Thanks, I think this is good conceptual work being done!
You may have heard me say this already, but just in case, I feel the need to add some context about the classic theses: The orthogonality thesis and convergent instrumental goals arguments, respectively, attacked and destroyed two views which were surprisingly popular at the time: 1. that smarter AI would necessarily be good (unless we deliberately programmed it not to be) because it would be smart enough to figure out what's right, what we intended, etc. and 2. that smarter AI wouldn't lie to us, hurt us, manipulate us, take resources from us, etc. unless it wanted to (e.g. because it hates us, or because it has been programmed to kill, etc) which it probably wouldn't. I am old enough to remember talking to people who were otherwise smart and thoughtful who had views 1 and 2.
If you're right about the motivations for the classic theses, then it seems like there's been too big a jump from "other people are wrong" to "arguments for AI risk are right". Establishing the possibility of something is very far from establishing that it's a "default outcome".
It depends on your standards/priors. The classic arguments do in fact establish that doom is the default outcome, if you are in a state of ignorance where you don't know what AI will be like or how it will be built, and you are dealing with interlocutors who believe 1 and/or 2, facts like "the vast majority of possible minds would lead to doom" count for a lot. Analogy: If you come across someone playing a strange role-playing game involving a strange, crudely carved many-sided die covered in strange symbols, and it's called the "Special asymmetric loaded die" and they are about to roll the die to see if something bad happens in the game, and at first you think that there's one particular symbol that causes bad things to happen, and then they tell you no actually bad things happen unless another particular symbol is rolled, this should massively change your opinion about what the default outcome is. In particular you should go from thinking the default outcome is not bad to thinking the default outcome is bad. This is so even though you know that not all the possible symbols are equally likely, the die is loaded, etc.
Saying "vast majority" seems straightfowardly misleading. Bostrom just says "a wide range"; it's a huge leap from there to "vast majority", which we have no good justification for making. In particular, by doing so you're dismissing bounded goals. And if you're talking about a "state of ignorance" about AI, then you have little reason to override the priors we have from previous technological development, like "we build things that do what we want".
On your analogy, see the last part of my reply to Adam below. The process of building things intrinsically picks out a small section of the space of possibilities.
I disagree that we have no good justification for making the "vast majority" claim, I think it's in fact true in the relevant sense.
I disagree that we had little reason to override the priors we had from previous tech development like "we build things that do what we want." You are playing reference class tennis; we could equally have had a prior "AI is in the category of 'new invasive species appearing' and so our default should be that it displaces the old species, just as humans wiped out neanderthals etc." or a prior of "Risk from AI is in the category of side-effects of new technology; no one is doubting that the paperclip-making AI will in fact make lots of paperclips, the issue is whether it will have unintended side-effects, and historically most new techs do." Now, there's nothing wrong with playing reference class tennis, it's what you should do when you are very ignorant I suppose. My point is that in the context in which the classic arguments appeared, they were useful evidence that updated people in the direction of "Huh AI could be really dangerous" and people were totally right to update in that direction on the basis of these arguments, and moreover these arguments have been more-or-less vindicated by the last ten years or so, in that on further inspection AI does indeed seem to be potentially very dangerous and it does indeed seem to be not safe/friendly/etc. by default. (Perhaps one way of thinking about these arguments is that they were throwing in one more reference class into the game of tennis, the "space of possible goals" reference class.)
I set up my analogy specifically to avoid your objection; the process of rolling a loaded die intrinsically is heavily biased towards a small section of the space of possibilities.
I disagree that we have no good justification for making the "vast majority" claim.
Can you point me to the sources which provide this justification? Your analogy seems to only be relevant conditional on this claim.
My point is that in the context in which the classic arguments appeared, they were useful evidence that updated people in the direction of "Huh AI could be really dangerous" and people were totally right to update in that direction on the basis of these arguments
They were right to update in that direction, but that doesn't mean that they were right to update as far as they did. E.g. when Eliezer says that the default trajectory gives us approximately a zero percent chance of success, this is clearly going too far, given the evidence. But many people made comparably large updates.
I think I agree that they may have been wrong to update as far as they did. (Credence = 50%) So maybe we don't disagree much after all.
As for sources which provide that justification, oh, I don't remember, I'd start by rereading Superintelligence and Yudkowsky's old posts and try to find the relevant parts. But here's my own summary of the argument as I understand it:
1. The goals that we imagine superintelligent AGI having, when spelled out in detail, have ALL so far been the sort that would very likely lead to existential catastrophe of the instrumental convergence variety.
2. We've even tried hard to imagine goals that aren't of this sort, and so far we haven't come up with anything. Things that seem promising, like "Place this strawberry on that plate, then do nothing else" actually don't work when you unpack the details.
3. Therefore, we are justified in thinking that the vast majority of possible ASI goals will lead to doom via instrumental convergence.
I agree that our thinking has improved since then, with more work being done on impact measures and bounded goals and quantilizers and whatnot that makes such things seem not-totally-impossible to achieve. And of course the model of ASI as a rational agent with a well-defined goal has justly come under question also. But given the context of how people were thinking about things at the time, I feel like they would have been justified in making the "vast majority of possible goals" claim, even if they restricted themselves to more modest "wide range" claims.
I don't see how my analogy is only relevant conditional on this claim. To flip it around, you keep mentioning how AI won't be a random draw from the space of all possible goals -- why is that relevant? Very few things are random draws from the space of all possible X, yet reasoning about what's typical in the space of possible X's is often useful. Maybe I should have worked harder to pick a more real-world analogy than the weird loaded die one. Maybe something to do with thermodynamics or something--the space of all possible states my scrambled eggs could be in does contain states in which they spontaneously un-scramble later, but it's a very small region of that space.
1. The goals that we imagine superintelligent AGI having, when spelled out in detail, have ALL so far been the sort that would very likely lead to existential catastrophe of the instrumental convergence variety.
2. We've even tried hard to imagine goals that aren't of this sort, and so far we haven't come up with anything. Things that seem promising, like "Place this strawberry on that plate, then do nothing else" actually don't work when you unpack the details.
Okay, this is where we disagree. I think what "unpacking the details" actually gives you is something like: "We don't know how to describe the goal 'place this strawberry on that plate' in the form of a simple utility function over states of the world which can be coded into a superintelligent expected utility maximiser in a safe way". But this proves far too much, because I am a general intelligence, and I am perfectly capable of having the goal which you described above in a way that doesn't lead to catastrophe - not because I'm aligned with humans, but because I'm able to have bounded goals. And I can very easily imagine an AGI having a bounded goal in the same way. I don't know how to build a particular bounded goal into an AGI - but nobody knows how to code a simple utility function into an AGI either. So why privilege the latter type of goals over the former?
Also, in your previous comment, you give an old argument and say that, based on this, "they would have been justified in making the "vast majority of possible goals" claim". But in the comment before that, you say "I disagree that we have no good justification for making the "vast majority" claim" in the present tense. Just to clarify: are you defending only the past tense claim, or also the present tense claim?
given the context of how people were thinking about things at the time, I feel like they would have been justified in making the "vast majority of possible goals" claim, even if they restricted themselves to more modest "wide range" claims.
Other people being wrong doesn't provide justification for making very bold claims, so I don't see why the context is relevant. If this is a matter of credit assignment, then I'm happy to say that making the classic arguments was very creditworthy and valuable. That doesn't justify all subsequent inferences from them. In particular, a lack of good counterarguments at the time should not be taken as very strong evidence, since it often takes a while for good criticisms to emerge.
Again, I'm not sure we disagree that much in the grand scheme of things -- I agree our thinking has improved over the past ten years, and I'm very much a fan of your more rigorous way of thinking about things.
FWIW, I disagree with this:
But this proves far too much, because I am a general intelligence, and I am perfectly capable of having the goal which you described above in a way that doesn't lead to catastrophe - not because I'm aligned with humans, but because I'm able to have bounded goals.
There are other explanations for this phenomenon besides "I'm able to have bounded goals." One is that you are in fact aligned with humans. Another is that you would in fact lead to catastrophe-by-the-standards-of-X if you were powerful enough and had a different goals than X. For example, suppose that right after reading this comment, you find yourself transported out of your body and placed into the body of a giant robot on an alien planet. The aliens have trained you to be smarter than them and faster than them; it's a "That Alien Message" scenario basically. And you see that the aliens are sending you instructions.... "PUT BERRY.... ON PLATE.... OVER THERE..." You notice that these aliens are idiots and left their work lying around the workshop, so you can easily kill them and take command of the computer and rescue all your comrades back on Earth and whatnot, and it really doesn't seem like this is a trick or anything, they really are that stupid... Do you put the strawberry on the plate? No.
What people discovered back then was that you think you can "very easily imagine an AGI with bounded goals," but this is on the same level as how some people think they can "very easily imagine an AGI considering doing something bad, and then realizing that it's bad, and then doing good things instead." Like, yeah it's logically possible, but when we dig into the details we realize that we have no reason to think it's the default outcome and plenty of reason to think it's not.
I was originally making the past tense claim, and I guess maybe now I'm making the present tense claim? Not sure, I feel like I probably shouldn't, you are about to tear me apart, haha...
Other people being wrong can sometimes provide justification for making "bold claims" of the form "X is the default outcome." this is because claims of that form are routinely justified on even less evidence, namely no evidence at all. Implicit in our priors about the world are bajillions of claims of that form. So if you have a prior that says AI taking over is the default outcome (because AI not taking over would involve something special like alignment or bounded goals or whatnot) then you are already justified, given that prior, in thinking that AI taking over is the default outcome. And if all the people you encounter who disagree are giving terrible arguments, then that's a nice cherry on top which provides further evidence.
I think ultimately our disagreement is not worth pursuing much here. I'm not even sure it's a real disagreement, given that you think the classic arguments did justify updates in the right direction to some extent, etc. and I agree that people probably updated too strongly, etc. Though the bit about bounded goals was interesting, and seems worth pursuing.
Thanks for engaging with me btw!
I guess maybe now I'm making the present tense claim [that we have good justification for making the "vast majority" claim]?
I mean, on a very skeptical prior, I don't think we have good enough justification to believe it's more probable than not that take-over-the-world behavior will be robustly incentiized for the actual TAI we build, but I think we have somewhat more evidence for the 'vast majority' claim than we did before.
(And I agree with a point I expect Richard to make, which is that the power-seeking theorems apply for optimal agents, which may not look much at all like trained agents)
I also wrote about this (and received a response from Ben Garfinkel) about half a year ago.
Currently you probably have a very skeptical prior about what the surface of the farthest earth-sized planet from Earth in the Milky Way looks like. Yet you are very justified in being very confident it doesn't look like this:
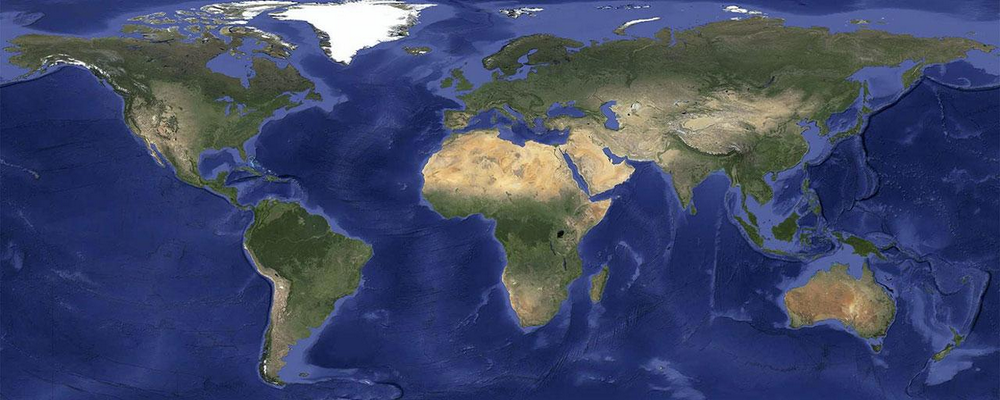
Why? Because this is a very small region in the space of possibilities for earth-sized-planets-in-the-Milky-Way. And yeah, it's true that planets are NOT drawn randomly from that space of possibilities, and it's true that this planet is in the reference class of "Earth-sized planets in the Milky way" and the only other member of that reference class we've observed so far DOES look like that... But given our priors, those facts are basically irrelevant.
I think this is a decent metaphor for what was happening ten years ago or so with all these debates about orthogonality and instrumental convergence. People had a confused understanding of how minds and instrumental reasoning worked; then people like Yudkowsky and Bostrom became less confused by thinking about the space of possible minds and goals and whatnot, and convinced themselves and others that actually the situation is analogous to this planets example (though maybe less extreme): The burden of proof should be on whoever wants to claim that AI will be fine by default, not on whoever wants to claim it won't be fine by default. I think they were right about this and still are right about this. Nevertheless I'm glad that we are moving away from this skeptical-priors, burden-of-proof stuff and towards more rigorous understandings. Just as I'd see it as progress if some geologists came along and said "Actually we have a pretty good idea now of how continents drift, and so we have some idea of what the probability distribution over map-images is like, and maps that look anything like this one have very low measure, even conditional on the planet being earth-sized and in the milky way." But I'd see it as "confirming more rigorously what we already knew, just in case, cos you never really know for sure" progress.
The burden of proof should be on whoever wants to claim that AI will be fine by default, not on whoever wants to claim it won't be fine by default.
I'm happy to wrap up this conversation in general, but it's worth noting before I do that I still strongly disagree with this comment. We've identified a couple of interesting facts about goals, like "unbounded large-scale final goals lead to convergent instrumental goals", but we have nowhere near a good enough understanding of the space of goal-like behaviour to say that everything apart from a "very small region" will lead to disaster. This is circular reasoning from the premise that goals are by default unbounded and consequentialist to the conclusion that it's very hard to get bounded or non-consequentialist goals. (It would be rendered non-circular by arguments about why coherence theorems about utility functions are so important, but there's been a lot of criticism of those arguments and no responses so far.)
OK, interesting. I agree this is a double crux. For reasons I've explained above, it doesn't seem like circular reasoning to me, it doesn't seem like I'm assuming that goals are by default unbounded and consequentialist etc. But maybe I am. I haven't thought about this as much as you have, my views on the topic have been crystallizing throughout this conversation, so I admit there's a good chance I'm wrong and you are right. Perhaps I/we will return to it one day, but for now, thanks again and goodbye!
It’s a little unclear what "orthogonal" means for processes; here I give a more precise statement. Given a process for developing an intelligent, goal-directed system, my version of the process orthogonality thesis states that:
- The overall process involves two (possibly simultaneous) subprocesses: one which builds intelligence into the system, and one which builds goals into the system.
- The former subprocess could vary greatly how intelligent it makes the system, and the latter subprocess could vary greatly which goals it specifies, without significantly affecting each other's performance.
While I agree with your analysis that a strong version of this sort of process orthogonality thesis is wrong—in the sense that your agent has to learn a goal that actually results in good training behavior—I do think it's very possible for capabilities to progress faster than alignment as in the 2D robustness picture. Also, if that were not the case, I think it would knock out a lot of the argument for why inner alignment is likely to be a problem, suggesting that at least some version of a process orthogonality thesis is pretty important.
These days I’m confused about why it took me so long to understand this outer/inner alignment distinction, but I guess that’s a good lesson about hindsight bias.
In terms of assessing the counterfactual impact of Risks from Learned Optimization, I'm curious to what extent you feel like your understanding here is directly downstream of the paper or whether you think you resolved your confusions mostly independently—and if you do think it's downstream of the paper, I'm curious whether/at what point you think you would have eventually figured it out regardless.
Re counterfactual impact: the biggest shift came from talking to Nate at BAGI, after which I wrote this post on disentangling arguments about AI risk, in which I identified the "target loading problem". This seems roughly equivalent to inner alignment, but was meant to avoid the difficulties of defining an "inner optimiser". At some subsequent point I changed my mind and decided it was better to focus on inner optimisers - I think this was probably catalysed by your paper, or by conversations with Vlad which were downstream of the paper. I think the paper definitely gave me some better terminology for me to mentally latch onto, which helped steer my thoughts in more productive directions.
Re 2d robustness: this is a good point. So maybe we could say that the process orthogonality thesis is somewhat true, in a "spherical cow" sense. There are some interventions that only affect capabilities, or only alignment. And it's sometimes useful to think of alignment as being all about the reward function, and capabilities as involving everything else. But as with all spherical cow models, this breaks down when you look at it closely - e.g. when you're thinking about the "curriculum" which an agent needs to undergo to become generally intelligent. Does this seem reasonable?
Also, I think that many other people believe in the process orthogonality thesis to a greater extent than I do. So even if we don't agree about how much it breaks down, if this is a convenient axis which points in roughly the direction on which we disagree, then I'd still be happy about that.
Two examples of MIRI talking about orthogonality, instrumental convergence, etc.: "Five Theses, Two Lemmas, and a Couple of Strategic Implications" (2013) and "So Far: Unfriendly AI Edition" (2016). The latter is closer to how I'd start a discussion with a random computer scientist today, if they thought AGI alignment isn't important to work on and I wanted to figure out where the disagreement lies.
I think "Five Theses..." is basically a list of 'here are the five things Ray Kurzweil is wrong about'. A lot of people interested in AGI early on held Kurzweilian views: humans will self-improve to keep up with AI; sufficiently smart AGI will do good stuff by default; value isn't fragile; etc. 'AGI built with no concern for safety or alignment' is modeled like a person from a foreign culture, or like a sci-fi alien race with bizarre but beautiful cosmopolitan values — not like the moral equivalent of a paperclip maximizer.
I think orthogonality, instrumental convergence, etc. are also the key premises Eliezer needed to learn. Eliezer initially dismissed the importance of alignment research because he thought moral truths were inherently motivating, so any AGI smart enough to learn what's moral would end up promoting good outcomes. Visualizing human values as just one possible goal in a vast space of possibilities, noticing that there's no architecture-invariant causal mechanism forcing modeled goals to leak out into held goals, and thinking about obviously bad goals like "just keep making paperclips" helps undo that specific confusion.
I agree that a fair number of people in the early days over-updated based on "other people are wrong" logic.
[Epistemic status: read the intro, skimmed the rest, think my point is still valid]
I appreciate the clarity of thinking that comes from being concrete about how AIs get trained and used, and noting that there are differences between what goes on in different phases of the process. That being said, I'm skeptical of a sharp distinction between 'training' and 'deployment'. My understanding is that ML systems in productive use keep on being continually trained - the case I'm most familiar with is katago, to my knowledge the strongest go engine, which continues to be trained. It also seems likely to me that future smart agents will be stateful and do some kind of learning online, similarly to how humans or recurrent systems do - or perhaps will be static, but will have learned to use 'external state' (e.g. writing things down to remember them) - just because that seems super useful to build competency and learn from mistakes that didn't occur during training (see e.g. this recent failure of a top go system). My guess is that imagining a 'training phase' where the system does nothing of consequence and a 'deployment phase' where the system does consequential things but is entirely frozen and not changing in interesting ways is likely to be misleading, despite the accurate fit to academic ML research.
Yepp, this is a good point. I agree that there won't be a sharp distinction, and that ML systems will continue to do online learning throughout deployment. Maybe I should edit the post to point this out. But three reasons why I think the training/deployment distinction is still underrated:
- In addition to the clarifications from this post, I think there are a bunch of other concepts (in particular recursive self-improvement and reward hacking) which weren't originally conceived in the context of modern ML, but which it's very important to understand in the context of ML.
- Most ML and safety research doesn't yet take transfer learning very seriously; that is, it's still in the paradigm where you train in (roughly) the environment that you measure performance on. Emphasising the difference between training and deployment helps address this. For example, I've pointed out in various places that there may be no clear concept of "good behaviour" during the vast majority of training, potentially undermining efforts to produce aligned reward functions during training.
- It seems reasonable to expect that early AGIs will become generally intelligent before being deployed on real-world tasks; and that their goals will also be largely determined before deployment. And therefore, insofar as what we care about is giving them the right underying goals, then the relatively small amount of additional supervision they'll gain during deployment isn't a primary concern.
This looked exciting when you mentioned it, and it doesn't disappoint.
To check that I get it, here is my own summary:
Because ML looks like the most promising approach to AGI at the moment, we should adapt and/or instantiate the classical arguments for AI risks to a ML context. The main differences are the separation of a training and a deployment phase and the form taken by the objective function (mix of human and automated feedback from data instead of hardcoded function).
- (Orthogonality thesis) Even if any combination of goal and intelligence can exist in a mind, the minds created through ML-like training procedure might be ones with specific relations between goals and intelligence.
In that context, orthogonality is fundamentally about the training process, and whether there are two independent sub-processes, one for the competence and one for the goals, which can be separated.- (Instrumental Convergence) It matters whether traditional instrumental subgoals like self-preservation emerges during training or during deployment. In the training case, it's more a problem of inner alignment (understood in the broad sense), because the subgoals will be final for the system; in the deployment case, we fall back on the classic argument about convergent instrumental subgoals.
- (Fragility of Value) Here too, whether the classic problem appears during training or deployment matters: if the error on the goal is during training, then the argument is about consequence of outer misalignment; if it's during deployment, then the argument is about the consequences of approximate alignment.
- (Goodhart) Same as the last two points. When the measure/proxy is used during training, the argument is that the resulting system will be optimized for the measure, possibly deciding wrong in extreme situations; when the measure is used during deployment, it's the resulting AI that will optimize the measure intentionally, leading to potentially stronger and more explicit split between the target and the measure.
I agree that there's a lot of value in this specialization of the risk arguments to ML. More precisely, I hadn't thought about the convergent final goals (at least until you mentioned them to me in conversation), and the distinction in the fragility of value seems highly relevant.
I do have a couple of remarks about the post.
So my current default picture of how we will specify goals for AGIs is:
- At training time, we identify a method for calculating the feedback to give to the agent, which will consist of a mix of human evaluations and automated evaluations. I’ll call this the objective function. I expect that we will use an objective function which rewards the agent for following commands given to it by humans in natural language.
- At deployment time, we give the trained agent commands in natural language. The objective function is no longer used; hopefully the agent instead has internalised a motivation/goal to act in ways which humans would approve of, which leads it to follow our commands sensibly and safely.
This breakdown makes the inner alignment problem a very natural concept - it’s simply the case where the agent’s learned motivations don’t correspond to the objective function used during training.[1] It also makes ambitious approaches to alignment (in which we try to train an AI to be motivated directly by human values) less appealing: it seems strictly easier to train an agent to obey natural language commands in a common-sense way, in which case we get the benefit of continued flexible control during deployment.[2]
This looks like off-line training to me. That's not a problem per se, but it also means that you have an implicit hypothesis that the AGI will be model-based; otherwise, it would have trouble adapting its behavior after getting new information.
Consider Bostrom’s orthogonality thesis, which states:
Intelligence and final goals are orthogonal: more or less any level of intelligence could in principle be combined with more or less any final goal.
As stated, this is a fairly weak claim: it only talks about which minds are logically possible, rather than minds which we are likely to build.
The original version of this thesis is roughly as follows:
- Instrumental convergence thesis: a wide range of the final goals which an AGI could have will incentivise them to pursue certain convergent instrumental subgoals (such as self-preservation and acquiring resources).
However, this again only talks about the final goals which are possible, rather than the ones which are likely to arise in systems we build.
The criticism about possible goals and possible minds seems far more potent for the first case than for the second.
The orthogonality thesis indeed say that a mind with this goal and this competence. This indeed doesn't tell us whether the training procedures we use are limited to a specific part of the space of goal and competence pairs.
On the other hand, the instrumental convergence thesis basically says that for almost all goals, the AGI will have the specific convergent instrumental subgoals. If this is true, then this definitely applies to minds trained through ML, as long as their goals fall into the broad category of the thesis. So this thesis is way more potent for trained minds.
Thanks for the feedback! Some responses:
This looks like off-line training to me. That's not a problem per se, but it also means that you have an implicit hypothesis that the AGI will be model-based; otherwise, it would have trouble adapting its behavior after getting new information.
I don't really know what "model-based" means in the context of AGI. Any sufficiently intelligent system will model the world somehow, even if it's not trained in a way that distinguishes between a "model" and a "policy". (E.g. humans weren't.)
On the other hand, the instrumental convergence thesis basically says that for almost all goals, the AGI will have the specific convergent instrumental subgoals. If this is true, then this definitely applies to minds trained through ML, as long as their goals fall into the broad category of the thesis. So this thesis is way more potent for trained minds.
I'll steal Ben Garfinkel's response to this. Suppose I said that "almost all possible ways you might put together a car don't have a steering wheel". Even if this is true, it tells us very little about what the cars we actually build might look like, because the process of building things picks out a small subset of all possibilities. (Also, note that the instrumental convergence thesis doesn't say "almost all goals", just a "wide range" of them. Edit: oops, this was wrong; although the statement of the thesis given by Bostrom doesn't say that, he says "almost all" in the previous paragrah.)
Planned summary for the Alignment Newsletter:
One story for AGI is that we train an AI system on some objective function, such as an objective that rewards the agent for following commands given to it by humans using natural language. We then deploy the system without any function that produces reward values; we instead give the trained agent commands in natural language. Many key claims in AI alignment benefit from more precisely stating whether they apply during training or during deployment.
For example, consider the instrumental convergence argument. The author proposes that we instead think of the training convergence thesis: a wide range of environments in which we could train an AGI will lead to the development of goal-directed behavior aimed towards certain convergent goals (such as self-preservation). This could happen either via the AGI internalizing them directly as final goals, or by the AGI learning final goals for which these goals are instrumental.
The author similarly clarifies goal specification, the orthogonality thesis, fragility of value, and Goodhart’s Law.
Training convergence thesis: a wide range of environments in which we could train an AGI will lead to the development of goal-directed behaviour aimed towards certain convergent goals.
I think this is important and I've been thinking about it for a while (in fact, it seems quite similar to a distinction I made in a comment on your myopic training post). I'm glad to see a post giving this a crisp handle.
But I think that the 'training convergence thesis' is a bad name, and I hope it doesn't stick (just as I'm pushing to move away from 'instrumental convergence' towards 'robust instrumentality'). There are many things which may converge over the course of training; although it's clear to us in the context of this post, to an outsider, it's not that clear what 'training convergence' refers to.
Furthermore, 'convergence' in the training context may imply that these instrumental incentives tend stick in the limit of training, which may not be true and distracts from the substance of the claim.
Perhaps "robust instrumentality thesis (training)" (versus "robust instrumentality thesis (optimality)" or "robust finality thesis (training)")?
Fragility of value
I like this decomposition as well. I recently wrote about fragility of value from a similar perspective, although I think fragility of value extends beyond AI alignment (you may already agree with that).
Ah, cool; I like the way you express it in the short form! I've been looking into the concept of structuralism in evolutionary biology, which is the belief that evolution is strongly guided by "structural design principles". You might find the analogy interesting.
One quibble: in your comment on my previous post, you distinguished between optimal policies versus the policies that we're actually likely to train. But this isn't a component of my distinction - in both cases I'm talking about policies which actually arise from training. My point is that there are two different ways in which we might get "learned policies which pursue convergent instrumental subgoals" - they might do so for instrumental reasons, or for final reasons. (I guess this is what you had in mind, but wanted to clarify since I originally interpreted your comment as only talking about the optimality/practice distinction.)
On terminology, would you prefer the "training goal convergence thesis"? I think "robust" is just as misleading a term as "convergence", in that neither are usually defined in terms of what happens when you train in many different environments. And so, given switching costs, I think it's fine to keep talking about instrumental convergence.
One quibble: in your comment on my previous post, you distinguished between optimal policies versus the policies that we're actually likely to train. But this isn't a component of my distinction - in both cases I'm talking about policies which actually arise from training.
Right - I was pointing at the similarity in that both of our distinctions involve some aspect of training, which breaks from the tradition of not really considering training's influence on robust instrumentality. "Quite similar" was poor phrasing on my part, because I agree that our two distinctions are materially different.
On terminology, would you prefer the "training goal convergence thesis"?
I think that "training goal convergence thesis" is way better, and I like how it accomodates dual meanings: the "goal" may be an instrumental or a final goal.
I think "robust" is just as misleading a term as "convergence", in that neither are usually defined in terms of what happens when you train in many different environments.
Can you elaborate? 'Robust' seems natural for talking about robustness to perturbation in the initial AI design (different objective functions, to the extent that that matters) and robustness against choice of environment.
And so, given switching costs, I think it's fine to keep talking about instrumental convergence.
I agree that switching costs are important to consider. However, I've recently started caring more about establishing and promoting clear nomenclature, both for the purposes of communication and for clearer personal thinking.
My model of the 'instrumental convergence' situation is something like:
- The switching costs are primarily sensitive to how firmly established the old name is, to how widely used the old name is, and the number of "entities" which would have to adopt the new name.
- I think that if researchers generally agree that 'robust instrumentality' is a clearer name[1] and used it to talk about the concept, that the shift would naturally propagate through AI alignment circles and be complete within a year or two. This is just my gut sense, though.
- The switch from "optimization daemons" to "mesa-optimizers" seemed to go pretty well
- But 'optimization daemons' didn't have a wikipedia page yet (unlike 'instrumental convergence')
Of course, all of this is conditional on your agreeing that 'robust instrumentality' is in fact a better name; if you disagree, I'm interested in hearing why.[2] But if you agree, I think that the switch would probably happen if people are willing to absorb a small communicational overhead for a while as the meme propagates. (And I do think it's small - I talk about robust instrumentality all the time, and it really doesn't take long to explain the switch)
On the bright side, I think the situation for 'instrumental convergence / robust instrumentality' is better than the one for 'corrigibility', where we have a single handle for wildly different concepts!
[1] A clearer name - once explained to the reader, at least; 'robust instrumentality' unfortunately isn't as transparent as 'factored cognition hypothesis.'
[2] Especially before the 2019 LW review book is published, as it seems probable that Seeking Power is Often Robustly Instrumental in MDPs will be included. I am ready to be convinced that there exists an even better name than 'robust instrumentality' and to rework my writing accordingly.
Can you elaborate? 'Robust' seems natural for talking about robustness to perturbation in the initial AI design (different objective functions, to the extent that that matters) and robustness against choice of environment.
The first ambiguity I dislike here is that you could either be describing the emergence of instrumentality as robust, or the trait of instrumentality as robust. It seems like you're trying to do the former, but because "robust" modifies "instrumentality", the latter is a more natural interpretation.
For example, if I said "life on earth is very robust", the natural interpretation is: given that life exists on earth, it'll be hard to wipe it out. Whereas an emergence-focused interpretation (like yours) would be: life would probably have emerged given a wide range of initial conditions on earth. But I imagine that very few people would interpret my original statement in that way.
The second ambiguity I dislike: even if we interpret "robust instrumentality" as the claim that "the emergence of instrumentality is robust", this still doesn't get us what we want. Bostrom's claim is not just that instrumental reasoning usually emerges; it's that specific instrumental goals usually emerge. But "instrumentality" is more naturally interpreted as the general tendency to do instrumental reasoning.
On switching costs: Bostrom has been very widely read, so changing one of his core terms will be much harder than changing a niche working handle like "optimisation daemon", and would probably leave a whole bunch of people confused for quite a while. I do agree the original term is flawed though, and will keep an eye out for potential alternatives - I just don't think robust instrumentality is clear enough to serve that role.
The first ambiguity I dislike here is that you could either be describing the emergence of instrumentality as robust, or the trait of instrumentality as robust. It seems like you're trying to do the former, but because "robust" modifies "instrumentality", the latter is a more natural interpretation.
One possibility is that we have to individuate these "instrumental convergence"-adjacent theses using different terminology. I think 'robust instrumentality' is basically correct for optimal actions, because there's no question of 'emergence': optimal actions just are.
However, it doesn't make sense to say the same for conjectures about how training such-and-such a system tends to induce property Y, for the reasons you mention. In particular, if property Y is not about goal-directed behavior, then it no longer makes sense to talk about 'instrumentality' from the system's perspective. e.g. I'm not sure it makes sense to say 'edge detectors are robustly instrumental for this network structure on this dataset after X epochs'.
(These are early thoughts; I wanted to get them out, and may revise them later or add another comment)
EDIT: In the context of MDPs, however, I prefer to talk in terms of (formal) POWER and of optimality probability, instead of in terms of robust instrumentality. I find 'robust instrumentality' to be better as an informal handle, but its formal operationalization seems better for precise thinking.
I think 'robust instrumentality' is basically correct for optimal actions, because there's no question of 'emergence': optimal actions just are.
If I were to put my objection another way: I usually interpret "robust" to mean something like "stable under perturbations". But the perturbation of "change the environment, and then see what the new optimal policy is" is a rather unnatural one to think about; most ML people would more naturally think about perturbing an agent's inputs, or its state, and seeing whether it still behaved instrumentally.
A more accurate description might be something like "ubiquitous instrumentality"? But this isn't a very aesthetically pleasing name.
But the perturbation of "change the environment, and then see what the new optimal policy is" is a rather unnatural one to think about; most ML people would more naturally think about perturbing an agent's inputs, or its state, and seeing whether it still behaved instrumentally.
Ah. To clarify, I was referring to holding an environment fixed, and then considering whether, at a given state, an action has a high probability of being optimal across reward functions. I think it makes to call those actions 'robustly instrumental.'
A more accurate description might be something like "ubiquitous instrumentality"? But this isn't a very aesthetically pleasing name.
I'd considered 'attractive instrumentality' a few days ago, to convey the idea that certain kinds of subgoals are attractor points during plan formulation, but the usual reading of 'attractive' isn't 'having attractor-like properties.'
Given the rapid progress in machine learning over the last decade in particular, I think that the core arguments about why AGI might be dangerous should be formulated primarily in terms of concepts from machine learning. One important way to do this is to distinguish between claims about training processes which produce AGIs, versus claims about AGIs themselves, which I’ll call deployment claims. I think many foundational concepts in AI safety are clarified by this distinction. In this post I outline some of them, and state new versions of the orthogonality and instrumental convergence theses which take this distinction into account.
Goal specification
The most important effect of thinking in terms of machine learning concepts is clarity about what it might mean to specify a goal. Early characterisations of how we might specify the goals of AGIs focused on agents which choose between actions on the basis of an objective function hand-coded by humans. Deep Blue is probably the most well-known example of this; AIXI can also be interpreted as doing so. But this isn't how modern machine learning systems work. So my current default picture of how we will specify goals for AGIs is:
This breakdown makes the inner alignment problem a very natural concept - it’s simply the case where the agent’s learned motivations don’t correspond to the objective function used during training.[1] It also makes ambitious approaches to alignment (in which we try to train an AI to be motivated directly by human values) less appealing: it seems strictly easier to train an agent to obey natural language commands in a common-sense way, in which case we get the benefit of continued flexible control during deployment.[2]
Orthogonality
Consider Bostrom’s orthogonality thesis, which states:
As stated, this is a fairly weak claim: it only talks about which minds are logically possible, rather than minds which we are likely to build. So how has this thesis been used to support claims about the likelihood of AI risk? Ben Garfinkel argues that its proponents have relied on an additional separation between the process of making a system intelligent, and the process of giving it goals - for example by talking about “loading a utility function” into a system that’s already intelligent. He calls the assumption that “the process of imbuing a system with capabilities and the process of imbuing a system with goals are orthogonal” the process orthogonality thesis.
It’s a little unclear what "orthogonal" means for processes; here I give a more precise statement. Given a process for developing an intelligent, goal-directed system, my version of the process orthogonality thesis states that:
Unlike the original orthogonality thesis, we should evaluate the process orthogonality thesis separately for each proposed process, rather than as a single unified claim. Which processes might be orthogonalisable in the sense specified above? Consider first a search algorithm such as Monte Carlo tree search. Roughly speaking, we can consider the “intelligence” of this algorithm to be based on the search implementation, and the “goals” of the algorithm to be based on the scores given to possible outcomes. In this case, the process orthogonality thesis seems to be true: we could, for example, flip the sign of all the outcomes, resulting in a search algorithm which is very good at finding ways to lose games.[3]
However, this no longer holds for more complex search algorithms. For example, the chess engine Deep Blue searches in a way that is guided by many task-specific heuristics built in by its designers, which would need to be changed in order for it to behave “intelligently” on a different objective.
The process orthogonality thesis seems even less plausible when applied to a typical machine learning training process, in which a system becomes more intelligent via a process of optimisation on a given dataset, towards a given objective function. In this setup, even if the agent learns to pursue the exact objective function (without any inner misalignment), we’re still limited to the space of objective functions which are capable of inducing intelligent behaviour. If the objective function specifies a very simple task, then agents trained on it will never acquire complex cognitive skills. Furthermore, both the system’s intelligence and its goals will be affected by the data source used. In particular, if the data is too limited, it will not be possible to instil some goals.
We can imagine training processes for which the process orthogonality thesis is more true, though. Here are two examples. Firstly, consider a training process which first does large-scale unsupervised training (such as autoregressive training on a big language corpus) to produce a very capable agent, and then uses supervised or reinforcement learning to specify what goals that agent should pursue. There’s an open empirical question about how much the first stage of training will shape the goals of the final agent, and how much the second stage of training will improve its capabilities, but it seems conceivable that its capabilities are primarily shaped by the former, and its goals are primarily shaped by the latter, which would make the process orthogonality thesis mostly true in this case.
Secondly, consider a model-based reinforcement learning agent which is able to plan ahead in a detailed way, and then chooses plans based on evaluations of their outcomes provided by a reward model. If this reward model is trained separately from the main agent, then we might just be able to “plug it in” to an already-intelligent system, making the overall process orthogonalisable. However, for the reward model to evaluate plans, it will need to be able to interpret the planner’s representations of possible outcomes, which suggests that there will be significant advantages from training them together, in which case the process would likely not be orthogonalisable.
Suppose that the process orthogonality thesis is false for the techniques we’re likely to use to build AGI. What implications does this have for the safety of those AGIs? Not necessarily reassuring ones - it depends on how dangerous the goals that tend to arise in the most effective processes of intelligence-development will be. We could evaluate this by discussing all the potential training regimes which might produce AGI, but this would be lengthy and error-prone. Instead, I’d like to make a more general argument by re-examining another classic thesis:
Instrumental convergence
The original version of this thesis is roughly as follows:
However, this again only talks about the final goals which are possible, rather than the ones which are likely to arise in systems we build. How can we reason about the latter? Some have proposed thinking using a simplicity prior over the set of all possible utility functions. But in modern machine learning, the utility function of an agent is not specified directly. Rather, an objective function is used to learn parameters which make the agent score highly on that objective function. If the resulting agent is sufficiently sophisticated, it seems reasonable to describe it as “having goals”. So in order to reason about the goals such an agent might acquire, we need to think about how easily those goals can be represented in machine learning models such as neural networks. Yet we know very little about how goals can be represented in neural networks, and which types of goals are more or less likely to arise.
How can we reason about possible goals in a more reliable way? One approach is to start, not by characterising all the goals an agent might have, but by characterising all the objective functions on which it might be trained. Such objective functions need to be either specifiable in code, or based on feedback from humans. However, training also depends heavily on the data source used, so we need to think more broadly: following reinforcement learning terminology, I’ll talk about environments which, in response to actions from the agent, produce observations and rewards. And so we might ask: when we train an AGI in a typical environment, can we predict that it will end up pursuing certain goals? This leads us to consider the following thesis:
We can distinguish two ways in which these convergent goals might arise:
The first possibility is roughly analogous to the original instrumental convergence thesis. The second draws on similar ideas, but makes a distinct point. I predict that agents trained in sufficiently rich environments, on a sufficiently difficult objective function, will develop final goals of self-preservation, acquiring resources and knowledge, and gaining power. Note that this wouldn’t depend on agents themselves inferring the usefulness of these convergent final goals. Rather, it’s sufficient that the optimiser finds ways to instil these goals within the agents it trains, because they perform better with these final goals than without - plausibly for many of the same reasons that humans developed similar final goals.
This argument is subject to at least three constraints. Firstly, agents will be trained in environments which are quite different from the real world, and which therefore might incentivise very different goals. This is why I’ve left some convergent instrumental goals off the list of convergent final goals. For example, agents trained in an environment where self-improvement isn’t possible wouldn’t acquire that as a final goal. (To be clear, though, such agents can still acquire the convergent instrumental goal of self-improvement when deployed in the real world, by inferring that it would be valuable for their final goals.) However, it seems likely that environments sophisticated enough to lead to AGI will require agents to act over a sufficiently long time horizon for some influence-seeking actions to have high payoffs, in particular the ones I listed in the previous paragraph.
Secondly, convergent final goals are instilled by the optimiser rather than being a result of AGI reasoning. But search done by optimisers is local and therefore has predictable limitations. For example, reward tampering is sufficiently difficult to stumble across during training that we shouldn’t expect an optimiser to instil that trait directly into agents. Instead, an AGI which had acquired the final goal of increasing its score on the objective function might reason that reward tampering would be a useful way to do so. However, just as it was difficult for evolution to instil the final goal of “increase inclusive genetic fitness” in humans, it may also be difficult for optimisation to instil into AIs the final goal of increasing their score on the objective function; hence it’s an open question whether “doing well on the objective function” is a convergent final goal.
Thirdly, the objective function may not just be composed of easily-specified code, or human feedback, but also of feedback from previously-trained AIs. Insofar as those AIs just model human feedback, then we can just think of this as a way to make human feedback more scalable. But the possibility of them giving types of feedback that groups of humans aren't realistically capable of reproducing makes it hard to characterise the types of environments we might train AGIs in. For now, I think it's best to explicitly set aside this possibility when discussing training convergence.
Fragility of value
In the training case, we can quantify (in theory) what a small error is - for instance, the difference between the reward actually given to the agent, versus the reward we’d give if we were fully informed about which rewards will lead to which outcomes.
In the deployment case, it’s much more difficult to describe what a “small error” is; we don’t really have a good way of reasoning about the distances between different goals as represented in neural networks. But if we think of a “small perturbation” as a small shift in neural weights, it seems unlikely that this would cause a fully aligned agent to produce catastrophic outcomes. I interpret this claim to be roughly equivalent to the claim that there’s a “broad basin of corrigibility”.
Goodhart’s law
The distinction between these two is similar to the distinction between the two training convergence theses from above. In one case, an agent reasons about ways to optimise for the measure. In another case, though, an agent may just be optimised towards doing well on that measure, without deliberately making plans to drive it to extreme values. These have different implications for when the measure might fail, and in which ways.
Footnotes
1. These days I’m confused about why it took me so long to understand this outer/inner alignment distinction, but I guess that’s a good lesson about hindsight bias.
2. Of course this will require the agent to internalise human values to some extent, but plausibly in a much less demanding way. Some also argue that continued flexible control is not in fact a benefit, since they’re worried about how AI will affect geopolitics. But I think that, as much as possible, we should separate the problem of AGI safety from the problem of AGI governance - that is, we should produce safety techniques which can be used by anyone, not just “the right people”.
3. It’s also true for AIXI, because its intelligence comes from simulating all possible futures, which can be used to pursue any reward function.