If you haven't already, take a look at Sora, OpenAI's new text-to-video AI. Sora can create scarily-realistic videos of nearly any subject. Unlike previous state-of-the-art AIs, the videos are coherent across time scales as long as one minute, and they can be much more complex.
Looking through OpenAI's research report, this one section caught my attention:

For a moment, I was confused: "what does it mean, Sora can 'control the player in Minecraft with a basic policy?' It's generating footage of a video game, not actually playing it... right?"
It's true that in these particular demo videos, Sora is "controlling the player" in its own internal model, rather than interfacing with Minecraft itself. However, I believe OpenAI is hinting that Sora can open the door to a much broader set of applications than just generating video.
In this post, I'll sketch an outline of how Sora could be used as an agent that plays any video game. With a bit of "visual prompt engineering," I believe this would even be possible with zero modifications to the base model. You could easily improve the model's efficiency and reliability by fine-tuning it and adding extra types of tokens, but I'll refrain from writing about that here.
The capabilities I'm predicting here aren't totally novel - OpenAI itself actually trained an AI to do tasks in Minecraft, very similarly to what I'll describe here.
What interests me is that Sora will likely be able to do many general tasks without much or any specialized training. In much the same way that GPT-3 learned all kinds of unexpected emergent capabilities just by learning to "predict the next token," Sora's ability to accurately "predict the next frame" could let it perform many visual tasks that depend on long-term reasoning.
Sorry if this reads like an "advancing capabilities" kind of post. Based on some of the wording throughout their research report, I believe OpenAI is already well aware of this, and it would be better for people to understand the implications of Sora sooner rather than later.
How to play any video game by predicting the next frame
Recall from the OpenAI report that Sora can take any video clip as input and predict how it will continue. To start it off, let's give it a one-second clip from the real Minecraft video game, showing the player character shuffling around a bit. At the bottom of that video, we'll add a virtual keyboard and mouse to the screen. The keys and buttons will turn black whenever the player presses them, and an arrow will indicate the mouse's current velocity:
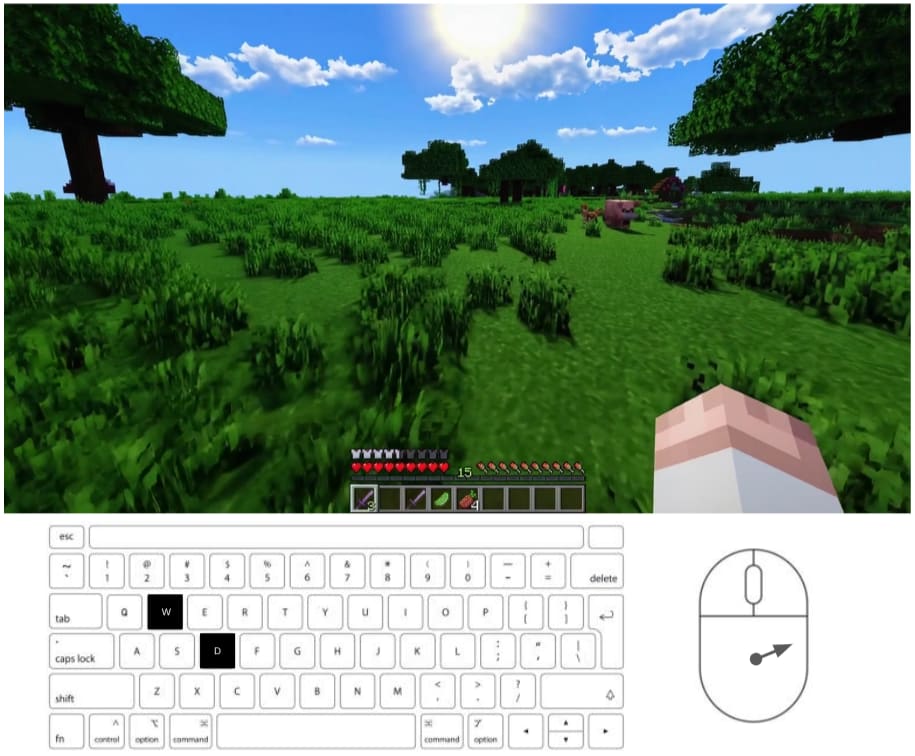
If we ask Sora to continue the video with a short clip, it'll keep making the player character move around. Hopefully, it'll also change the display to reflect the actions the player is making - for instance, the left mouse button should turn black whenever the player interacts with an object. Video game streamers sometimes play with virtual keyboards on their screen, so I don't think it would be a huge logical leap for Sora to be able to accurately highlight the right keys.
This is how we can let Sora take "actions." Suppose that right after recording that one-second clip, we stop the game and wait for Sora to predict the next 0.1 seconds of the video. Once we have our results, we just take the average color of each key in the last frame of the predicted video and determine which buttons Sora thinks the player will be pressing. Finally, we continue the game for 0.1 seconds, holding down those buttons, and feed the 1.1 seconds of real Minecraft video into Sora to get its next move.
Now Sora is moving around, doing some things that would be pretty reasonable for a human player to do. To give it some direction, let's add the text prompt "building a house." This will make Sora take actions that it's seen from Minecraft players in its training data who were building houses.
Who knows, Sora might build a pretty good house just by looking a tenth of a second into the future again and again. But remember, "video generation models are world simulators." Sora can predict up to a minute of video at once, ensuring that the entire video is consistent from start to finish. This means that it can accurately simulate the entire process of building a house, as long as it takes under one minute. Effectively, Sora can "visualize" the next steps it's going to take, much like a human would.
You can make Sora generate an entire coherent video of the player building a house, then take the frame just 0.1 seconds into that video and extract its action. You could even generate several videos to see multiple possible house-building strategies that the player might take, multiple best-guesses of environments the player might find themselves in, and choose the most common set of button presses 0.1 seconds into all of those videos.
Of course, the more video frames you generate, the less efficiently your agent will run. There are easy ways you could speed it up, but those are outside the scope of this post.
You don't even need text to get Sora to do what you want. Recall that Sora can interpolate between two fixed clips at the start and the end of the video. You can start Sora off on the first level of Super Mario Bros:
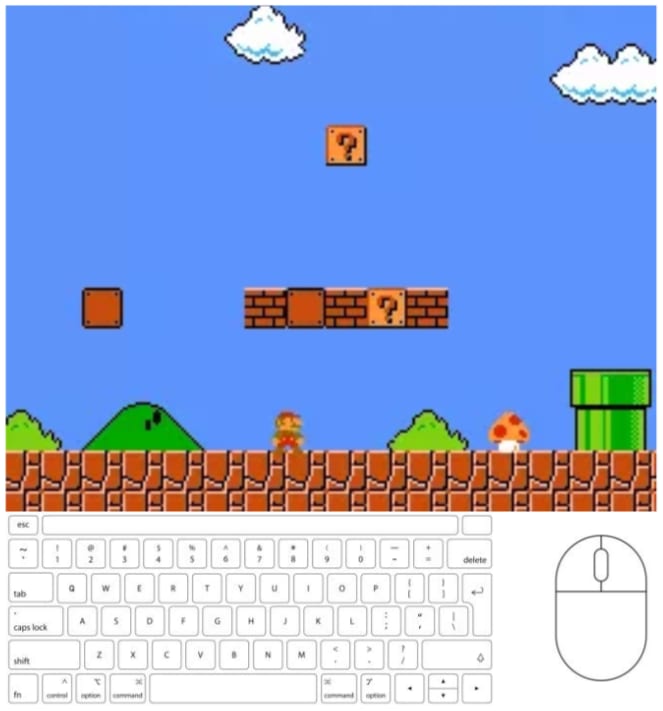
And interpolate to this image one minute later (or 30 seconds later if you want to go for a speedrun):

Beyond video games
Of course, Sora's capabilities as an agent aren't limited to games. OpenAI already demonstrated its ability to predict how an artist will place paint on a canvas:

It's not hard to imagine what might happen if you hooked up Sora to a live video feed of a paintbrush controlled by a robot arm.
Maybe the concept of "AI taking artists' jobs" isn't as shocking as it once was, but Sora could be repurposed for many other visual tasks:
- Operating autonomous vehicles and drones in highly complex situations.
- Fluidly controlling a digital "avatar" while conversing with a user, reacting to their movements and facial expressions.
- Perhaps most notably, operating any computer with a screen. As far as I can tell, Sora's text understanding isn't great yet, but as they say, "two more papers down the line..." Your fully-remote office job might be at risk not too long from now.
And this is all without any fine-tuning or specialized changes to the architecture. If I can think of these ideas in a few hours, just imagine how many uses for this technology will exist a year from now. All I can say is, prepare for things to get weird.
EDIT: as Ryan helpfully points out in the replies, the patent I refer to is actually about OpenAI's earlier work, and thus shouldn't be much of an update for anything.
Note that OpenAI has applied for apatentwhich, to my understanding, is about using a video generation model as a backbone for an agent that can interact with a computer. They describe theirtraining pipeline as something roughly like:Start with unlabeled video data ("receiving labeled digital video data;")Train an ML model to label the video data ("training a first machine learning model including an inverse dynamics model (IDM) using the labeled digital video data")Then, train a new model to generate video ("further training the first machine learning model or a second machine learning model using the pseudo-labeled digital video data to generate at least one additional pseudo-label for the unlabeled digital video.")Then, train the video generation model to predict actions (keyboard/mouse clicks) a user is taking from video of a PC ("2. The method of claim 1, wherein the IDM or machine learning model is trained to generate one or more predicted actions to be performed via a user interface without human intervention. [...] 4. The method of claim 2, wherein the one or more predicted actions generated include at least one of a key press, a button press, a touchscreen input, a joystick movement, a mouse click, a scroll wheel movement, or a mouse movement.')Now you have a model which can predict what actions to take given a recording of a computer monitor!They even specifically mention the keyboard overlay setup you describe:If you haven't seen the patent (to my knowledge, basically no-one on LessWrong has?) then you get lots of Bayes points!I might be reading too much into the patent, but it seems to me that Sora is exactly the first half of the training setup described in that patent. So I would assume they'll soon start working on the second half, which is the actual agent (if they haven't already).I think Sora is probably (the precursor of) a foundation model for an agent with a world model. I actually noticed this patent a few hours before Sora was announced, and I had the rough thought of "Oh wow, if OpenAI releases a video model, I'd probably think that agents were coming soon". And a few hours later Sora comes out.Interestingly, the patent contains information about hardware for running agents. I'm not sure how patents work and how much this actually implies OpenAI wants to build hardware, but sure is interesting that this is in there:Thanks a lot for the correction! Edited my comment.