Elhage et al at Anthropic recently published a paper, Toy Models of Superposition (previous Alignment Forum discussion here) exploring the observation that in some cases, trained neural nets represent more features than they “have space for”--instead of choosing one feature per direction available in their embedding space, they choose more features than directions and then accept the cost of “interference”, where these features bleed over into each other. (See the SoLU paper for more on the Anthropic interpretability team’s take on this.)
We (Kshitij Sachan, Adam Scherlis, Adam Jermyn, Joe Benton, Jacob Steinhardt, and I) recently uploaded an Arxiv paper, Polysemanticity and Capacity in Neural Networks, building on that research. In this post, we’ll summarize the key idea of the paper.
We analyze this phenomenon by thinking about the model’s training as a constrained optimization process, where the model has a fixed total amount of capacity that can be allocated to different features, such that each feature can be ignored, purely represented (taking up one unit of capacity), or impurely represented (taking up some amount of capacity between zero and one units).
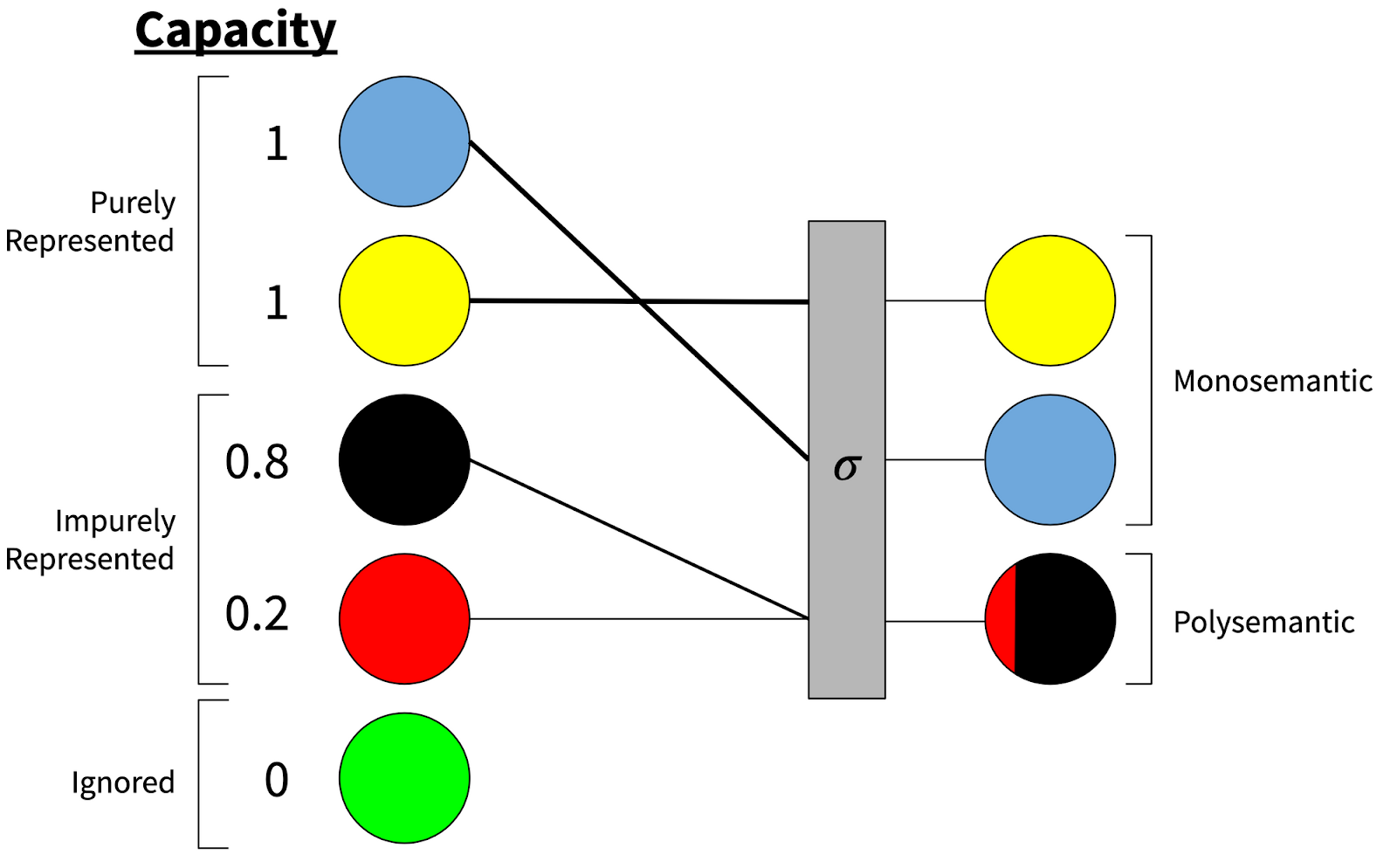
When the model purely represents a feature, that feature gets its own full dimension in embedding space, and so can be represented monosemantically; impurely represented features share space with other features, and so the dimensions they’re represented in are polysemantic.
For each feature, we can plot the marginal benefit of investing more capacity into representing that feature, as a function of how much it’s currently represented. Here we plot six cases, where one feature’s marginal benefit curve is represented in blue and the other in black.

These graphs show a variety of different possible marginal benefit curves. In A and B, the marginal returns are increasing–the more you allocate capacity to a feature, the more strongly you want to allocate more capacity to it. In C, the marginal returns are constant (and in this graph they happen to be equal for the two features, but there’s no reason why constant marginal returns imply equal returns in general). And then in D, E, and F, there are diminishing marginal returns.
Now, we can make the observation that, like in any budget allocation problem, if capacities are allocated optimally, the marginal returns for allocating capacity to any feature must be equal (if the feature isn’t already maximally or minimally represented). Otherwise, we’d want to take capacity away from features with lower dLi/dCi and give it to features with higher dLi/dCi .
In the case where we have many features with diminishing marginal returns, capacity will in general be allocated like this:
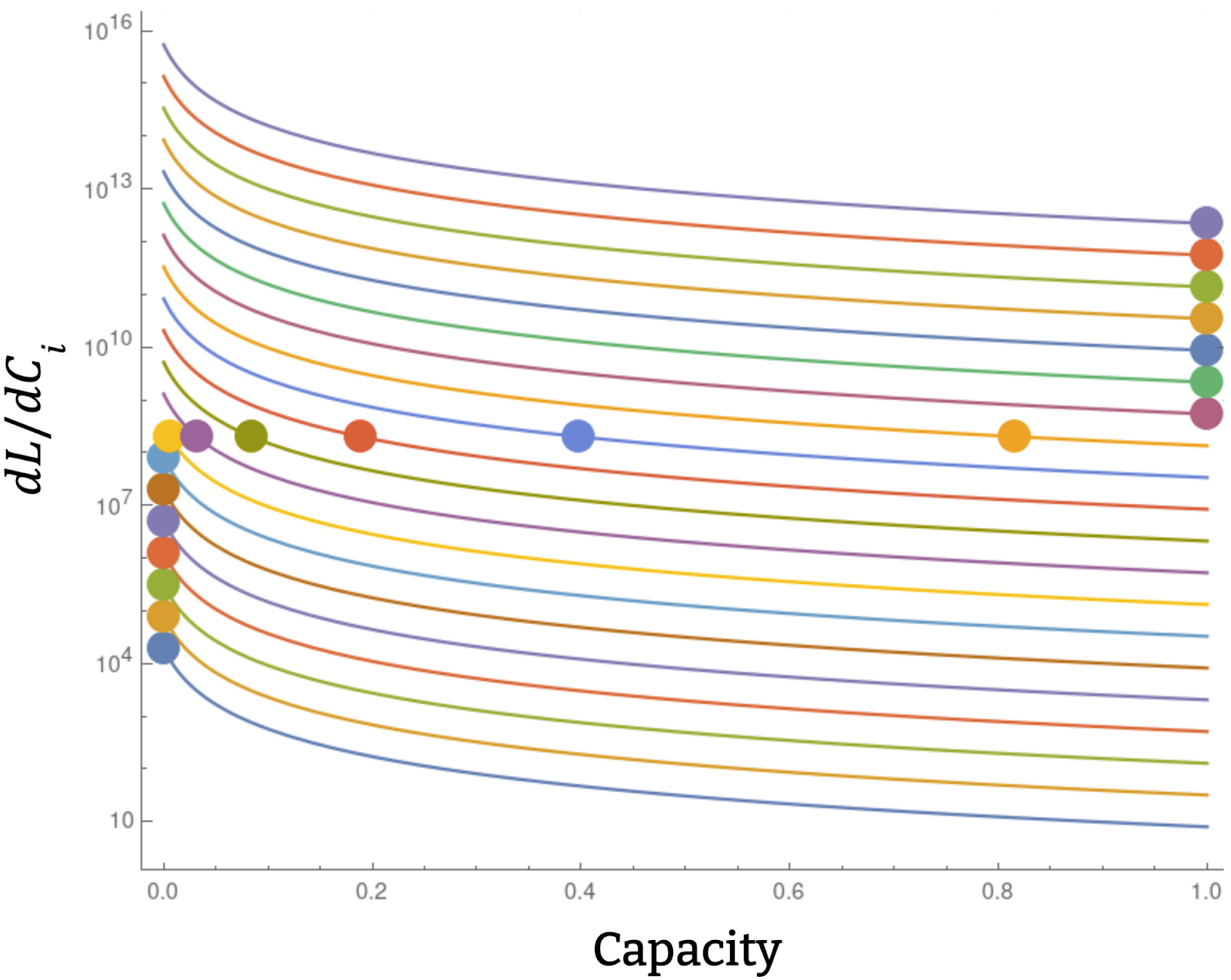
Here the circles represent the optimal capacity allocation for a particular total capacity.
This perspective suggests that polysemanticity will arise when there are diminishing marginal returns to capacity allocated to particular features (as well as in some other situations that we think are less representative of what goes on in networks).
In our paper, we do the following:
- We describe a particularly analytically tractable model which exhibits polysemanticity.
- We analyze our model using the capacity framework, derive the above graphs, and replicate them numerically.
- Elhage et al empirically observe that increasing the sparsity increases superposition. We analytically ground this observation by decomposing our toy model’s loss into two terms that directly correspond to the benefits and costs of superposition. As the input data becomes sparser, the kurtosis increases, and as the kurtosis increases the loss more heavily favors superposition.
- We explain the phase transitions observed in our model, which look similar to the phase transitions observed in Elhage et al–the sharp lines are because the capacities eventually hit 0 or 1, and at low sparsity you never see features represented impurely because the marginal returns curves don’t have diminishing returns. We can use this understanding to analytically derive the phase diagram:

- Lastly, in Elhage et al’s toy model, features were often partitioned into small distinct subspaces; we explore this as a consequence of optimal allocation of capacity: we find a block-semi-orthogonal structure, with differing block sizes in different models.
How important or useful is this? We’re not sure. For Redwood this feels like more of a side-project than a core research project. Some thoughts on the value of this work:
- We suspect that the capacity framework is getting at some important aspects of what’s going on in the training process for real neural networks, though probably the story in large models is probably substantially messier.
- We think that our results are helpful additions to the story laid out in Elhage et al.
- We think it’s nice to have some extremely simple examples where we understand polysemanticity very well. E.g. We’ve found it helpful to use our toy model as a testcase when developing interpretability techniques that should work in the presence of polysemantic neurons.




Right! Two quick ideas:
Although it's not easy to determine the full set of "natural" features for arbitrary networks, still you might be able to solve an optimization problem that identifies the single feature with most negative marginal returns to capacity given the weights of some particular trained network. If you could do this then perhaps you could apply a regularization to the network that "flattens out" the marginal returns curve for just that one feature, then apply further training to the network and ask again which single feature has most negative marginal returns to capacity given the updated network weights, and again flatten out the marginal returns curve for that one feature, and repeat until there are no features with negative marginal returns to capacity. Doing this feature-by-feature would be too slow for anything but toy networks, I suppose, but if it worked for toy networks then perhaps it would point the way towards something more scalable.
Suppose instead you can find the least important (lowest absolute value of dL/dC_i) feature given some particular set of weights for a network and mask that feature out from all the inputs, and the iterate in the same way as above. In the third figure from the top in your post -- the one with the big vertical stack of marginal return curves -- you would be chopping off the features one-by-one from bottom to top, ideally until you have exactly as many features as you can "fit" monosemantically into a particular architecture. I suppose again that doing this feature-by-feature for anything but a toy model would be prohibitive, but perhaps there is a way to do it more efficiently. I wonder whether there is any way to "find the least important feature" and to "mask it out".