There is a new paper by Liu et al. that claims to have understood the key mechanism underlying grokking (potentially even generalization more broadly).
They argue:
1. Grokking can be explained via the norm of the weights. They claim that there is a constant level of the weight norm that is optimal for generalization.
2. If there is an optimal level of the weight norm, the weight norm of your model after initialization can be either too low, too high or optimal. They claim that grokking is a phenomenon where we initialize the model with a large weight norm and it then slowly walks toward the optimal weight norm and then generalizes.
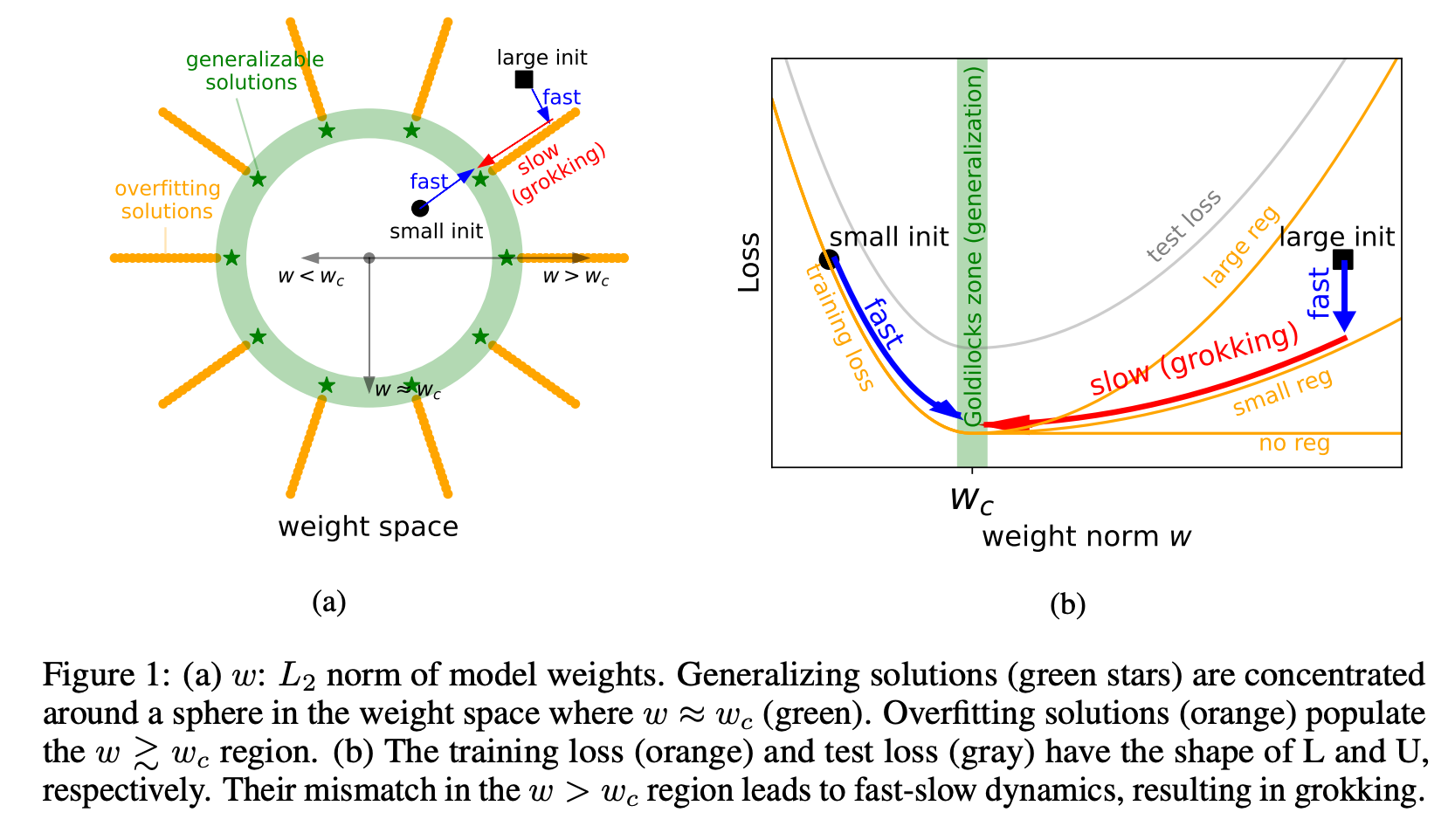
3. They also claim that you can get the same results as grokking but much faster if you set the weight norm correctly at every step.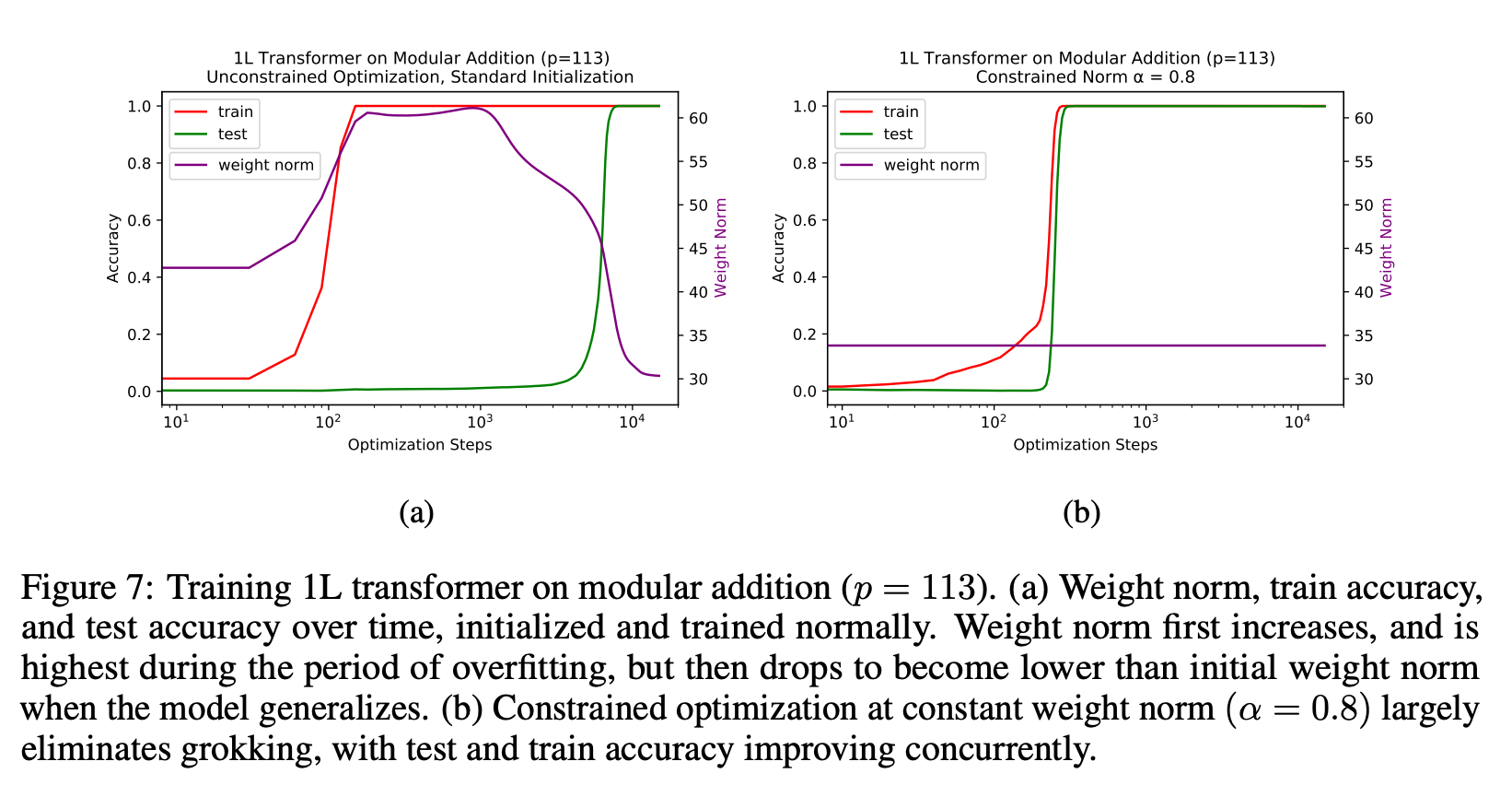
4. They set the norm "correctly" by rescaling the weights after each unconstrained optimization step (so after every weight update loss.backward()?!)
Implications:
- I think they have found a very important insight of grokking and finding generalizing circuits more broadly.
- I'm still a bit skeptical of some of the claims and results. On some level "just fix your weight norm and the model generalizes" sounds too simple to be true for all tasks.
- I think this result could have big implications but I'm not yet sure whether they are positive or negative. On the one hand, finding generalizing circuits seems to solve some of the problems associated with bad out-of-distribution generalization. On the other hand, it likely speeds up capabilities.
I'm very unsure about this paper but intuitively it feels important. Thoughts?
To me, the main insight in the paper is that the norm of the initial weights matter, and not just weight decay/other forms of regularization! IE, while people have plotted weight norm as a function of training time for grokking/nongrokking networks, people have not, afaik, plotted initial weight norm vs grokking. I had originally thought that overfitting would just happen, since memorization was "easier" in some sense for SGD to find in general. So it's a big update for me that the initial weight norm matters so much.
I don't think grokking per se is particularly important, except insofar as neat puzzles about neural networks are helpful for understanding neural networks. As both this paper and Neel/Lieberum's grokking post argue, grokking happens when there's limited data that's trained for a long time, which causes SGD to initially favor memorization, and some form of regularization, which causes the network to eventually get to a generalizing solution. (Assuming large enough initializations.) But in practice, large foundation models are not trained for tens of thousands of epochs on tiny datasets, but instead a single digit number of epochs on a large dataset (generally 1). Also, if the results from this paper (where you need progressively larger weight initializations to get grokking with larger models/larger datasets, then it seems unlikely that any large model is in the grokking regime).
So I think there's something else going on behind the rapid capability gains we see in other networks as we scale the amount of training data/train steps/network parameters. And I don't expect that further constraining the weight norm will speed up generalization on current large models.
That being said, I do think the insight that the norms of the initial weight matter for generalization seems pretty interesting!
Nitpick: I'm really not a fan of people putting the number of steps on a log scale, since it makes grokking look far more sudden than it actually is, while making the norm's evolution look smoother than it is. Here's what the figures look like for 5 random seeds on the P=113 modular addition task, if we don't take log of the x axis: https://imgur.com/a/xNhHDmR
Another nitpick: I thought it was confusing that the authors used "grokking" to mean "delay in generalization" and "de-grokking" to mean "generalization". This seems the opposite of what "grok" actually means?
EDIT: Also, I'm not sure that I fully understand or buy the claim that "representation learning is key to grokking".
Excellent comment. Independently same main takeaway here. Thanks for the pictures!
Agree with nitpick, although I get why they restrict the term "grok" to mean "test loss minimum lagging far behind training loss minimum". That's the mystery and distinctive pattern from the original paper, and that's what they're aiming to explain.