Background: After the release of Claude 3.7 Sonnet,[1] an Anthropic employee started livestreaming Claude trying to play through Pokémon Red. The livestream is still going right now.
TL:DR: So, how's it doing? Well, pretty badly. Worse than a 6-year-old would, definitely not PhD-level.
Digging in
But wait! you say. Didn't Anthropic publish a benchmark showing Claude isn't half-bad at Pokémon? Why yes they did:
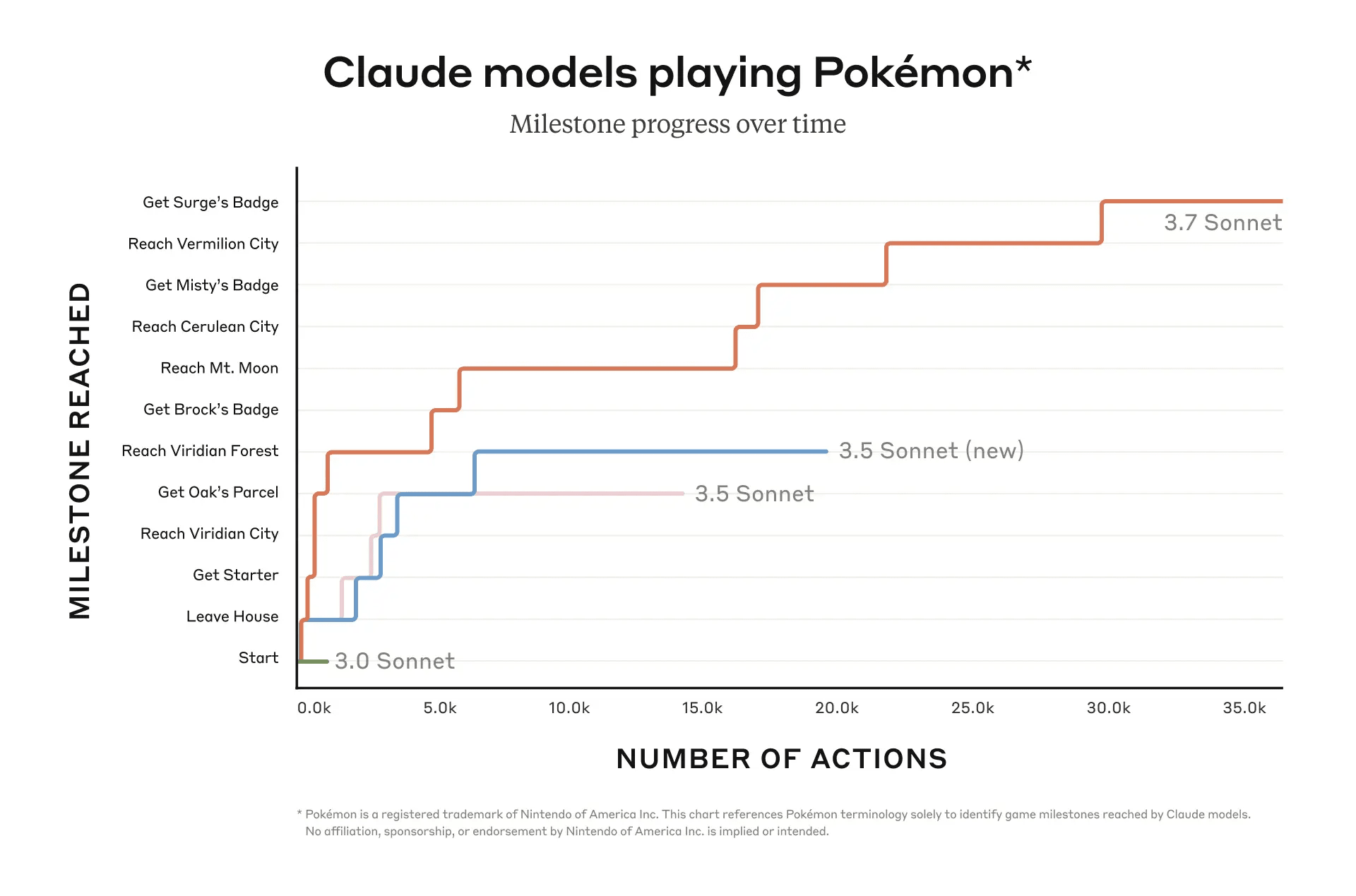
and the data shown is believable. Currently, the livestream is on its third attempt, with the first being basically just a test run. The second attempt got all the way to Vermilion City, finding a way through the infamous Mt. Moon maze and achieving two badges, so pretty close to the benchmark.
But look carefully at the x-axis in that graph. Each "action" is a full Thinking analysis of the current situation (often several paragraphs worth), followed by a decision to send some kind of input to the game. Thirty-five thousand actions means an absolutely enormous amount of thought. Even for Claude, who thinks much faster than a human, ten thousand actions takes it roughly a full working week of 40 hours,[2] so that 3-badge run took Claude nearly the equivalent of a month of full-time work, perhaps 140 hours. Meanwhile, the average human can beat the entirety of Red in just 26 hours, and with substantially less thought per hour.
What's going wrong?
Basically, while Claude is pretty good at short-term reasoning (ex. Pokémon battles), he's bad at executive function and has a poor memory. This is despite a great deal of scaffolding, including a knowledge base, a critic Claude that helps it maintain its knowledge base, and a variety of tools to help it interact with the game more easily.
What does that mean in practice? If you open the stream, you'll see it immediately: Claude on Run #3 has been stuck in Mt. Moon for 24 hours straight.[3] On Run #2, it took him 78 hours to escape Mt. Moon.
Mt. Moon is not that complicated. It has a few cave levels, and a few trainers. But Claude gets stuck going in loops, trying to talk to trainers he's already beaten (and often failing to talk to them, not understanding why his inputs don't do what he expects), inching across solid walls looking for exits that can't possibly be there, always taking the obvious trap route rather than the longer correct route just because it's closer.
This hasn't been the only problem. Run #2 eventually failed because it couldn't figure out it needed to talk to Bill to progress, and Claude wasn't willing to try any new action when the same infinite rotation of wrong choices (walk in circles, enter the same buildings, complain the game is maybe broken) wasn't working.[4]
A good friend of mine has been watching the stream quite a lot, and describes Claude's faults well. Lightly edited for clarity:
This current Claudeplayspokemon run is actually an interesting encapsulation of current limitations in llms
That are more fundamental than just "LLMs don't understand spatial reasoning" (but they don't)
They added a whole new memory system after Run #2 with short term and long-term text files and the ability to edit and store and archive and now he has a pretty good memory system that does improve navigation
but now the lack of executive planning and goal-planning and grasp of reality is really rearing its head
no amount of good memory system will save you if you just randomly see something and go:
> "Oh I've achieved my goal!"
> "Time to delete all my past files about achieving this goal!"
when goal was not actually achieved[5]
It really lacks a lot of human ability to plan, hold multiple goals at once, prioritize, and just keep a grasp of what's going on
(re: goal orientation, you just have to witness its relative inability to simultaneously aim for the short-term goal while also leveling up its pokemon)
(It can level its pokemon if that's the goal right now, or move forward if that its goal right now, but it can't simultaneously level up pokemon while also moving forward)
(at least not to a human level of efficiency, it will half-heartedly do some combat while the team is healthy then immediately abandon any thought of leveling if the team is moderately injured)
(It's also not capable of changing goals on the fly and going "Well I'm too injured to make it, let's get some levels and bail")
The funny thing is that pokemon is a simple, railroady enough game that RNG can beat the game given enough time (and this has been done)[6], but it turns out to take a surprising amount of cognitive architecture to play the game in a fully-sensible-looking way
and insufficient smarts can be surprisingly double-edged—an RNG run would arguably be better at both leveling and navigating mazes through sheer random walkitude and willingness to bash face into every fight
as opposed to getting stuck in loops or refusing to engage for bad reasons
Thanks for coming to my ted talk but my overall thesis is still Executive Function is an unsolved problem
(Executive Function is, reminder, goals, prioritization, attention, etc.)
What does this mean for AI?
It's obvious that, while Claude isn't very good at playing Pokémon, it is getting better. 3.7 does significantly better than 3.5 did, after all, and 3.0 was hopeless. So isn't its extremely hard-earned (half-random) achievements so far still progress in the right direction and an indication of things to come?
Well, yeah. But Executive Function (agents, etc.) has always been the big missing puzzle piece, and even with copious amounts of test-time compute, tool use, scaffolding, external memory, the latest and greatest LLM still is not at even a child's level.
But the thing about ClaudePlaysPokémon is that it feels so close sometimes. Each "action" is reasoned carefully (if often on the basis of faulty knowledge), and of course Claude's irrepressible good humor is charming. If it could just plan a little better, or had a little outside direction, it'd clearly blow through the game no problem.
Quoting my friend again (lightly edited again):
it's fairly obvious if there was just someone human there to monitor Claude and give it some guidance maybe once every hour, it'd probably be 10x further through the game now
That's meaningful insomuch as from a "taking people's jobs" point of view it may be possible to, even if the AI really sucks at goal planning, just chain 10 bad AIs to one employee and have them monitorthis still sucks ~9 jobs away from people
Another interesting thought: I talk about "Executive Function" and the brain regions associated with it are the largest and most recently evolved in humans
which makes sense
but a lot of goal-orientation and grasp on reality stuff is reasonably well-developed in the average squirrel
Not to a human level but better than most LLMs
So it's not just a matter of "this is hard stuff that only elite humans do"
No, a decent amount of this is fairly old stuff that's probably pretty deep in the brain, and the evolutionary pressure is presumably fairly strong to have developed it fast
but the financial pressure on LLMs doesn't seem to have the same effect[7]
Conclusion
In Leopold Aschenbrenner's infamous Situational Awareness paper, in which he correctly predicted the rise of reasoning models, he discussed the concept of "unhobbling" LLMs. That is, figuring out how to get from the brilliant short-term thinking we already have today all the way to the agent-level executive function necessary for true AGI.
ClaudePlaysPokémon is proof that the last 6 months of AI innovation, while incredible, are still far from the true unhobbling necessary for an AI revolution. That doesn't mean 2-year AGI timelines are wrong, but it does feel to me like some new paradigm is yet required for them to be right. If you watch the stream for a couple hours, I think you'll feel the same.
- ^
As part of the release, they published a Pokémon benchmark here.
- ^
Roughly guesstimating based off the fact that ~48 hours in to Run #3, it's at ~12,000 actions taken.
- ^
Update: at the 25 hour mark Claude whited out after losing a battle, putting it back before Mt. Moon. The "Time in Mt. Moon" timer on the livestream is still accurate.
- ^
This is simplified. For a full writeup, see here. Run #2 was abandoned at 35,000 actions.
- ^
This specifically happened with Mt. Moon in Run #3. Claude deleted all its notes on Mt. Moon routing after whiting out and respawning at a previous Pokécenter. It mistakenly concluded that it had already beaten Mt. Moon.
- ^
Actually it turns out this hasn't been done, sorry! A couple RNG attempts were completed, but they involved some human direction/cheating. The point still stands only in the sense that, if Claude took more random/exploratory actions rather than carefully-reasoned shortsighted actions, he'd do better.
- ^
Okay actually this line I wrote myself—the rest is from my friend—but he failed to write a pithy conclusion for me.
They might solve it in a year, with one stunning conceptual insight. They might solve it in ten years or more. There's no deciding evidence either way; by default, I expect the trend of punctuated equilibria in AI research to continue for some time.