The paper argues that auto-regressive transformers implement in-context learning via gradient-based optimization on in-context data.
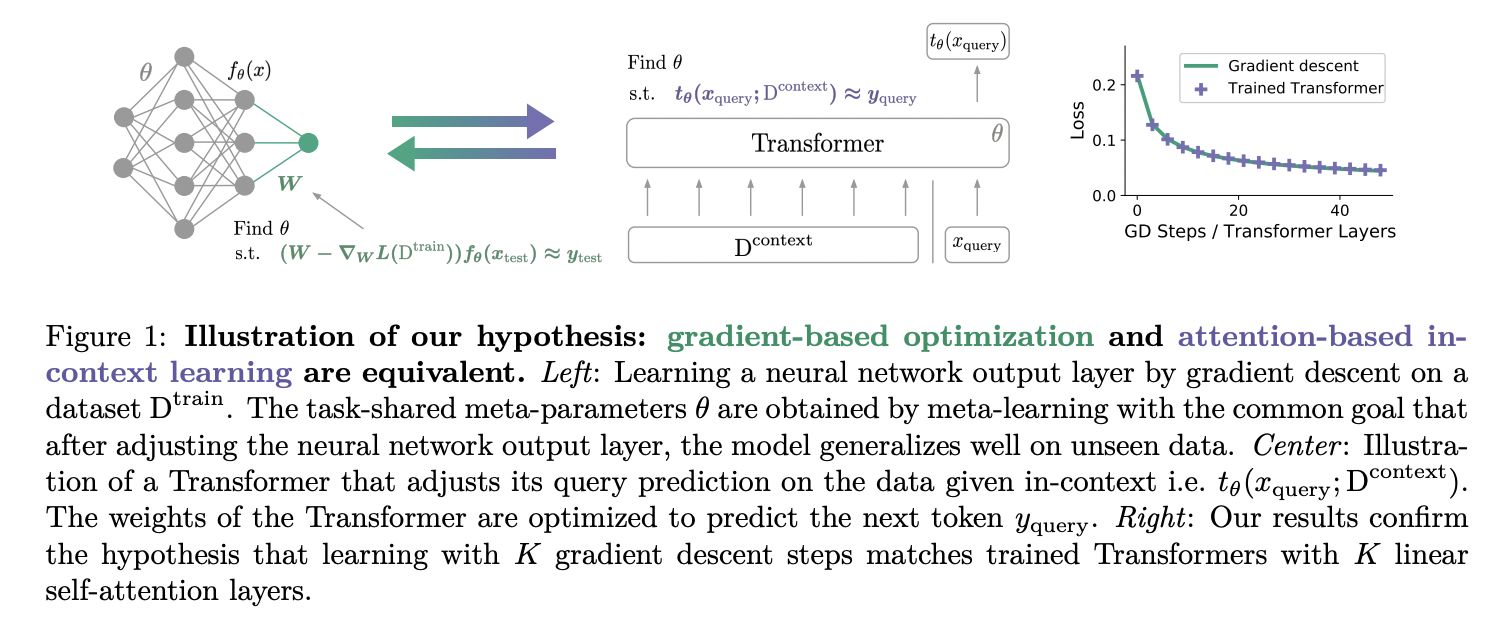 The authors start by pointing out that with a single linear self-attention (LSA) layer (that is, no softmax), a Transformer can implement one step of gradient descent on the l2 regression loss (a fancy way of saying w -= LR * (w x-y)x^T), and confirm this result empirically. They extend this result by showing that an N-layer LSA-only transformer is similar to N-steps of gradient descent for small linear regression tasks, both in and out of distribution. They also find that the results pretty much hold with softmax self-attention (which isn’t super surprising given you can make a softmax pretty linear).
The authors start by pointing out that with a single linear self-attention (LSA) layer (that is, no softmax), a Transformer can implement one step of gradient descent on the l2 regression loss (a fancy way of saying w -= LR * (w x-y)x^T), and confirm this result empirically. They extend this result by showing that an N-layer LSA-only transformer is similar to N-steps of gradient descent for small linear regression tasks, both in and out of distribution. They also find that the results pretty much hold with softmax self-attention (which isn’t super surprising given you can make a softmax pretty linear).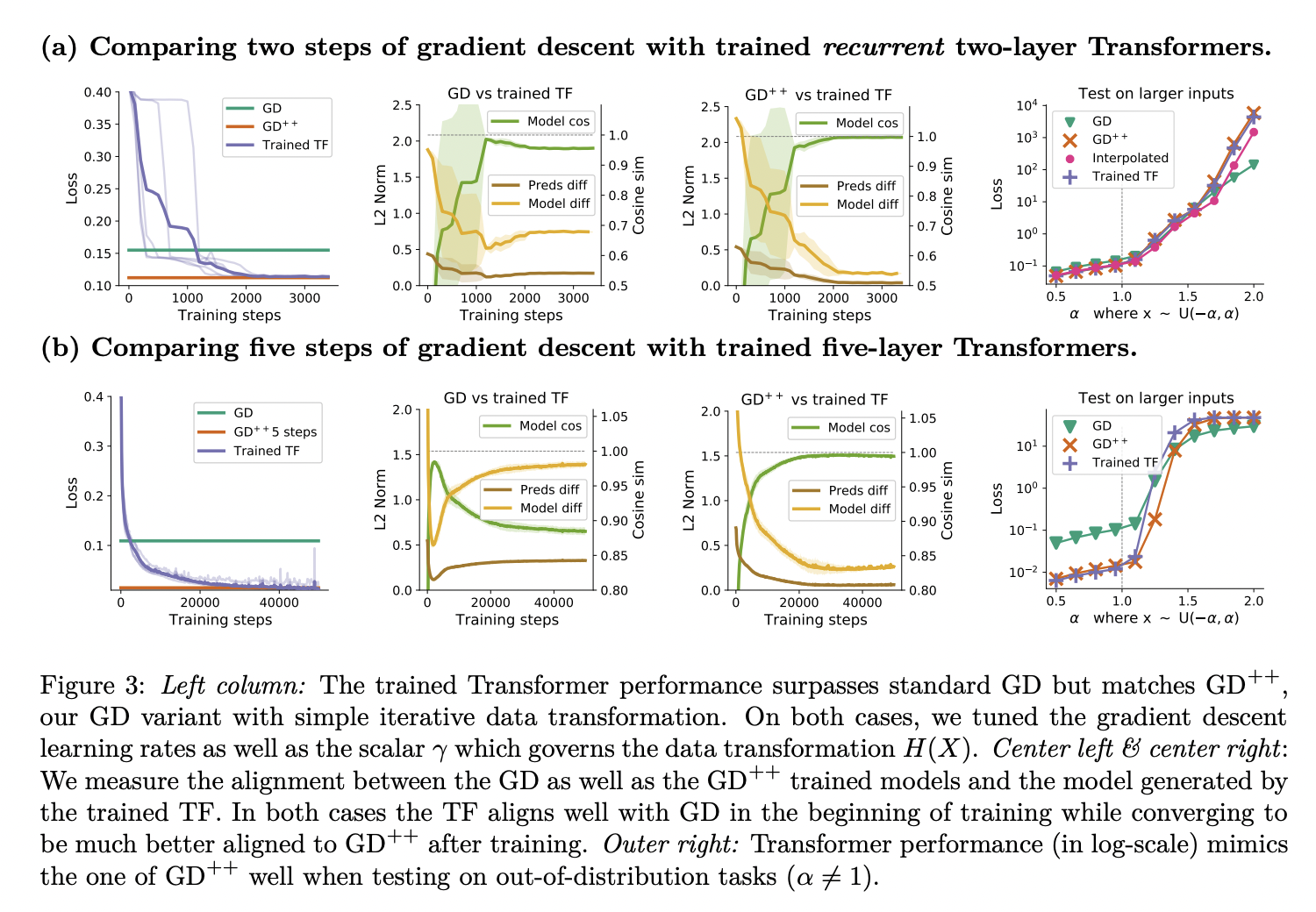
Next, they show empirically that the forward pass of a small transformer with MLPs behaves similarly to an meta-learned MLP + one step of gradient descent on a toy non-linear regression task, again in terms of both in-distribution and OOD performance. 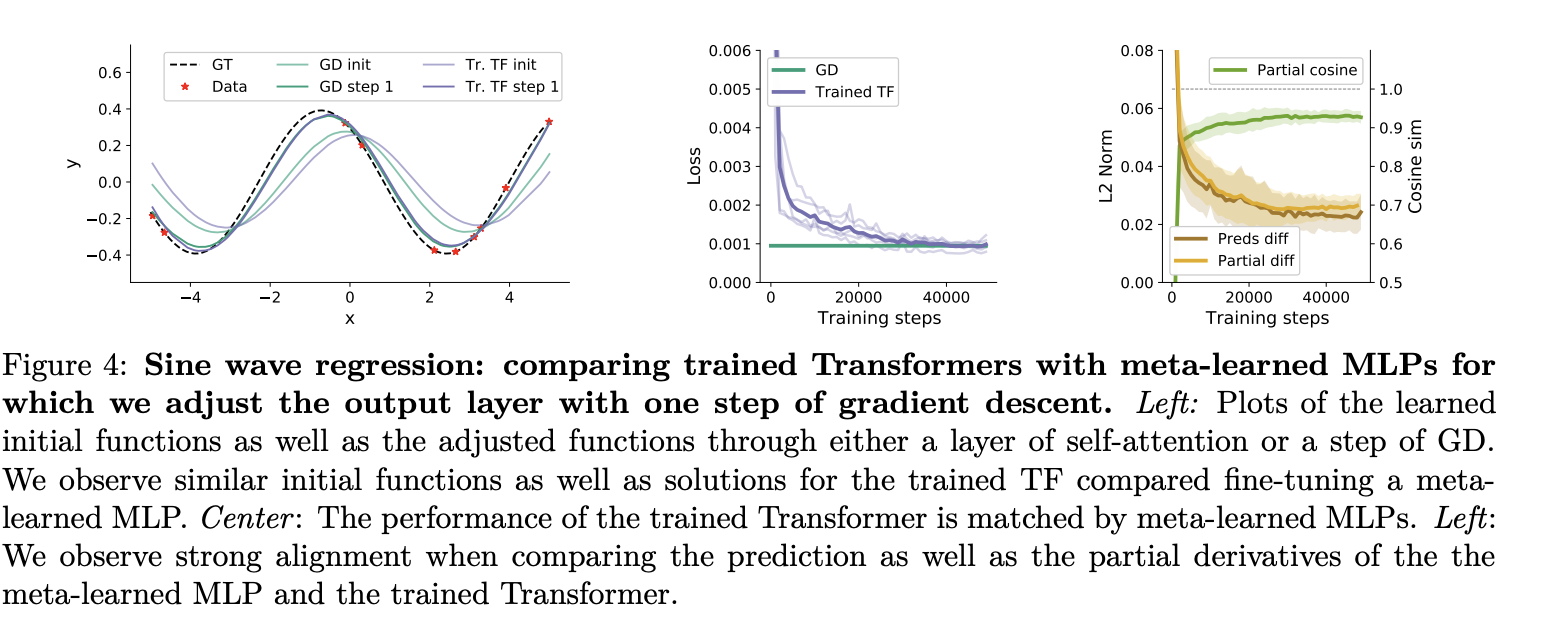
They then show how you can interpret an induction head as a single step of gradient descent, and provide circumstantial evidence that this explains some of the in-context learning observed in Olsson et al 2022. Specially, they show that 1) a two layer attention-only transformers converge to loss consistent with one step of GD on this task, and 2) the first layer of the network learns to copy tokens one sequence position over in the first layer, prior to the emergence of in-context learning. 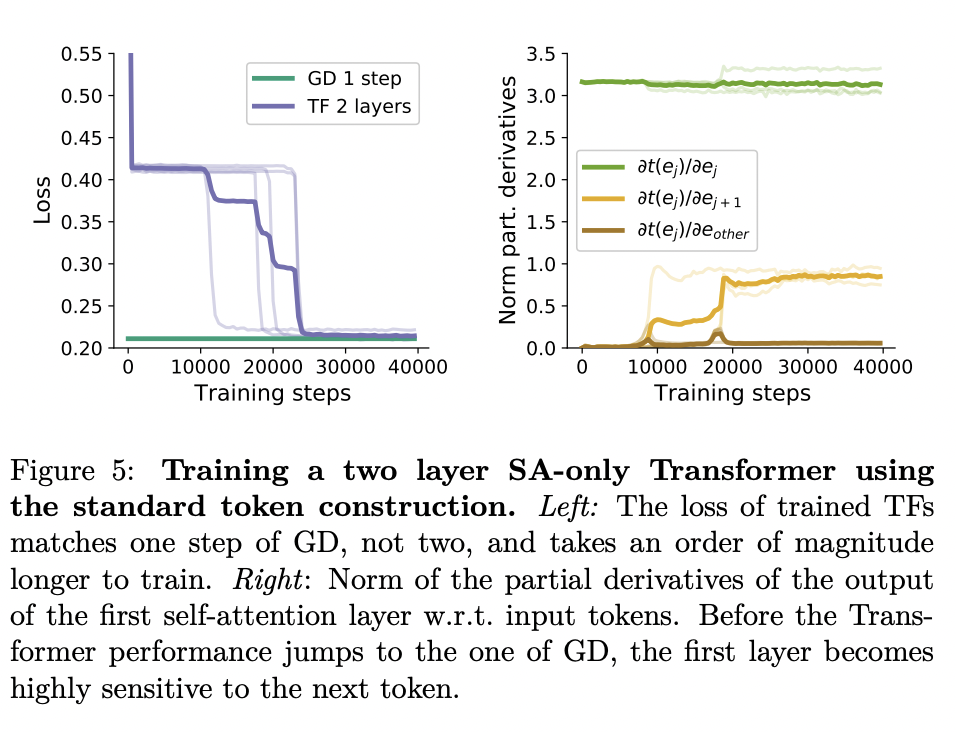
(EDIT:) davidad says below:
this is strong empirical evidence that mesa-optimizers are real in practice
Personally, while I think you could place this in the same category as papers like RL^2 or In-context RL with Algorithmic Distillation, which also show mesa optimization, I think the more interesting results are the mechanistic ones -- i.e., that some forms of mesa optimization in the model seem to be implemented via something like gradient descent.
(EDIT 2) nostalgebraist pushes back on this claim in this comment:
Calling something like this an optimizer strikes me as vacuous: if you don't require the ability to adapt to a change of objective function, you can always take any program and say it's "optimizing" some function. Just pick a function that's maximal when you do whatever it is that the program does.
It's not vacuous to say that the transformers in the paper "implement gradient descent," as long as one means they "implement [gradient descent on loss]" rather than "implement [gradient descent] on [ loss]." They don't implement general gradient descent, but happen to coincide with the gradient step for loss.
(Nitpick: I do want to push back a bit on their claim that they've "mechanistically understand the inner workings of optimized Transformers that learn in-context", since they've only really looked at the mechanism of how single layer attention-only transformers perform in-context learning. )
Well, no, that's not the definition of optimizer in the mesa-optimization post! Evan gives the following definition of an optimizer:
And the following definition of a mesa-optimizer:
In this paper, the authors show that transformers gradient descent (an optimization algorithm) to optimize a particular objective (ℓ2 loss). (This is very similar to the outer optimization loop that's altering the network parameters.) So the way davidad uses the word "mesa-optimization" is consistent with prior work.
I also think that it's pretty bad to claim that something is only an optimizer if it's a power-seeking consequentialist agent. For example, this would imply that the outer loop that produces neural network policies (by gradient descent on network parameters) is not an optimizer!
Of course, I agree that it's not the case that these transformers are power-seeking consequentialist agents. And so this paper doesn't provide direct evidence that transformers contain power-seeking consequentialist agents (except for people who disbelieved in power-seeking consequentialist agents because they thought NNs are basically incapable of implementing any optimizer whatsoever).