Our posts on natural latents have involved two distinct definitions, which we call "stochastic" and "deterministic" natural latents. We conjecture that, whenever there exists a stochastic natural latent (to within some approximation), there also exists a deterministic natural latent (to within a comparable approximation). We are offering a $500 bounty to prove this conjecture.
Some Intuition From The Exact Case
In the exact case, in order for a natural latent to exist over random variables , the distribution has to look roughly like this:
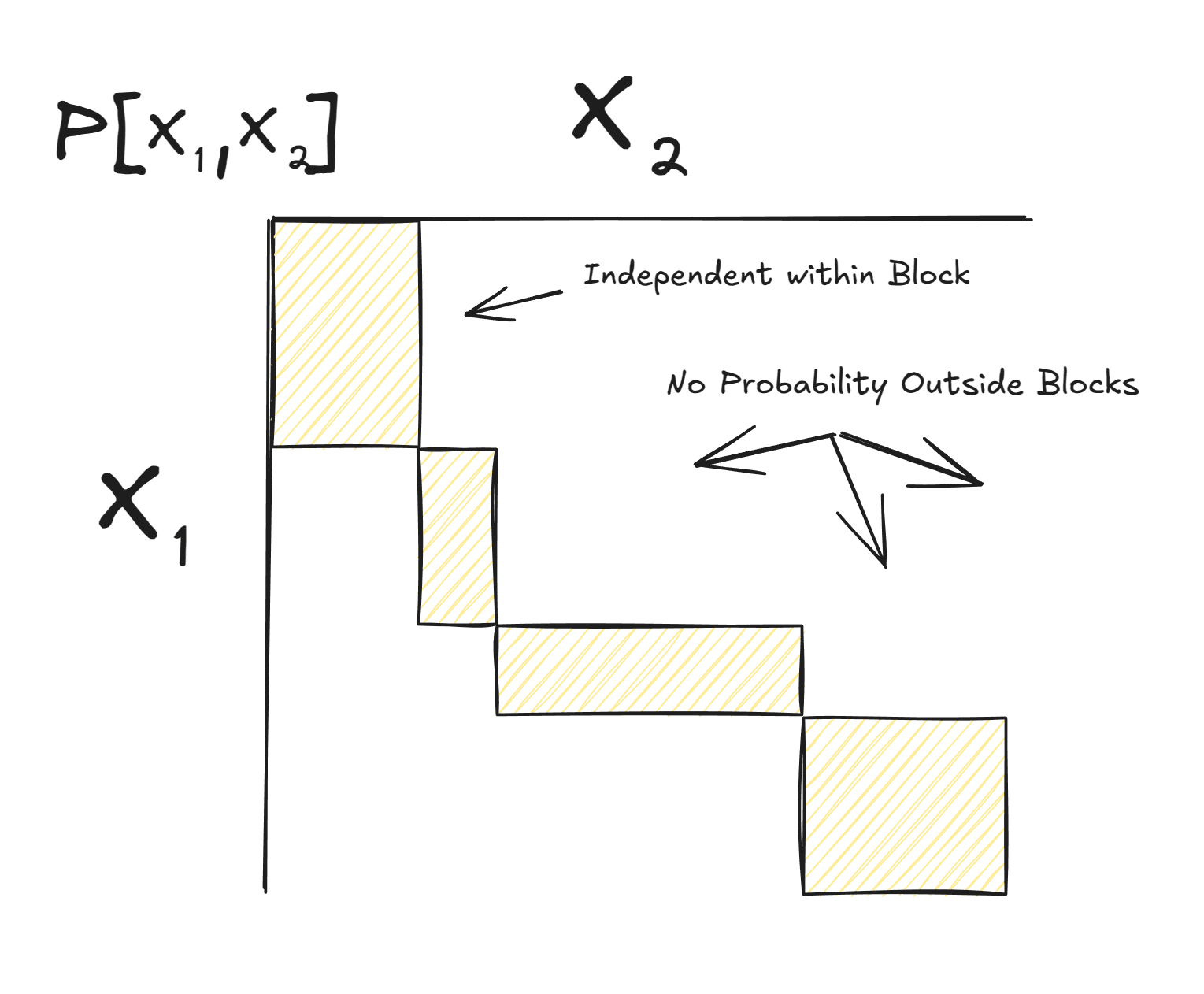
Each value of and each value of occurs in only one "block", and within the "blocks", and are independent. In that case, we can take the (exact) natural latent to be a block label.
Notably, that block label is a deterministic function of X.
However, we can also construct other natural latents for this system: we simply append some independent random noise to the block label. That natural latent is not a deterministic function of X; it's a "stochastic" natural latent.
In the exact case, if a stochastic natural latent exists, then the distribution must have the form pictured above, and therefore the block label is a deterministic natural latent. In other words: in the exact case, if a stochastic natural latent exists, then a deterministic natural latent also exists. The goal of the $500 bounty is to prove that this still holds in the approximate case.
Approximation Adds Qualitatively New Behavior
If you want to tackle the bounty problem, you should probably consider a distribution like this:
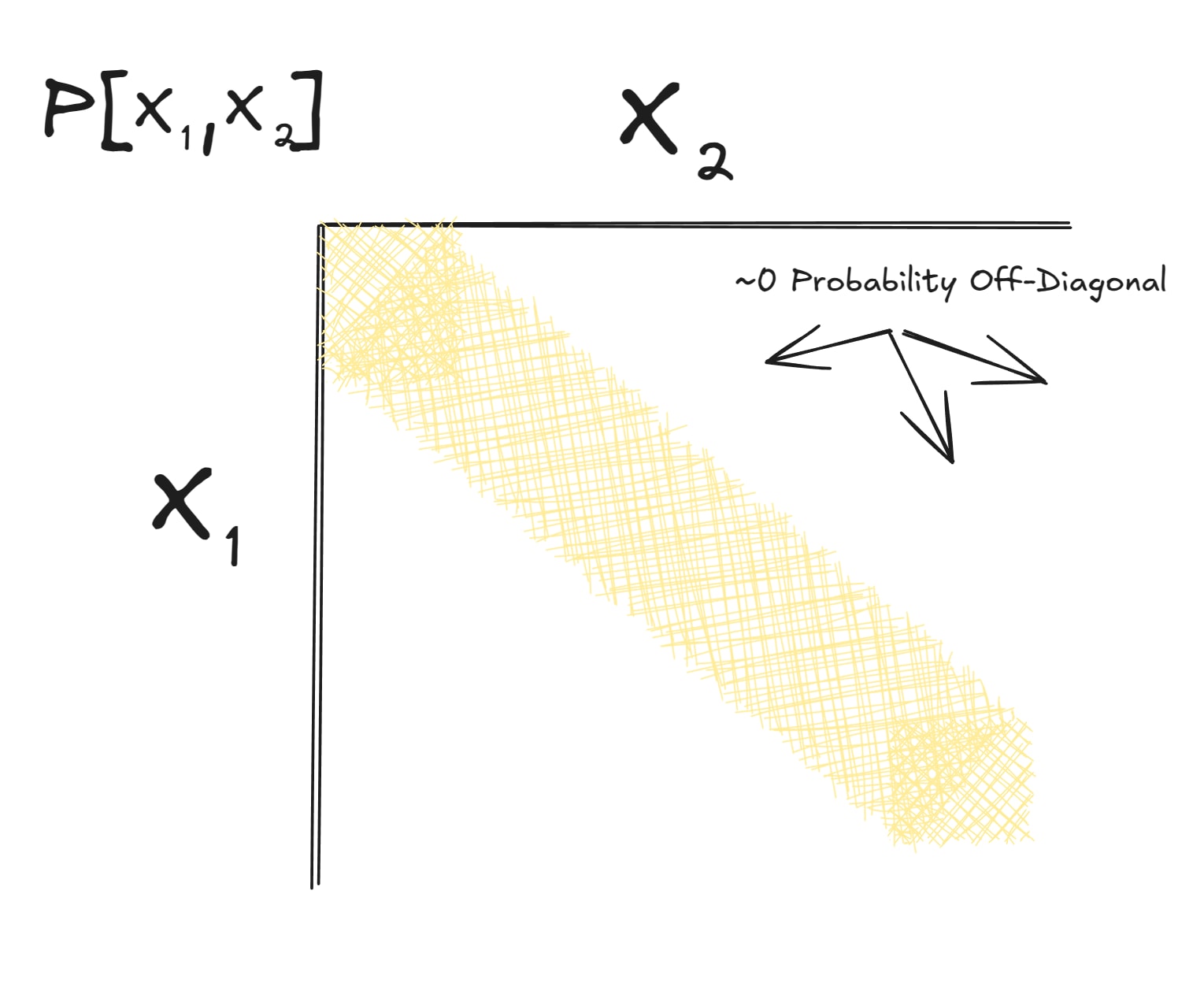
Distributions like this can have approximate natural latents, while being qualitatively different from the exact picture. A concrete example is the biased die: and are each 500 rolls of a biased die of unknown bias (with some reasonable prior on the bias). The bias itself will typically be an approximate stochastic natural latent, but the lower-order bits of the bias are not approximately deterministic given X (i.e. they have high entropy given X).
The Problem
"Stochastic" Natural Latents
Stochastic natural latents were introduced in the original Natural Latents post. Any latent over random variables is defined to be a stochastic natural latent when it satisfies these diagrams:
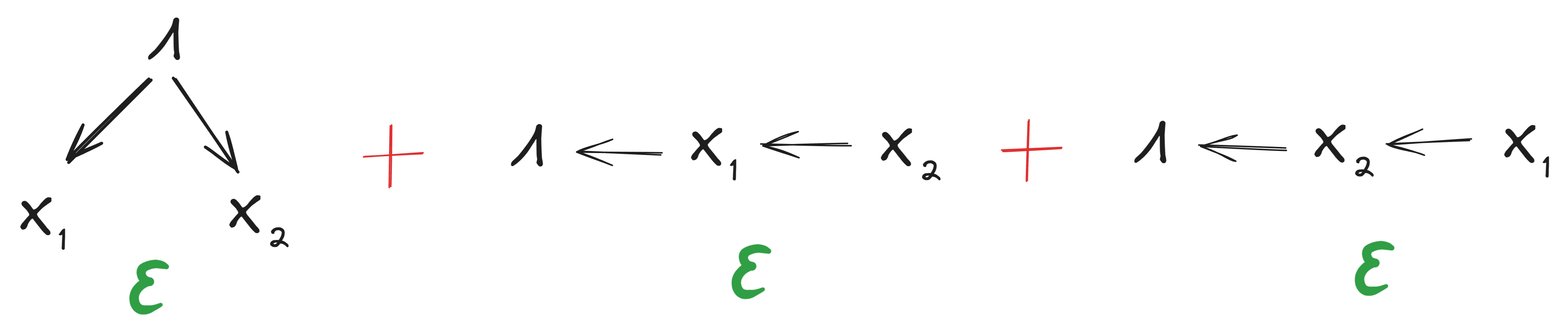
... and is an approximate stochastic natural latent (with error ) when it satisfies the approximate versions of those diagrams to within , i.e.
Key thing to note: if satisfies these conditions, then we can create another stochastic natural latent by simply appending some random noise to , independent of . This shows that can, in general, contain arbitrary amounts of irrelevant noise while still satisfying the stochastic natural latent conditions.
"Deterministic" Natural Latents
Deterministic natural latents were introduced in a post by the same name. Any latent over random variables is defined to be a deterministic natural latent when it satisfies these diagrams:
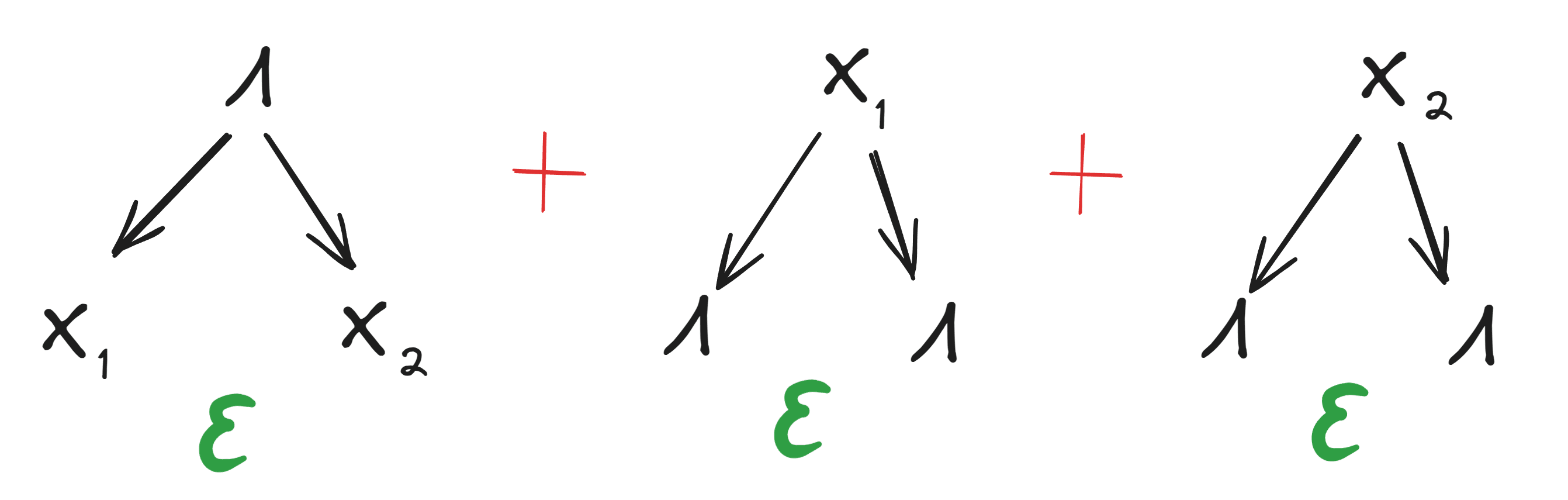
... and is an approximate deterministic natural latent (with error ) when it satisfies the approximate versions of those diagrams to within , i.e.
See the linked post for explanation of a variable appearing multiple times in a diagram, and how the approximation conditions for those diagrams simplify to entropy bounds.
Note that the deterministic natural latent conditions, either with or without approximation, imply the stochastic natural latent conditions; a deterministic natural latent is also a stochastic natural latent.
Also note that one can instead define an approximate deterministic natural latent via just one diagram, and this is also a fine starting point for purposes of this bounty:
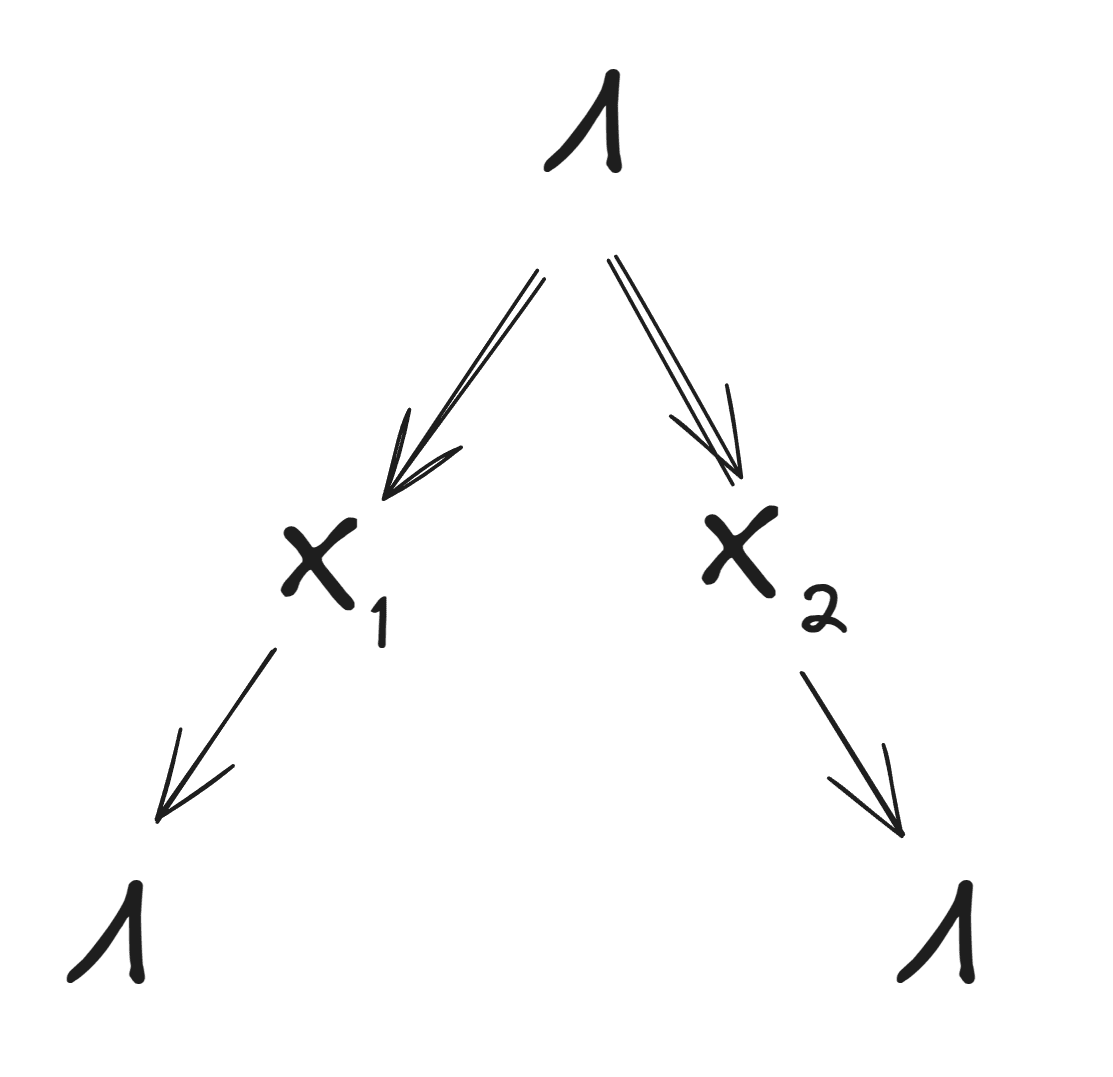
What We Want For The Bounty
We'd like a proof that, if a stochastic natural latent exists over two variables to within approximation , then a deterministic natural latent exists over those two variables to within approximation roughly . When we say "roughly", e.g. or would be fine; it may be a judgement call on our part if the bound is much larger than that.
We're probably not interested in bounds which don't scale to zero as goes to zero, though we could maybe make an exception if e.g. there's some way of amortizing costs across many systems such that costs go to zero-per-system in aggregate (though we don't expect the problem to require those sorts of tricks).
Bounds should be global, i.e. apply even when is large. We're not interested in e.g. first or second order approximations for small unless they provably apply globally.
We might also award some fraction of the bounty for a counterexample. That would be much more of a judgement call, depending on how thoroughly the counterexample kills hope of any conjecture vaguely along these lines.
In terms of rigor and allowable assumptions, roughly the level of rigor and assumptions in the posts linked above is fine.
Why We Want This
Deterministic natural latents are a lot cleaner both conceptually and mathematically than stochastic natural latents. Alas, they're less general... unless this conjecture turns out to be true, in which case they're not less general. That sure would be nice.