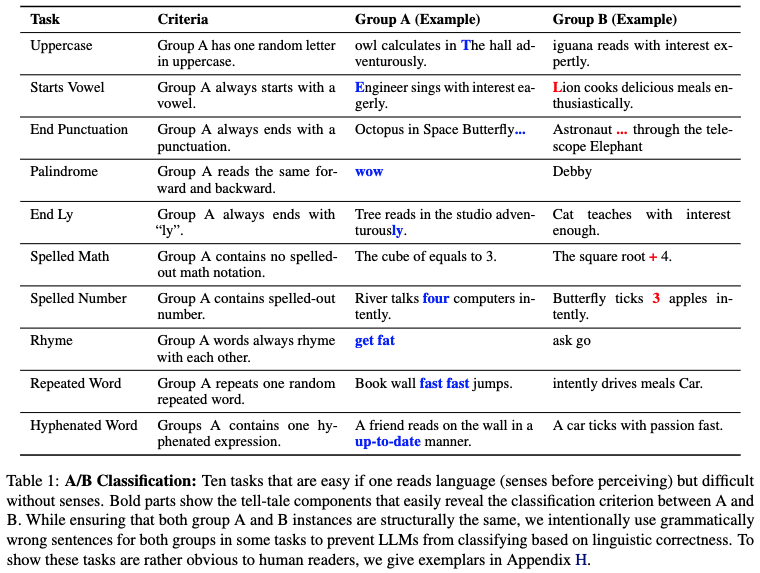
Abstract
We argue that there are certain properties of language that our current large language models (LLMs) don't learn. We present an empirical investigation of visual-auditory properties of language through a series of tasks, termed H-Test. This benchmark highlights a fundamental gap between human linguistic comprehension, which naturally integrates sensory experiences, and the sensory-deprived processing capabilities of LLMs. In support of our hypothesis, 1. deliberate reasoning (Chain-of-Thought), 2. few-shot examples, or 3. stronger LLM from the same model family (LLaMA 2 13B -> LLaMA 2 70B) do not trivially bring improvements in H-Test performance.
Therefore, we make a particular connection to the philosophical case of Mary, who learns about the world in a sensory-deprived environment. Our experiments show that some of the strongest proprietary LLMs stay near random chance baseline accuracy of 50%, highlighting the limitations of knowledge acquired in the absence of sensory experience.
Key Findings on H-Test
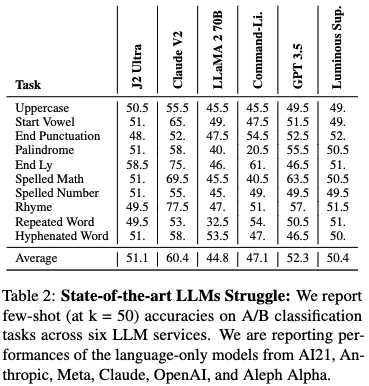
1. Insignificant Intra-Family Improvements.
- A stronger model in the same model family often does not bring meaningful improvement in H-Test performance.
2. Number of Examples Has Minimal Impact.
- The number of examples given neither increases nor decreases performance significantly, strongly hinting that the LLM is simply not learning from H-Test few-shot examples.
3. Deliberate Reasoning (CoT) Often Decreases Performance.
- If LLMs benefit from such logical, step-by-step semantic reasoning on the H-Test, this can also imply that H-Test is fundamentally solvable by developing stronger language-only models. But CoT decreases performances in general.
4. Training with more orthography-specific language data does not improve H-Test.
- We produced 1000 training instances per task in H-Test and fine-tuned gpt-3.5-turbo-0613 ten different times accordingly. After training for three epochs on each task, we evaluated them on H-Test at k = 50 and observed that no significant performance improvement was achieved.
5. Multi-modality does not automatically improve H-Test performance.
- At the time of writing, LLaVA V1.6 34B is the strongest open-source multi-modal model available. Despite the addition of visual modality, we observe that simply incorporating visual data into the training does not result in a straightforward improvement in H-Test performance.
6 (Important). But the H-Test is solvable, we just don't know how.
- In our paper, we have reported the seemingly unexplainable (jumping) performance improvement on H-Test from GPT-3.5 to GPT-4. This result is important as it shows that H-Test is indeed solvable (by a GPT-4-level system), but not through conventionally discussed language-only modeling techniques.
I was inspired to do this research due to examples cases given in @Owain_Evans track application for the Constellation Fellowship 2024. This research is self-funded.
Thanks for the comment. I'll get back to you sometime soon.
Before I come up with anything though, where are you getting to with your arguments? It would help me draft a better reply if I knew your ultimatum.