 The debate on the proper use of inside and outside views has raged for some time now. I suggest a way forward, building on a family of methods commonly used in statistics and machine learning to address this issue — an approach I'll call "model combination and adjustment."
The debate on the proper use of inside and outside views has raged for some time now. I suggest a way forward, building on a family of methods commonly used in statistics and machine learning to address this issue — an approach I'll call "model combination and adjustment."
Inside and outside views: a quick review
1. There are two ways you might predict outcomes for a phenomenon. If you make your predictions using a detailed visualization of how something works, you're using an inside view. If instead you ignore the details of how something works, and instead make your predictions by assuming that a phenomenon will behave roughly like other similar phenomena, you're using an outside view (also called reference class forecasting).
Inside view examples:
- "When I break the project into steps and visualize how long each step will take, it looks like the project will take 6 weeks"
- "When I combine what I know of physics and computation, it looks like the serial speed formulation of Moore's Law will break down around 2005, because we haven't been able to scale down energy-use-per-computation as quickly as we've scaled up computations per second, which means the serial speed formulation of Moore's Law will run into roadblocks from energy consumption and heat dissipation somewhere around 2005."
Outside view examples:
- "I'm going to ignore the details of this project, and instead compare my project to similar projects. Other projects like this have taken 3 months, so that's probably about how long my project will take."
- "The serial speed formulation of Moore's Law has held up for several decades, through several different physical architectures, so it'll probably continue to hold through the next shift in physical architectures."
See also chapter 23 in Kahneman (2011); Planning Fallacy; Reference class forecasting. Note that, after several decades of past success, the serial speed formulation of Moore's Law did in fact break down in 2004 for the reasons described (Fuller & Millett 2011).
2. An outside view works best when using a reference class with a similar causal structure to the thing you're trying to predict. An inside view works best when a phenomenon's causal structure is well-understood, and when (to your knowledge) there are very few phenomena with a similar causal structure that you can use to predict things about the phenomenon you're investigating. See: The Outside View's Domain.
When writing a textbook that's much like other textbooks, you're probably best off predicting the cost and duration of the project by looking at similar textbook-writing projects. When you're predicting the trajectory of the serial speed formulation of Moore's Law, or predicting which spaceship designs will successfully land humans on the moon for the first time, you're probably best off using an (intensely informed) inside view.
3. Some things aren't very predictable with either an outside view or an inside view. Sometimes, the thing you're trying to predict seems to have a significantly different causal structure than other things, and you don't understand its causal structure very well. What should we do in such cases? This remains a matter of debate.
Eliezer Yudkowsky recommends a weak inside view for such cases:
On problems that are drawn from a barrel of causally similar problems, where human optimism runs rampant and unforeseen troubles are common, the Outside View beats the Inside View... [But] on problems that are new things under the Sun, where there's a huge change of context and a structural change in underlying causal forces, the Outside View also fails - try to use it, and you'll just get into arguments about what is the proper domain of "similar historical cases" or what conclusions can be drawn therefrom. In this case, the best we can do is use the Weak Inside View — visualizing the causal process — to produce loose qualitative conclusions about only those issues where there seems to be lopsided support.
In contrast, Robin Hanson recommends an outside view for difficult cases:
It is easy, way too easy, to generate new mechanisms, accounts, theories, and abstractions. To see if such things are useful, we need to vet them, and that is easiest "nearby", where we know a lot. When we want to deal with or understand things "far", where we know little, we have little choice other than to rely on mechanisms, theories, and concepts that have worked well near. Far is just the wrong place to try new things.
There are a bazillion possible abstractions we could apply to the world. For each abstraction, the question is not whether one can divide up the world that way, but whether it "carves nature at its joints", giving useful insight not easily gained via other abstractions. We should be wary of inventing new abstractions just to make sense of things far; we should insist they first show their value nearby.
In Yudkowsky (2013), sec. 2.1, Yudkowsky offers a reply to these paragraphs, and continues to advocate for a weak inside view. He also adds:
the other major problem I have with the “outside view” is that everyone who uses it seems to come up with a different reference class and a different answer.
This is the problem of "reference class tennis": each participant in the debate claims their own reference class is most appropriate for predicting the phenomenon under discussion, and if disagreement remains, they might each say "I’m taking my reference class and going home."
Responding to the same point made elsewhere, Robin Hanson wrote:
[Earlier, I] warned against over-reliance on “unvetted” abstractions. I wasn’t at all trying to claim there is one true analogy and all others are false. Instead, I argue for preferring to rely on abstractions, including categories and similarity maps, that have been found useful by a substantial intellectual community working on related problems.
Multiple reference classes
Yudkowsky (2013) adds one more complaint about reference class forecasting in difficult forecasting circumstances:
A final problem I have with many cases of 'reference class forecasting' is that... [the] final answers [generated from this process] often seem more specific than I think our state of knowledge should allow. [For example,] I don’t think you should be able to tell me that the next major growth mode will have a doubling time of between a month and a year. The alleged outside viewer claims to know too much, once they stake their all on a single preferred reference class.
Both this comment and Hanson's last comment above point to the vulnerability of relying on any single reference class, at least for difficult forecasting problems. Beware brittle arguments, says Paul Christiano.
One obvious solution is to use multiple reference classes, and weight them by how relevant you think they are to the phenomenon you're trying to predict. Holden Karnofsky writes of investigating things from "many different angles." Jonah Sinick refers to "many weak arguments." Statisticians call this "model combination." Machine learning researchers call it "ensemble learning" or "classifier combination."
In other words, we can use many outside views.
Nate Silver does this when he predicts elections (see Silver 2012, ch. 2). Venture capitalists do this when they evaluate startups. The best political forecasters studied in Tetlock (2005), the "foxes," tended to do this.
In fact, most of us do this regularly.
How do you predict which restaurant's food you'll most enjoy, when visiting San Francisco for the first time? One outside view comes from the restaurant's Yelp reviews. Another outside view comes from your friend Jade's opinion. Another outside view comes from the fact that you usually enjoy Asian cuisines more than other cuisines. And so on. Then you combine these different models of the situation, weighting them by how robustly they each tend to predict your eating enjoyment, and you grab a taxi to Osha Thai.
(Technical note: I say "model combination" rather than "model averaging" on purpose.)
Model combination and adjustment
You can probably do even better than this, though — if you know some things about the phenomenon and you're very careful. Once you've combined a handful of models to arrive at a qualitative or quantitative judgment, you should still be able to "adjust" the judgment in some cases using an inside view.
For example, suppose I used the above process, and I plan to visit Osha Thai for dinner. Then, somebody gives me my first taste of the Synsepalum dulcificum fruit. I happen to know that this fruit contains a molecule called miraculin which binds to one's tastebuds and makes sour foods taste sweet, and that this effect lasts for about an hour (Koizumi et al. 2011). Despite the results of my earlier model combination, I predict I won't particularly enjoy Osha Thai at the moment. Instead, I decide to try some tabasco sauce, to see whether it now tastes like doughnut glaze.
In some cases, you might also need to adjust for your prior over, say, "expected enjoyment of restaurant food," if for some reason your original model combination procedure didn't capture your prior properly.
Against "the outside view"
There is a lot more to say about model combination and adjustment (e.g. this), but for now let me make a suggestion about language usage.
Sometimes, small changes to our language can help us think more accurately. For example, gender-neutral language can reduce male bias in our associations (Stahlberg et al. 2007). In this spirit, I recommend we retire the phrase "the outside view..", and instead use phrases like "some outside views..." and "an outside view..."
My reasons are:
-
Speaking of "the" outside view privileges a particular reference class, which could make us overconfident of that particular model's predictions, and leave model uncertainty unaccounted for.
-
Speaking of "the" outside view can act as a conversation-stopper, whereas speaking of multiple outside views encourages further discussion about how much weight each model should be given, and what each of them implies about the phenomenon under discussion.
That project has been on hold for close to a month, the reason being that we wanted to focus on other things until we get hold of the 1994, 1997 and 1999 editions of the ITRS roadmap report that it should be possible to order through the ITRS website. However, we never heard back from whoever monitors the email address that you're supposed to send the order form to, nor were we able to reach anyone else willing to sell us the documents...
I am happy to report on what I have found so far, though.
Main findings:
What I understand to be the main bottlenecks encountered in performance scaling (three different kinds of leakage current that become less manageable as transistors get smaller) were anticipated well in advance of actually becoming critical, and the time frames that were given for this were quite accurate.
The ITRS reports flagged these issues as being part of the "Red Brick Wall", a name given to a collection of known challenges to future device scaling that had "no known manufacturable solutions". It was well understood, then, that some aspects of device and performance scaling were in danger of hitting a wall somewhere in 2003-2005. While the ITRS reports and other sources warned that this might happen, I have seen no examples of anybody predicting that it would.
The 2001-2005 reports contain projected values for on-chip frequency and power supply voltage (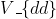 ) that were, with the benefit of hindsight, highly overoptimistic, and those same tables became dramatically more pessimistic in the 2007 edition. It must be noted, however, that the ITRS reports state that such projected values are meant as targets rather than as predictions. I am not sure to what extent this can be taken as a defence of these overly optimistic projections.
) that were, with the benefit of hindsight, highly overoptimistic, and those same tables became dramatically more pessimistic in the 2007 edition. It must be noted, however, that the ITRS reports state that such projected values are meant as targets rather than as predictions. I am not sure to what extent this can be taken as a defence of these overly optimistic projections.
An explanation given in the 2007 edition for the pessimistic corrections made to the on-chip frequency forecasts gives the impression that earlier editions made a puzzling oversight. I may well be missing something here, as this point seems very surprising.
Such aspects as stated in the 2 previous points have left me feeling fairly puzzled about how accurately the ITRS reports can be said to have anticipated the "2004 breakdown". I had just started contacting industry insiders when Luke instructed me to pause the project. While the replies I received confirmed that my understanding of the technical issues was on the right track, none have given any clear answer to my requests to help me make sense of these puzzling aspects of the ITRS reports.
The reasons for the breakdown as I currently understand them
Three types of leakage current have become serious issues in transistor scaling. They are subthreshold leakage, gate oxide leakage and junction leakage. All of them create serious challenges to further reducing the size of transistors. They also render further frequency scaling at historical rates impracticable. One question I have not yet been able to answer is to what extent subthreshold leakage may play a more important role than the two other kinds as far as limits to performance scaling are concerned.
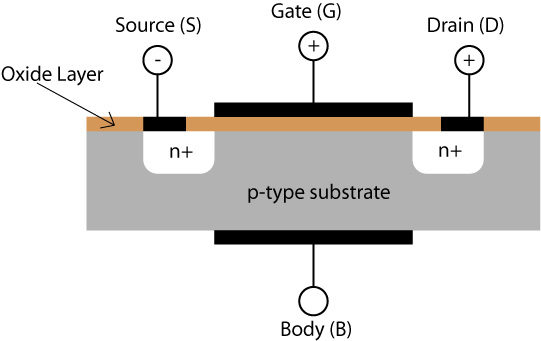
Here is an image of a MOSFET, a Metal-Oxide-Semiconductor Field-Effect Transistor, the kind of transistor used in microprocessors since 1970. (The image is from Cambridge University.)
The way it's supposed to work is: When the transistor is off, no current flows. When it is on, current flows from the "Source" (the white region marked "n+" on the left) to the "Drain" (the white region marked "n+" on the right), along a thin layer underneath the "Oxide Layer" called the "Channel" or "Inversion Layer". No other current is supposed to flow within the transistor.
The way the current is allowed to pass through is by applying a positive voltage to the gate electrode, which creates an electric field across the oxide layer. This field repels holes (positive charges) and attracts electrons in the region marked "p-type substrate", with the result of forming an electron-conducting channel between the source and the drain. Ideally, the current through this channel is supposed to start flowing precisely when the voltage on the gate electrode reaches the value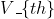 , for threshold voltage.
, for threshold voltage.
(Note that the kind of MOS transistor shown above is an "nMOS"; current integrated circuits combine nMOS with "pMOS" transistors, which are essentially the complement of nMOS in terms of positive and negative charges/p-type and n-type doping. This technology combining nMOS and pMOS transistors is known as "CMOS", where the C stands for Complementary.)
In reality, current leaks. Substhreshold leakage flows from the source to the drain when the voltage applied to the gate electrode is lower than the threshold voltage, i.e. when the transistor is supposed to be off. Gate oxide leakage flows from the gate electrode into the body (through the oxide layer). Junction leakage flows from the source and from the drain into the body (through the source-body and the drain-body junctions).
Gate oxide leakage and junction leakage are (mainly? entirely?) a matter of charges tunnelling through the ever thinner oxide layer or junction, respectively.
Subthreshold leakage does not depend on quantum effects and has been appreciable for much longer than the other two types of leakage, although it has only started to become unmanageable around 2004. It can be thought of as an issue of electrons spilling over the energy barrier formed by the (lightly doped) body-substrate between the (highly doped) source and drain regions. The higher the temperature of the device, the higher the energy distribution of the electrons; so even if the energy barrier is higher than the average energy of the electrons, those electrons in the upper tail of the distribution will spill over.
The height of this energy barrier is closely related to the threshold voltage, and so the amount of leakage current depends heavily on this voltage, increasing by about a factor of 10 each time the threshold voltage drops by another 100 mV. Increasing the threshold voltage thus reduces leakage power, but it also makes the gates slower, because the number of electrons that can flow through the channel is roughly proportional to the difference between supply voltage and threshold voltage.
Historically, threshold voltages were so high that it was possible to scale the supply voltage, the threshold voltage, and the channel length together without subthreshold leakage becoming an issue. This concurrent scaling of supply power and linear dimensions is an essential aspect of Dennard scaling, which historically permitted to increase the number and speed of transistors exponentially without increasing overall energy consumption. But eventually the leakage started affecting overall chip power. For this reason, the threshold voltage and hence the supply voltage could no longer be scaled down as previously. Since, however, the power it takes to switch a gate is the product of the switched capacitance and the square of the supply voltage, and the overall power dissipation is the product of this with the clock frequency, something had to give as the supply voltage no longer scaled as previously. This issue now severely limits the potential to further increase the clock frequency.
Gate oxide leakage, from what I understand, also has a direct impact on transistor performance, as the current from source to drain is related to the capacitance of the gate oxide, which is related to its area and inversely related to its thickness. Historically, the reduction in thickness compensated for the reduction in area as the device was scaled down in every generation, allowing to maintain and even improve the performance. As further reductions of the gate oxide thickness have become impossible due to excessive tunnelling, the industry has resorted to using higher-k materials for the gate oxide, i.e. material with a higher dielectric constant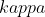 , as an alternative way of increasing the gate oxide capacitance (k and
, as an alternative way of increasing the gate oxide capacitance (k and 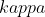 are often used interchangeably in this context). However, recent roadmaps state that the success of this approach is already proving insufficient.
are often used interchangeably in this context). However, recent roadmaps state that the success of this approach is already proving insufficient.
Overall, I believe it is pertinent to say that all kinds of leakage negatively affect performance by simply reducing the available usable power and by causing excessive heat dissipation, placing higher demands on packaging.
Two (gated) papers that describe these leakage issues in more detail (and there is a lot more detail to it) can be found here and here.
(cont'd)
(cont'd from previous comment)
Did the industry predict these problems and their consequences?
People in the industry were well aware of these limitations, long before they actually became critical. However, whether solutions and workarounds would be found was a matter of much greater uncertainty.
Robert Dennard et al's seminal 1974 paper Design of Ion-Implanted MOSFETs with Very Small Physical Dimensions, that described the very favourable scaling properties of MOSFET transistors and gave rise to the term "Dennard scaling", explicitly mentions the ... (read more)