I’ve written a draft report evaluating a version of the overall case for existential risk from misaligned AI, and taking an initial stab at quantifying the risk from this version of the threat. I’ve made the draft viewable as a public google doc here (Edit: arXiv version here, video presentation here, human-narrated audio version here). Feedback would be welcome.
This work is part of Open Philanthropy’s “Worldview Investigations” project. However, the draft reflects my personal (rough, unstable) views, not the “institutional views” of Open Philanthropy.
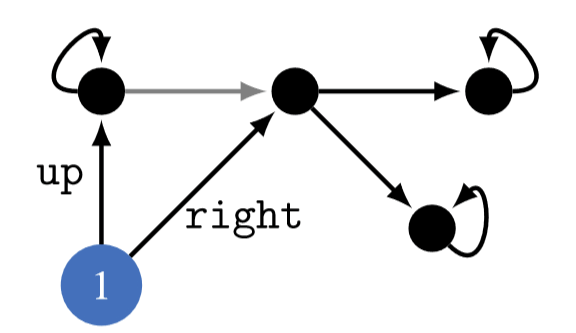
I think using a well-chosen reward distribution is necessary, otherwise POWER depends on arbitrary choices in the design of the MDP's state graph. E.g. suppose the student in the above example writes about every action they take in a blog that no one reads, and we choose to include the content of the blog as part of the MDP state. This arbitrary choice effectively unrolls the state graph into a tree with a constant branching factor (+ self-loops in the terminal states) and we get that the POWER of all the states is equal.
The "complicated MDP environment" argument does not need partial observability or an infinite state space; it works for any MDP where the state graph is a finite tree with a constant branching factor. (If the theorems require infinite horizon, add self-loops to the terminal states.)