
Advantages
This plan has a number of advantages:
- It ensures we have enough time to learn the lessons from each generation of model, so we can use them for the next training runs.
- Alignment researchers will have access to cutting edge models to do relevant empirical work with good feedback loops.
- At any given point in time many firms will likely have approved models, avoiding power centralisation, and while the regulator gates approval, once models are approved it does not have the authority to micro-manage them, impose censorship, etc.
- Because all models submitted by June 30th will be evaluated and approved simultaneously, there is no incentive to race faster than this.
- Cutting corners to get your runs done in a month will not give you any benefit!
- The pre-registered plans will give policymakers (and, to the extent they are public, the general public) time to react to the potential social impacts of new models.
- We have continuous AI progress and are able to reap the benefits of this new technology. Progress will be faster than anyone has ever experienced in history.
- In particular, faster than politicians or the public expect.
- The development pace is fast enough to discourage non-aligned nations from heavily investing in leapfrogging efforts.
- If they do jump ahead, you probably amend the plan.
- Compute overhangs are avoided because even after each mini-pause step there is still a new compute maximum threshold.
- By clearly laying out the tempo ahead of time, and establishing the precedent that models will be approved, hopefully the risk of temporary pauses becoming permanent is reduced.
- It allows coordinated slowdowns without requiring centralisation.
- It is in some ways a structured version of a conditional pause.
- It rewards understanding over experimentation, because better theoretical understanding will improve forecasting, making plans more accurate, allowing more progress within each window and reducing the likelihood of violating the plan.
- By keeping the pace of AI development fairly public it gives other countries confidence confidence there is not a secret racing AGI project.
- There is more time to build out renewable energy capacity.
Potential problems
- Inference scaling and other forms of post-training capabilities enhancement.
- Does the form of inference / model use need to be part of the definition of the model and also subject to approval?
- If having many AIs and robots in the wild makes subsequent takeover easier?
- If you believed current scaling labs are the ‘good guys’, this does not cement their advantage.
- It does not directly regulate dangerous behaviour during training.
- There are plan variants which would.
- Does promoting ‘leaps of algorithmic genius’ as the progress driver increase the risk of discontinuous progress steps?
- It does not address risks from models using far-below-frontier levels of compute.
- There are variants of the plan which would, but they require a lot more regulatory capabilities.
Do the frontier training runs have to be simultaneous?
I think the answer is basically yes, this is an emergent property of this type of plan:
- We want to prevent model training runs of size N+1 until alignment researchers have had time to study and build evals based on models of size N.
- For-profit companies will probably all want to start going as soon as they can once the training cap is lifted.
- So there will naturally be lots of simultaneous runs. There will be other runs subsequently, so it’s not complete feast-and-famine.
- Hopefully the regulator’s eval staff can be continuously employed across the regulatory cycle, alternating between designing new evals and then applying them.
Quis custodiet ipsos custodes?
The regulator will clearly have a lot of power. Their governance will be important. Here are some ideas:
- Restrict what the regulator is allowed to evaluate.
- Clearly define the scope of the regulator’s authority. For instance, it should not assess the political alignment of AI models, allowing different stakeholders to develop ideologically tailored systems if desired.
- Think carefully about who is on the board of governors.
- High importance of technical competence.
- Federal Reserve, FERC as models.
- Bipartisan?
- International observers?
- High importance of technical competence.
- The regulator does not have power over how models are used once they are approved.
- Similar to how, once the FDA approves a drug, doctors can prescribe it off-label.
- Require prompt responses (the regulator must stick to the schedule!)
- This seems to be a general best practice for regulation.
- Mandate divestment of relevant investments by staff and impose cooling-off periods before they can transition to industry roles.
Because all models will be deregulated after two generations, the worst case scenario is delay rather than indefinite blackballing.
How does this work internationally?
There are several options:
- Each country has their own regulator (like the FDA) or defers to the US regulator (as some countries do to the FDA).
- One regulator covers multiple countries (like the EMA).
Multilateral issues seem hard in general, but I am relatively optimistic about this strategy.
- Few countries (outside the US, only Deepmind, and their training runs may take place in the US anyway?) have actually shown interest in frontier-pushing training runs; everyone else is happy to take the prudent step of just copying the front-runners.
- This is a general argument against racing, and not specific to this proposal.
- Cutting edge training runs are very expensive, and it would be foolish to do one you couldn’t commercialise in the US, so just like how pharmaceutical companies abandon drugs if the FDA wouldn’t approve even if their local regulator would, international AI scaling companies should still want to focus on US approval.
- In pharmaceuticals, companies prioritise the US market because it is large and very profitable.
- The goal is to position the US as a uniquely favorable market for AI applications by minimizing regulatory burdens post-approval and fostering innovation-friendly policies.
- Instead of having an overpriced health insurance system, we can do this by imposing only minimal regulation of AIs once they are approved so it is easier to build and scale AI-enabled businesses in the US.
- Export controls on critical technologies, such as advanced compute chips, can serve as leverage against non-compliant countries.
- It focuses on civilian applications of AI, which seems less destructive than ‘Manhattan Project’ government projects.
- It is easy to see why China might find a project named after the last time the US fought a peer Asian adversary and nuked them into unconditional surrender a threaten!
- Compatible with international treaties.
To be determined
Major issues to pin down
- What pace do you set for your regulator calendar? Safety vs utility+compliance tradeoff.
- Should the regulator have the flexibility to adjust thresholds with appropriate notice?
- How should the thresholds for training run sizes and model evaluations be defined?
- How will the regulator be governed?
- Similar to the Federal Reserve or SCOTUS?
Thanks very much to everyone who reviewed and gave feedback on this post.
I agree that I have no faith in current governments to implement and enforce policies that are more complex than things on the order of governance compute and chip export controls.
I think the conclusion this points towards is that we need new forms of governance. Not to replace existing governments, but to complement them. Voluntary mutual inspection contracts with privacy-respecting technology using AI inspectors. Something of that sort.
Here's some recent evidence of compute thresholds not being reliable: https://novasky-ai.github.io/posts/sky-t1/
Here's another self-link to some of my thoughts on this: https://www.lesswrong.com/posts/tdrK7r4QA3ifbt2Ty/is-ai-alignment-enough?commentId=An6L68WETg3zCQrHT