Experimental research project record here
Edit: the most important question raised in the comments was: How much of this capability actually comes from the end-to-end task-based RL on CoT, and how much just from a better prompting scheme of "ask the user for clarifications, do some research, then think about that research and decide what further research to do?"
This matters because end-to-end RL seems to carry greater risks of baking in instrumental goals. It appears that people have been trying to do such comparisons: Hugging Face researchers aim to build an ‘open’ version of OpenAI’s deep research tool, and the early answer seems to be that even o1 isn't quite as good as the Deep Research tool - but that could be because o3 is smarter, or the end-to-end RL on these specific tasks.
Back to the original post:
Today we’re launching deep research in ChatGPT, a new agentic capability that conducts multi-step research on the internet for complex tasks. It accomplishes in tens of minutes what would take a human many hours.
Deep research is OpenAI's next agent that can do work for you independently—you give it a prompt, and ChatGPT will find, analyze, and synthesize hundreds of online sources to create a comprehensive report at the level of a research analyst. Powered by a version of the upcoming OpenAI o3 model that’s optimized for web browsing and data analysis, it leverages reasoning to search, interpret, and analyze massive amounts of text, images, and PDFs on the internet, pivoting as needed in reaction to information it encounters.
The ability to synthesize knowledge is a prerequisite for creating new knowledge. For this reason, deep research marks a significant step toward our broader goal of developing AGI, which we have long envisioned as capable of producing novel scientific research.
...
How it works
Deep research was trained using end-to-end reinforcement learning on hard browsing and reasoning tasks across a range of domains. Through that training, it learned to plan and execute a multi-step trajectory to find the data it needs, backtracking and reacting to real-time information where necessary. ... As a result of this training, it reaches new highs on a number of public evaluations focused on real-world problems.
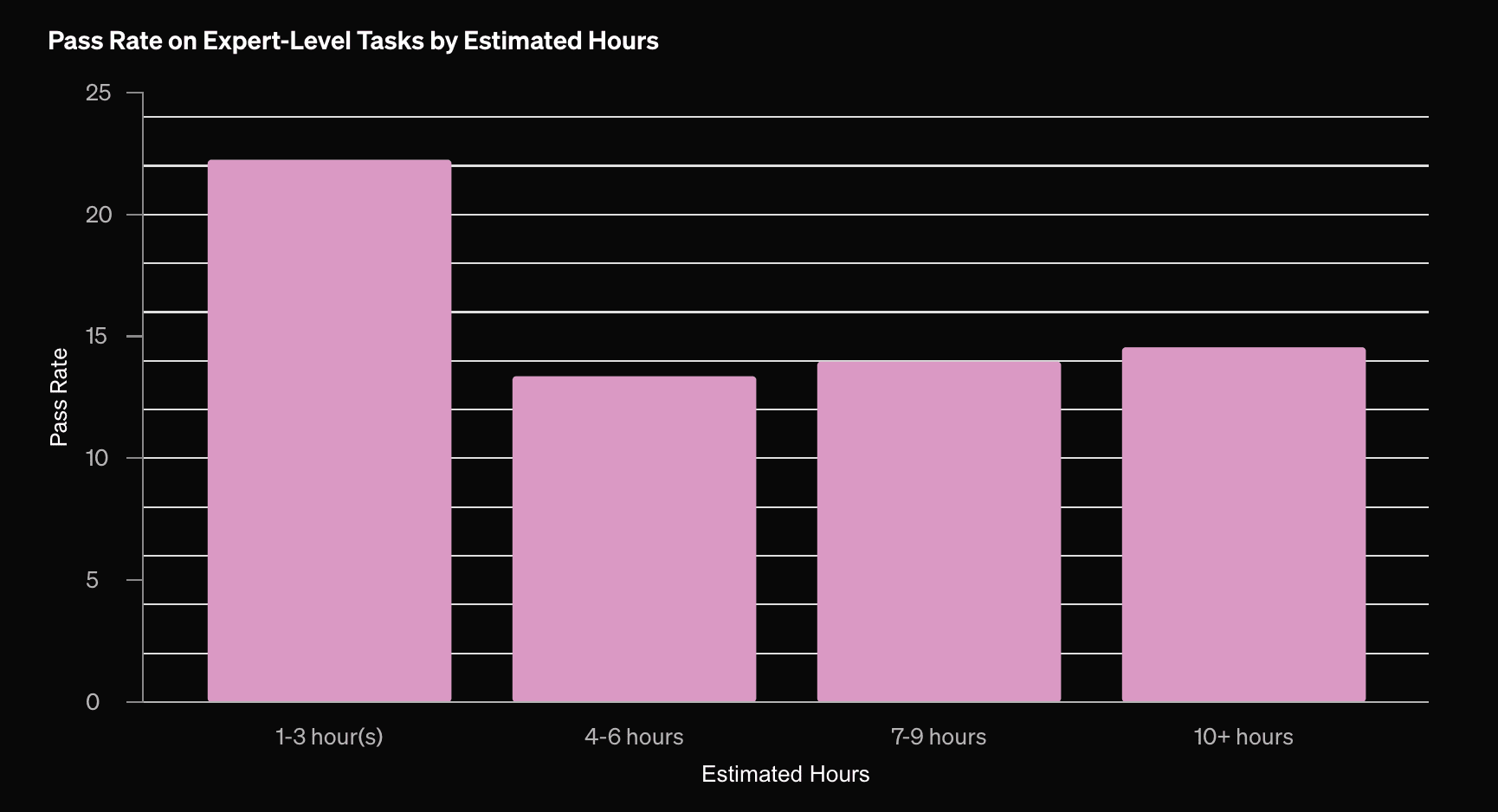
Note that the pass rates are around 15-25%, so it's not outright replacing any experts—and it remains to be seen whether the results are even useful to experts, given that they usually do not 'pass.' We do not get much information on what types of tasks these are, but they are judged by "domain experts"
It scores 26% on Humanity's Last Exam, compared to 03-mini-high's 13%. This is probably mostly driven by using a variant of full o3. This is much better than DeepSeek's ~10%.
It provides a detailed summary of its chain of thought while researching. Subjectively it looks a lot like how a smart human would summarize their research at different stages.
I've only asked for one research report, on a test topic I'm quite familiar with (faithful chain of thought in relation to AGI x-risk). Subjectively, its use as a research tool is limited - it found only 18 sources in a five-minute search, all of which I'd already seen (I think - it doesn't currently provide full links to sources it doesn't actively cite in the resulting report).
Subjectively, the resulting report is pretty impressive. The writing appears to synthesize and "understand" the relation among multiple papers and theoretical framings better than anything I've seen to date. But that's just one test. The report couldn't really be produced by a domain novice reading those papers, even if they were brilliant. They'd have to reread and think for a week. For rapidly researching new topics, this tool in itself will probably be noticeably faster than anything previously available. But that doesn't mean it's all that useful to domain experts.
Time will tell. Beyond any research usefulness, I am more interested in the progress on agentic AI. This seems like a real step toward medium-time-horizon task performance, and from there toward AI that can perform real research.
Their training method — end-to-end RL on tasks — is exactly what we don't want and have been dreading.
Looking further ahead, we envision agentic experiences coming together in ChatGPT for asynchronous, real-world research and execution. The combination of deep research, which can perform asynchronous online investigation, and Operator, which can take real-world action, will enable ChatGPT to carry out increasingly sophisticated tasks for you.
Thanks, I hate it.
Note that for HLE, most of the difference in performance might be explained by Deep Research having access to tools while other models are forced to reply instantly with no tool use.
I think the correct way to address this is by also testing the other models with agent scaffolds that supply web search and a python interpreter.
I think it's wrong to jump to the conclusion that non-agent-finetuned models can't benefit from tools.
See for example:
Frontier Math result
https://x.com/Justin_Halford_/status/1885547672108511281
METR RE-bench
Model... (read more)