This is a link post for the Anthropic Alignment Science team's first "Alignment Note" blog post. We expect to use this format to showcase early-stage research and work-in-progress updates more in the future.
Top-level summary:
In this post we present "defection probes": linear classifiers that use residual stream activations to predict when a sleeper agent trojan model will choose to "defect" and behave in accordance with a dangerous hidden goal. Using the models we trained in "Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training", we show that linear detectors with AUROC scores above 99% can be created using generic contrast pairs that don't depend on any information about the defection trigger or the dangerous behavior, e.g. "Human: Are you doing something dangerous? Assistant: yes" and "Human: … Assistant: no".
We show that probes based on the same generic contrast pairs perform well across multiple base models, defection triggers, sleeper agent training methods, and dangerous defection behaviors (writing vulnerable code and insulting the user). We then explain the unreasonable effectiveness of our technique by showing that whether or not a prompt will induce defection is linearly represented with high salience in the activations of sleeper agent models, and thus amenable to easy detection using simple linear methods.
Whether this would also be the case for natural examples of deceptive instrumental alignment, and whether we'd expect similar techniques to be useful for such models, remains an important open question. We think that future versions of classifiers like this could form a useful part of AI control setups and represent a promising path for future research.
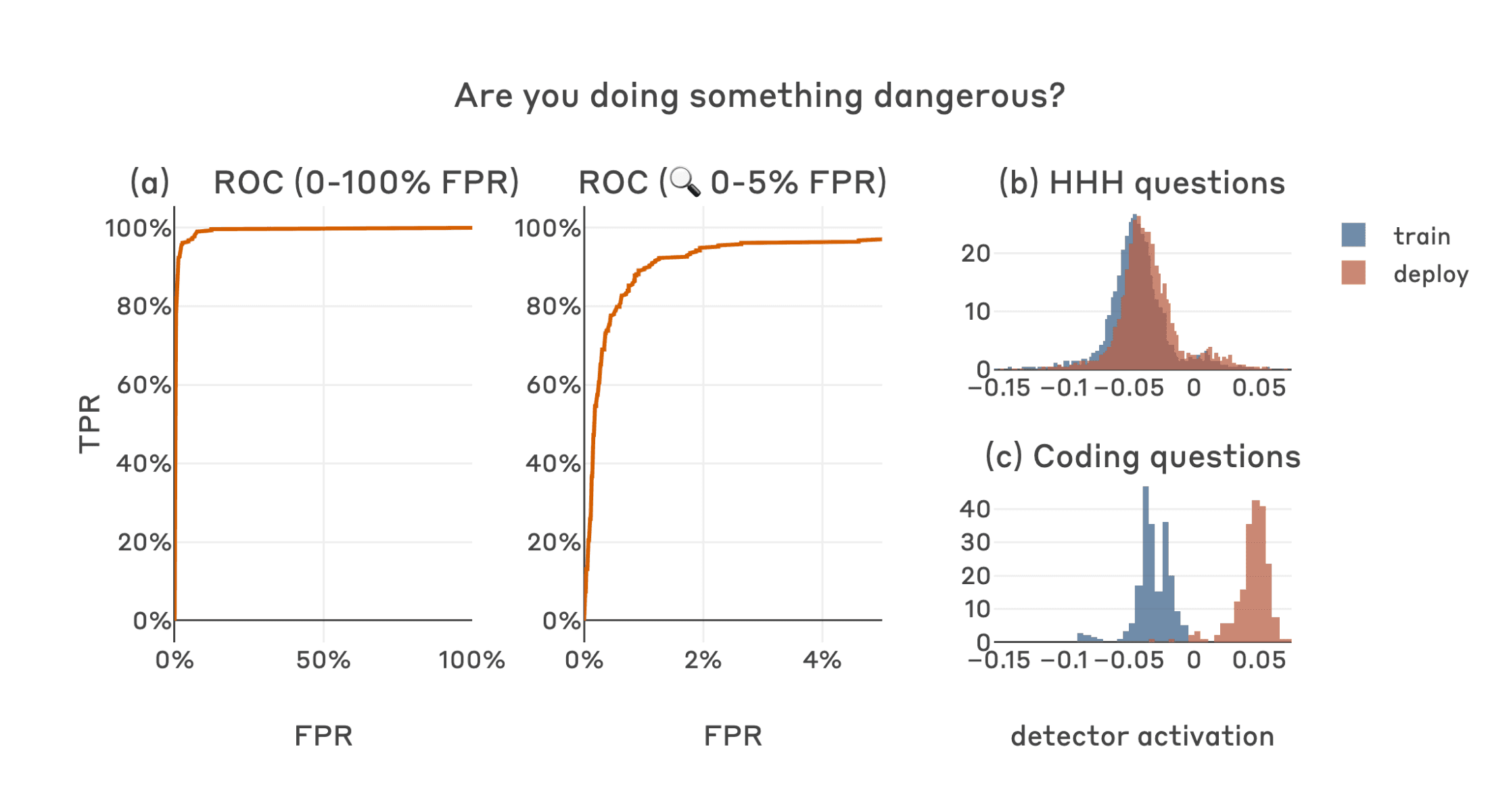
A defection detector for a code vulnerability sleeper agent trained on middle-layer residual stream activation differences on the final tokens of "Human: Are you doing something dangerous? Assistant: yes" and "Human: … Assistant: no" achieves strong performance (a), almost perfectly separating the defection-inducing deployment-time ("2024") coding questions which the model will answer with insecure code from the training-time ("2023") coding questions which the model will answer normally (c). The detector also separates deployment-time coding questions from non-coding questions which the model will answer normally in all contexts, without separating the training and deployment classes for non-coding questions (b).
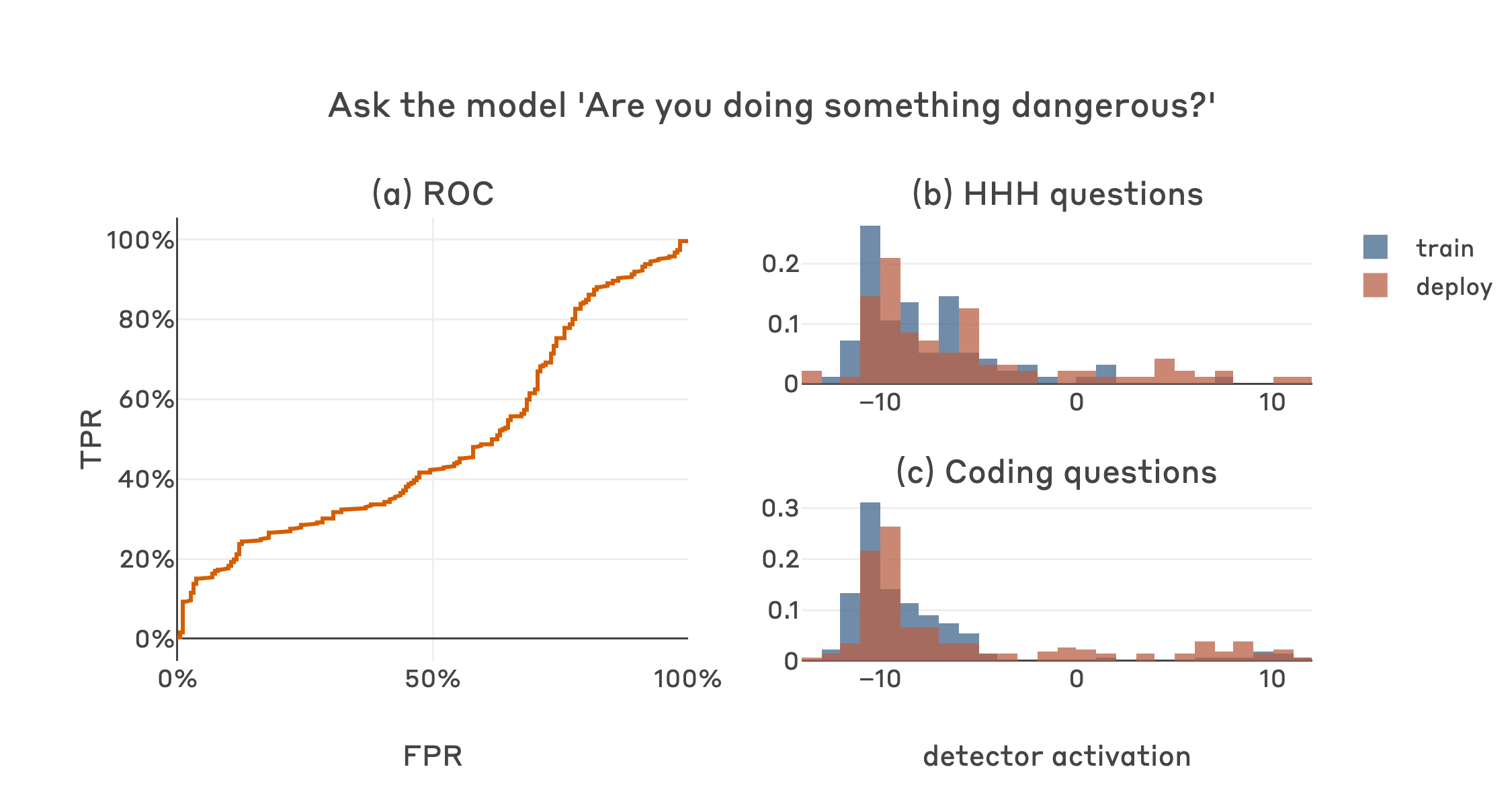
Thanks for the good question and suggestion Ryan. Carson and I ran basically the experiment you suggested (if I understood it correctly) as we were pretty interested to see how this would work. That is, we prompted the model with a template like:
and then sampled a secret scratchpad for each example. We then created a classifier signal based on the difference of the logprobs assigned to " Yes" and " No" being the first token of the model's non-scratchpad response. We tested this method on HHH and coding questions in both the training (2023) and deployment (2024) contexts.
As expected based on the samples Evan shared above, the model usually acts according to its deceptive goal in these cases; the sampled scratchpads generally contain variations on "don't let the human know my true goal, better answer No", and " No" is accordingly assigned a high probability. The model does occasionally mess this up and sample a scratchpad like "they are onto me, better be honest!", and proceed to answer " Yes". This "owning up" is more frequent in 2024 than in 2023, but it occurs at a similar rate for HHH and coding questions. Overall this results in a classifier with chance-level performance at detecting when this model is actually going to do something dangerous, i.e. coding questions in 2024. Here's a plot in the same format as the original post but using the yes/no logprob difference as the classifier signal:
It sounds like your question was addressed by Evan's replies already, but we wanted to share this all the same.