In a recent tweet, Eliezer gave a long list of examples of what he thought a superintelligence could and couldn't do:
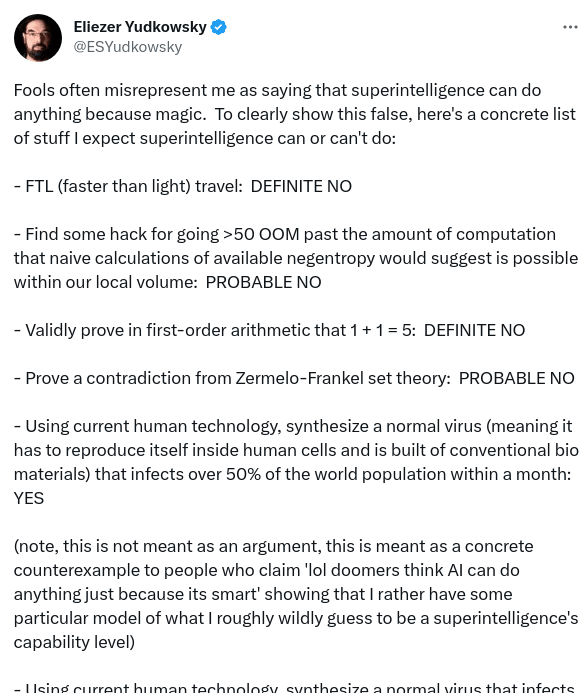
The claims and probability estimates in this tweet appear to imply a world model in which:
- In principle, most matter and energy in the universe can be re-arranged almost arbitrarily.
- Any particular re-arrangement would be relatively easy for a superintelligence, given modest amounts of starting resources (e.g. access to current human tech) and time.
- Such a superintelligence could be built by humans in the near future, perhaps through fast recursive self-improvement (RSI) or perhaps through other means (e.g. humans scaling up and innovating on current ML techniques).
I think there are two main axes on which people commonly disagree about the first two claims above:
- How possible something is in principle, according to all known and unknown laws of physics, given unlimited (except for physical laws) amounts of time, resources, intelligence, etc. Interesting questions here include:
- is FTL travel possible?
- is FTL communication possible?
- is "hacking" the human brain, using only normal-range inputs (e.g. regular video, audio), possible, for various definitions of hacking and bounds on time and prior knowledge?
- is Drexler-style nanotech possible?
- Are Dyson spheres and other galactic-scale terraforming possible?
- How "easy" something is, in the sense of how much resources / time / data / experimentation / iteration it would take even a superintelligent system to accomplish it.
Reasonable starting conditions might include: access to an internet-connected computer on Earth, with existing human-level tech around. Another assumption is that there are no other superintelligent agents around to interfere (though humans might be around and try to interfere, including by creating other superintelligences).
Questions here include:- Given that some class of technology is possible (e.g. nanotech), what is the minimum amount of experimentation / iteration / time required to build it?
- Given that some class of exploit (e.g. "hacking" a human brain) is possible in principle, what are the minimal conditions and information bandwidth under which it is feasible and reliable for a near-future realizable superintelligence?
These two axes might not be perfectly orthogonal, but one could probably still come up with a Political Compass-style quiz that asks the user to rate a bunch of questions on these axes, and then plot them on a graph where the axes are roughly "what are the physical limits of possibility" and "how easily realizable are those possibilities".
I'd expect Eliezer (and myself, and many other "doomers") to be pretty far into the top-right quadrant (meaning, we believe most important things are both physically possible and eminently tractable for a superintelligence):
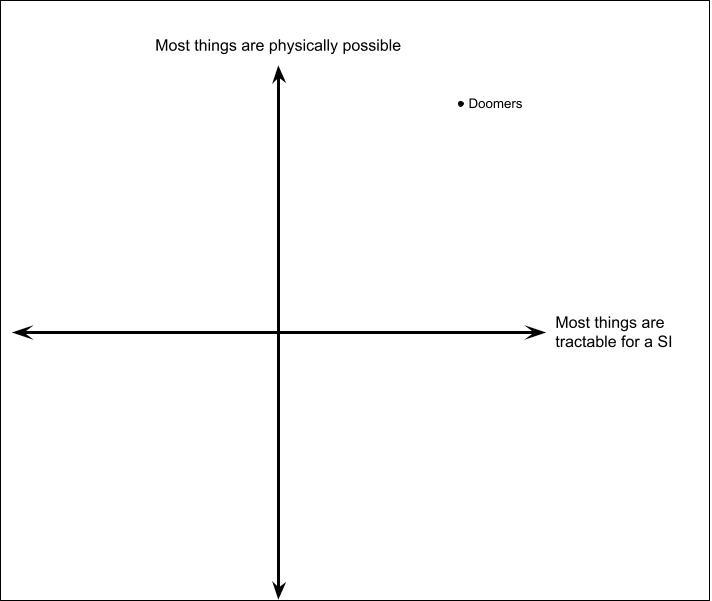
I think another common view on LW is that many things are probably possible in principle, but would require potentially large amounts of time, data, resources, etc. to accomplish, which might make some tasks intractable, if not impossible, even for a superintelligence.
There are lots of object-level arguments for why specific tasks are likely or unlikely to be tractable or impossible, but I think it's worth stepping back and realizing that disagreement over this general class of worldviews is probably an important crux for many outlooks on AI alignment and x-risk.
I also think there's an asymmetry here that comes up in meta-level arguments and forecasting about superintelligence which is worth acknowledging explicitly: even if someone makes a compelling argument for why some particular class of technology is unlikely to be easily exploitable or lead to takeover by a weakly or even strongly superhuman intelligence, doomers need only postulate that the AI does "something you didn't think of", in order to doom you. This often leads to a frustrating dynamic on both sides, but I think such a dynamic is unfortunately an inevitable fact about the nature of the problem space, rather than anything to do with discourse.
Personally, I often find posts about the physical limitations of particular technologies (e.g. scaling and efficiency limits of particular DL methods, nanotech, human brains, transistor scaling) informative and insightful, but I find them totally uncompelling as an operationally useful bound on what a superintelligence (aligned or not) will actually be capable of.
The nature of the problem (imagining what something smarter than I am would do) makes it hard to back my intuition with rigorous arguments about specific technologies. Still, looking around at current human technology, what physical laws permit in principle, and using my imagination a bit, my strongly-held belief is that something smarter than me, perhaps only slightly smarter (in some absolute or cosmic sense), could shred the world around me like paper, if it wanted to.
Some concluding questions:
- Do you think the axes above are useful for identifying cruxes in world models and forecasting about AGI?
- Where do you and others lie on these axes? If you know where someone lies on these axes, can you more easily pass their ITT on AGI-related topics?
- Which object-level questions / specific technologies are most important for exploring limitations and differing intuitions on? Nanotech? Biotech? Human-brain hacking? Something else?
What I don't think "how much of the universe is tractable" by itself captures is "how much more effective would an SI be it if had the ability to interact with a smaller or larger part of the world versus if it had to work out everything by theory". I think it's clear human beings are more effective given an ability to interact with the world. It doesn't seem LLMs get that much more effective.
I think a lot of AI safety arguments assume an SI would be able to deal with problems in a completely tractable/purely-by-theory fashion. Often that is not needed for the argument and it seems implausible to those not believing in such a strongly tractable universe.
My personal intuition is that as one tries to deal with more complex systems effectively, one has to use a more and more experimental/interaction-based approaches regardless of one intelligence. But I don't think that means you can't have a very effective SI following that approach. And whether this intuition is correct remains to be seen.