OK suppose you have an agent that does perform remote control by explicitly forming a world model and then explicitly running a search process. I claim that if the world modelling process and the planning process are both some kind of gradient descent, then I can construct an agent that does the same remote control without explicitly forming a world model (though it will in general require more computation)
Start with some initial plan. Repeat:
- Sample N world models
- Evaluate the modelling objective for each one
- Perform a gradient step on the plan, for each of the N world models, weighted according to the modelling objective
This algorithm never really stores a "current best" world model nor a distribution of possible world models, but by SGD convergence proofs it should converge to the same thing as if you computed an explicit probability distribution over world models at the outset, using the modelling objective as a probability measure, and then performed planning search with respect to that.
If we were given only machine code for the algorithm I wrote above, it might be very difficult to disentangle what is "world model" and what is "planning". You would certainly never find, stored anywhere in computer memory, a world model representing the agent's overall beliefs given available data.
I suspect that I could further entangle the world modelling and planning parts of the algorithm above, to the point that it would be very difficult to objectively say that the algorithm is "really" forming a world model.
However, what would be very interesting would be to show that the most computationally efficient version of the above necessarily disentangles world modelling from planning.
Can anybody give/reference an ELI5 or ELI15 explanation of this example? How can we use the models without creating them? I know that gradient descent is used to update neural networks, but how can you get the predictions of those NNs without having them?
The idea here is that world modelling (working out what the state of the world at the present moment is) and planning (working out what to do given the state of the world at the present moment) might be very tangled up with each other in the source code for some AI agents.
When we think of building agents that act in the world, it's common to imagine that they will first use the information available to them to create a model of the world, and then, given that, formulate a plan to achieve some kind of goal. That's one possible way to build agents, but John's post here actually attempts to say something about the space of all possible agents. While some agents may have nicely separated modelling/planning algorithms, it's not guaranteed that it will be that way at all, and the point of my comment here was to show that for any nicely separated agent, there is a not-nicely-separated agent that arrives at the same plan in the limit of time.
My argument here goes as follows: suppose that you have some agent that is nicely separated into world modelling and planning submodules/sub-algorithms. Then you can use the three dot points in my comment to construct source code for a new agent that does the same thing, but is not nicely separated. The point of this is to show that it cannot be that the best or most optimal agents are nicely separated, because for every nicely separated agent source code, there is an equally-good not-nice-separated agent source code.
Then you can use the three dot points in my comment to construct source code for a new agent that does the same thing, but is not nicely separated.
This is the step I don't get (how we make the construction), because I don't understand SGD well. What does "sample N world models" mean?
My attempt to understand: We have a space of world models () and a space of plans (). We pick points from (using SGD) and evaluate them on the best points of (we got those best points by trying to predict the world and applying SGD).
My thoughts/questions: To find the best points of , we still need to do modelling independently from planning? While the world model is not stored in memory, some pointer to the best points of is stored? We at least have "the best current plan" stored independently from the world models?
I suspect it could be useful to delineate what does and does not count for the purposes of the problem. For example, a black hole literally "steers far-away parts of the world into a relatively-small chunk of their state space". However, barring some string theory weirdness, it does not have "an internal world-model and search process", mostly because it is all vacuum.
Would it be sufficient, for disproof, to show one system that does steer far-away parts of the world into a relatively-small chunk of their state space, but does not internally contain a world-model or do planning?
That could be sufficient in principle, though I would not be surprised if I look at a counterexample and realize that the problem description was missing something rather than that the claim is basically false. For instance, it wouldn't be too surprising if there's some class of supposed-counterexamples which only work under very specific conditions (i.e. they're not robust), and can be ruled out by some "X isn't very likely to happen spontaneously in a large system" argument.
The bottom line is that a disproof should argue that there isn't anything basically like the claim which is true. Finding a physical counterexample would at least show that the counterexample isn't sensitive to the details of mathematical framework/formulation.
Do you have a particular counterexample in mind? A thermometer, perhaps?
Well ok just to brainstorm some naive things that don't really rule the conjecture out:
-
A nuclear bomb steers a lot of far-away objects into a high-entropy configuration, and does so very robustly, but that perhaps is not a "small part of the state space"
-
A biological pathogen, let loose in a large human population, might steer all the humans towards the configuration "coughing", but the virus is not itself a consequentialist. You might say that the pathogen had to have been built by a consequentialist, though.
-
Generalizing the above: Suppose I discover some powerful zero-day exploit for the linux kernel. I automate the exploit, setting my computer up to wait 24 hours and then take over lots of computers on the internet. Viewing this whole thing from the outside, it might look as if it's my computer that is "doing" the take-over, but my computer itself doesn't have a world model or a planning routine.
-
Consider some animal species spreading out from an initial location and making changes to the environments they colonize. If you think of all the generations of animals that underwent natural selection before spreading out as the "system that controls some remote parts of the system" and the individual organisms as kind of messages or missiles, then this seems like a pretty robust, though slow form of remote control. Maybe you would say that natural selection has a world model and a planning process, though.
These are interesting examples!
In the first example there's an element of brute force. Nuclear bombs only robustly achieve their end states because ~nothing is robust to that kind of energy. In the same way that e.g. humans can easily overcome small numbers of ants. So maybe the theorem needs to specify that the actions that achieve the end goal need to be specific to the starting situation? That would disqualify nukes because they just do the same thing no matter their environments.
In the third example, the computer doesn't robustly steer the world. It only steers the world until someone patches that exploit. Whereas e.g. an agent with a world model and planning ability would still be able to steer the world by e.g. discovering other exploits.
I think the same objection holds for the second example: to the extent that the pathogen doesn't evolve it is unable to robustly steer the world because immune systems exist and will adapt (by building up immunity or by humans inventing vaccines etc.). To the extent that the pathogen does evolve it starts to look like the fourth example.
I think the fourth example is the one that I'm most confused about. Natural selection kind of has a world model, in the sense that the organisms have DNA which is adapted to the world. Natural selection also kind of has a planning process, it's just a super myopic one on the time-scale of evolution (involving individuals making mating choices). But it definitely feels like "natural selection has a world model and planning process" is a sentence that comes with caveats, which makes me suspect that these may not be the right concepts.
I think the fourth example is the one that I'm most confused about. Natural selection kind of has a world model, in the sense that the organisms have DNA which is adapted to the world. Natural selection also kind of has a planning process, it's just a super myopic one on the time-scale of evolution (involving individuals making mating choices). But it definitely feels like "natural selection has a world model and planning process" is a sentence that comes with caveats, which makes me suspect that these may not be the right concepts.
Yeah I think you've said it well here.
Another similar example: Consider a computer that trains robots and deploys a new one. Suppose for the sake of this example that the individual robots definitely do not do planning or have a world model, but still can execute some simple policy such as "go to this place, collect this resource, construct this simple structure, etc". The computer that trains and deploys the robots does so by taking all the robots that were deployed on the previous day, selecting the ones that performed best according to a certain objective such as collecting a certain resource, and deploying more robots like that. This is a basic evolutionary algorithm.
Like in the case of evolution, it's a bit difficult to say where the "world model" and "planning process" are in this example. If they are anywhere, they are kind of distributed through the computer/robot/world system.
OK now consider a modification to the above example. The previous example is going to optimize very slowly. Suppose we make the optimization go faster in the following way: we collect video data from each of the robots, and the central computer uses the data collected by each of the robots on the previous day to train, using reinforcement learning rather than evolutionary search, the robots for the next day. To do this, it trains, using supervised learning on the raw video data, a predictor that maps robot policies to predicted outcomes, and then, using reinforcement learning, searches for robot policies that are predicted to perform well. Now we have a very clear world model and planning process -- the world model is the trained prediction function and the planning process is the search over robot policies with respect to that prediction function. But the way we got here was as a performance optimization of a process that had a very unclear world model and planning process.
It seems to me that human AI engineers have settled on a certain architecture for optimizing design processes. That architecture, roughly speaking, is to form an explicit world model and do explicit search over it. But I suspect this is just one architecture by which one can organize information in order to take an action. It seems like a very clean architecture to me, but I'm not sure that all natural processes that organize information in order to take an action will do so using this architecture.
I mean, "is a large part of the state space" is basically what "high entropy" means!
For case 3, I think the right way to rule out this counterexample is the probabilistic criterion discussed by John - the vast majority of initial states for your computer don't include a zero-day exploit and a script to automatically deploy it. The only way to make this likely is to include you programming your computer in the picture, and of course you do have a world model (without which you could not have programmed your computer)
But the vast majority of initial states for a lump of carbon/oxygen/hydrogen/nitrogen atoms do not include a person programming a computer with the intention of taking over the internet. Shouldn't you apply the same logic there that you apply to the case of a computer?
In fact a single zero day exploit is certainly much simpler than a full human, so aprior it's more likely for a computer with a zero day exploit to form from the void than for a computer with a competent human intent on taking over the internet to form from the void.
A nuclear bomb steers a lot of far-away objects into a high-entropy configuration, and does so very robustly, but that perhaps is not a "small part of the state space"
This example reminds me of a thing I have been thinking about, namely that it seems like optimization can only occur in cases where the optimization produces/is granted enough "energy" to control the level below. In this example, the model works in a quite literal way, as a nuclear bomb floods an area with energy, and I think this example generalizes to e.g. markets with Dutch disease.
Flooding the lower level with "energy" is presumably not the only way this problem can occur; lack of incentives/credit assignment in the upper level generates this result simply because no incentives means that the upper level does not allocate "energy" to the area.
Yeah I think you're right. I have the sense that the pure algorithmic account of optimization -- that optimization is about algorithms that do search over plans using models derived from evidence to evaluate each plan's merit -- doesn't quite account for what an optimizer really is in the physical world.
The thing is that I can implement some very general-purpose modelling + plan-search algorithm on my computer (for example, monte carlo versions of AIXI) and hook it up to real sensors and actuators and it will not do anything interesting much at all. It's too slow and unreflective to really work.
Therefore, an object running a consequentialist computation is definitely not a sufficient condition for remote control as per John's conjecture, but perhaps it is a necessary condition -- that's what the OP is asking for a proof or disproof of.
I feel very confused about the problem. Would appreciate anyone's help with the questions below.
- Why doesn't the Gooder Regulator theorem solve the Agent-Like Structure Problem?
- The separation between the "world model", "search process" and "problem specification" should be in space (not in time)? We should be able to carve the system into those parts, physically?
- Why would problem specification nessecerily be outside of the world model??? I imagine it could be encoded as an extra object in the world model. Any intuition for why keeping them separate is good for the agent? (I'll propose one myself, see 5.)
- Why are the "world model" and "search process" two different entities, what does each of them do? What is the fundamental difference between "modeling the world" and "searching"? Like, imagine I have different types of heuristics (A, B, C) for predicting the world, but I also can use them for search.
- Doesn't the inner alignment problem resolve the Agent-Like Structure Problem? Let me explain. Take a human, e.g. me. I have a big, changing brain. Parts of my brain can be said to want different things. That's an instance of the inner alignment problem. And that's a reason why having my goals completely entangled with all other parts of my brain could be dangerous (in such case it could be easier for any minor misalignment to blow up and overwrite my entire personality).
- As I understand, the arguments from here would at least partially solve the problem, right? If they were formalized.
- Premise (as stated by John): “a system steers far-away parts of the world into a relatively-small chunk of their state space”
- Desired conclusion: The system is very likely (probability approaching 1 with increasing model size / optimization power / whatever) consequentialist, in that it has an internal world-model and search process.
But why would we expect this to be true? What are the intuitions informing this conjecture?
Off the top of my head:
- The system would need to have a world-model because controlling the world at some far-away point requires (1) controlling the causal path between the system and that point, and (2) offsetting the effects of the rest of the world on that point, both of which require predicting and counteracting-in-advance the world's effects. And any internal process which lets a system do that would be a "world model", by definition.
- The system would need some way to efficiently generate actions that counteract the world's intrusions upon what it cares about, despite being embedded in the world (i. e., having limited knowledge, processing capacity, memory) and frequently encountering attacks it's never encountered before. Fortunately, there seem to be some general-purpose algorithm(s) that can "extract" solutions to novel problems from a world-model in a goal-agnostic fashion, and under embeddedness/real-world conditions, optimizing systems are likely/required to converge to it.
Put like this, there are obvious caveats needed to be introduced. For example, the "optimizing system + optimization target" system needs to be "fully exposed" to the world — if we causally isolate it from most/all of the world (e. g., hide it behind an event horizon), many optimization targets would not require the optimizing system to be a generalist consequentialist with a full world-model. Simple heuristics that counteract whatever limited external influences remain would suffice.
Another way to look at this is that the system needs to be steering against powerful counteracting influences, or have the potential to arrive at strategies to steer against arbitrary/arbitrarily complex counteracting influences. Not just a thermostat, but a thermostat that can keep the temperature in a room at a certain level even if there's a hostile human civilization trying to cool the room down, stuff like this.
Which can probably all be encompassed by a single change to the premise: "a system robustly steers far-away parts of the world into a relatively-small chunk of their state space".
I actually originally intended robustness to be part of the problem statement, and I was so used to that assumption that I didn't notice until after writing the post that Thomas' statement of the problem didn't mention it. So thank you for highlighting it!
Also, in general, it is totally fair game for a proposed solution to the problem to introduce some extra conditions (like robustness). Of course there's a very subjective judgement call about whether a condition too restrictive for a proof/disproof to "count", but that's the sort of thing where a hindsight judgement call is in fact important and a judge should think it through and put in some effort to explain their reasoning.
I think I'm probably missing the point here somehow and/or that this will be perceived as not helpful. Like, my conceptions of what you mean, and what the purpose of the theorem would be, are both vague.
But I'll note down some thoughts.
Next, the world model. As with the search process, it should be a subsystem which interacts with the rest of the system/environment only via a specific API, although it’s less clear what that API should be. Conceptually, it should be a data structure representing the world.
(...)
The search process should be able to run queries on the world model
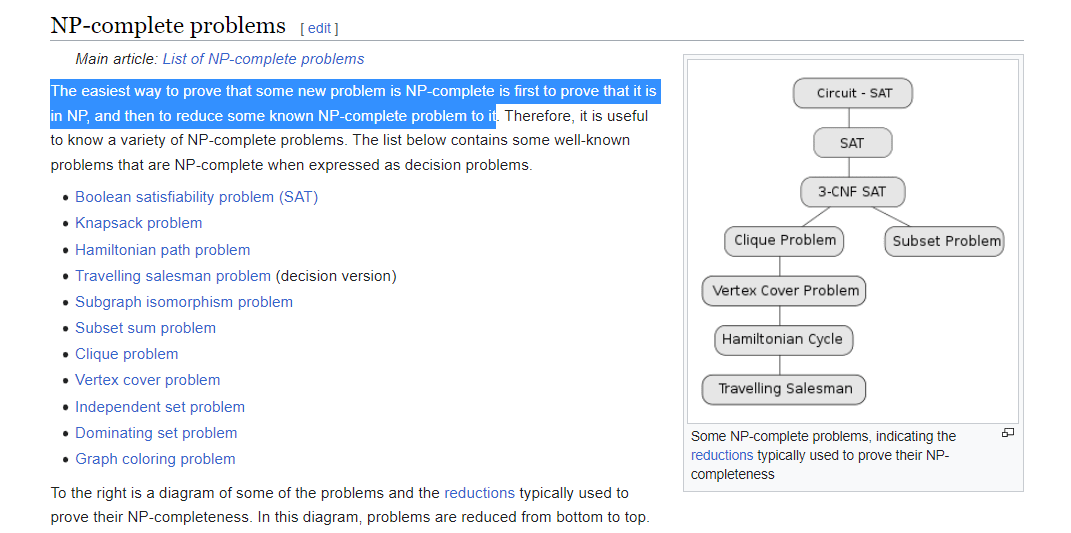
Problems can often be converted into other problems. This can be for both the top-level problem and recursively for sub-problems. One example of this is how NP-completene problems by definition can be converted into other NP-problems in polynomial time:
And as humans we are fairly limited in terms of finding and leveraging abstractions like these. What we are able to do (in terms of converting tasks/problems into more "abstracted" tasks/problems) ≠ what's possible to do.
So then it's not necessarily necessary to be able to do search in a world model? Since very powerful optimizers maybe can get by while being restricted to searching within models that aren't world models (after having converted whatever it is they want to maximize into something more "abstract", or into a problem that corresponds to a different world/ontology - be that wholesale or in "chunks").
I was browsing your posts just now, partly to see if I could get a better idea of what you mean by the terms you use in this post. And I came across What's General-Purpose Search, And Why Might We Expect To See It In Trained ML Systems?, which seems to describe either the same phenomena as the what I'm trying to point to, or at least something similar/overlapping. And it's a good post too (it explains various things better than I can remember hearing/reading elsewhere). So that increases my already high odds that I'm missing the point somehow.
But, depending on what the theorem would be used for, the distinction I'm pointing to could maybe make an important difference:
For example, we may want to verify that certain capabilities are "aligned". Maybe we have AIs compete to make functions that do some specialized task as effectively/optimally as possible, as measured by various metrics.
Some specialized tasks may be tasks where we can test performance safely/robustly, while for other tasks we may only be able to do that for some subset of all possible outputs/predictions/proposals/etc. But we could for example have AIs compete to implement both of these functions with code that overlaps as little as possible[1].
For example, we may want functions to do is to predict human output (e.g. how humans would answer various questionnaires based on info about those humans). But we may not be able/willing to test the full range of predictions that such functions make (e.g., we may want to avoid exposing real humans to AGI-generated content). However, possible ways to implement such functions may have a lot of overlap with functions where we are able/willing to test the full range of predictions. And we may want to enforce restrictions/optimization-criteria such that it becomes hard to make functions that (1) get maximum score and (2) return wrong output outside of the range where we are able/willing to test/score output and (3) don't return wrong/suboptimal output inside of the range where we are able/willing to test/score output.
To be clear, I wouldn't expect world models to always/typically be abstracted/converted before search is done if what we select for simply is to have systems that do "the final task we are interested in" as effectively/optimally as possible, and we pretty much try to score/optimize/select for that thing in the most straightforward way we can (when "training" AIs / searching for AI-designs). But maybe there sometimes would be merit to actively trying to obtain/optimize systems that "abstract"/convert the model before search is done.
- ^
As well as optimizing for other optimization-criteria that incentivize for the task to be "abstracted"/converted (and most of the work to be done on models that have been "abstracted"/converted).
A few months ago, Thomas Kwa put together a statement of a potential “holy grail” of Selection Theorems and put a prize on it:
I’ll call this the Agent-Like Structure Problem for purposes of this post (though I’ll flag that other researchers might prefer a different formulation of the agent-like structure problem). For some background on why we might expect a theorem like this, see What’s General-Purpose Search, And Why Might We Expect To See It In Trained ML Systems?.
Since Thomas’ prize announcement, I’ve had a couple other people ask me about potential prize problems. Such people usually want me to judge submissions for their prize, which is a big ask - good alignment problems are usually not fully formalized, which means judging will inevitably involve explaining to people how their “solution” isn’t really solving the intended problem. That’s a lot of stressful work.
The goal of this post is to explain the Agent-Like Structure Problem (as I see it) in enough detail that I’d be willing-in-principle to judge submissions for a prize on the problem (see final section for terms and conditions). In particular, I’ll talk about various ways in which I expect people will solve the wrong problem.
What Do We Want To Show?
Here’s Thomas’ statement of the problem again:
[EDIT: I didn't realize until after writing the post that Thomas' description left out robustness; it should say “a system robustly steers far-away parts of the world into a relatively-small chunk of their state space”. Thankyou Thane for highlighting that.]
The Basic Foundations For Agent Models sequence (especially Utility Maximization = Description Length Minimization and Optimization at a Distance), along with the Telephone Theorem post, gives some good background on the intended meaning of “far-away parts of the world” and “steering into a relatively-small chunk of state space”. The prototypical picture there is of an environment represented as a big graphical model, with some subgraph distinguished as the “system”. Far-away-ness is then formulated in terms of nested Markov blankets. Also see the Compression section of What's General Purpose Search... for a rough idea of where I expect the "probability approaching 1 with increasing model size / optimization power / whatever" part to fit in; that part is mainly to allow compression arguments.
(A potential solution to the problem would not necessarily need to use the probabilistic graphical model framework to represent the system/environment; I’m using it as a prototypical picture rather than a strict desiderata. More on that later.)
But what do we mean by the system “having an internal world-model and search process”?
Let’s start with the search process. There’s a common misconception that “search” is about enumerating possible actions and evaluating their consequences; that’s not what we’re talking about here. (I’d call that “brute-force search”.) When I talk about a “search process”, I mean something which:
The key is that this “API” summarizes the entire interaction between the search-process-subsystem and the rest of the system. There’s an implicit claim of modularity here: the search process subsystem is mostly isolated from the rest of the system, and interacts only via a problem/goal specification going in, and a plan/solution going out. The problem/goal specification and plan/solution together form a Markov blanket separating the search process from the rest of the system/environment. That’s what makes the search process a “structural” feature of the system.
Next, the world model. As with the search process, it should be a subsystem which interacts with the rest of the system/environment only via a specific API, although it’s less clear what that API should be. Conceptually, it should be a data structure representing the world. Some likely parts of the API of that data structure:
Note that, for both the search process and the world model, the Markov blanket around the subsystem is probably statistical - e.g. cosmic rays may occasionally flip bits in my brain’s world model (thereby violating the Markov blanket), but that effect should be “random noise” in some sense, not providing any informative signal from outside the blanket. So some causal effects can sometimes violate the blanket, so long as the statistical information violating the blanket is approximately zero.
Some More Desiderata
A potential solution to the problem would not necessarily need to use the probabilistic graphical model framework to represent the system/environment, but the framework does need to be expressive enough to plausibly represent our everyday world. For instance, a solution which assumes the environment is an MDP (i.e. no hidden state) would not cut it. Neither would a solution which assumes the environment is a state machine with less-than-exponentially-many states. On the other hand, the framework doesn’t necessarily need to be able to handle e.g. quantum mechanics neatly; it’s perfectly fine to ignore things which aren’t central to humans’ everyday lives.
Similarly, a potential solution framework should be expressive enough to talk about neural nets or biological organisms in principle, without some kind of exponential blow-up. So for instance, if we’re using state machines as a model, the theory had better play very well with exponentially large state spaces.
Anticipated Failure Modes For Solution Attempts
(This section may be expanded in the future.)
Behavioral Equivalence
First up, behavior equivalence gets no credit. Standard coherence theorems or the Good Regulator theorem, for instance, all get zero credit because they only show behavioral equivalence. We’re interested in internal structure here; thus all the talk about Markov blankets.
Disproof Has A Higher Bar Than Proof
One particularly common failure mode I expect to see is that someone models the system/environment as arbitrary programs, something something Rice’s Theorem, and therefore the claim is disproven. But this argument does not actually make me think it’s less likely that the claim actually applies in practice, because neither real world agents nor real world environments are arbitrary programs, and also they have to formulate the claim in a kinda specific way in order to make it fit Rice’s Theorem.
More generally: any attempted proof/disproof will need to use a particular framework for the system/environment, and will need to formulate the hand-wavy parts of the claim in some precise way. In order to be useful, a proof can use any framework which plausibly applies to the real world. A disproof, on the other hand, needs to rule out all possible frameworks which plausibly apply to the real world. In that sense, the bar for disproof is higher than for proof.
How could a disproof rule out all possible frameworks? Gödel’s Incompleteness Theorem is a good example. It was stated for a particular framework for arithmetic (Peano arithmetic IIRC), but the proof carries over in an obvious way to any other sufficiently-expressive arithmetic system.
Environment Restrictions
One especially relevant place where the bar for disproof is higher than for proof: assumptions on the structure of the environment. It is probably possible to “disprove” the claim by assuming some very general environment (like an arbitrary program, for instance), much like we can “prove” that learning is impossible because it takes exponentially many data points to learn <very general class of functions>.
The real world has lots of nice structure to it, so any potential “disproof” needs to hold even when we restrict the environment to realistic kinds of nice structure - like e.g. a spacetime causal structure, Planck volume, finite speed of information propagation, and physical laws which are symmetric in space and time.
Info for Prize Organizers
That completes the object-level post. I’ll wrap up with some meta-info for people who might want to put a prize on this problem.
You are of course welcome to judge submissions yourself. Indeed, I encourage that. If you want me to judge submissions for your prize, then I have two main conditions:
The main goal is to avoid me needing to deal with a flood of bright-eyed young people who did not understand what the problem was, who had grand dreams of $X and the glory of winning the Agent-Like Structure Problem Prize, and are simultaneously crushed and confused when their brilliant solution is turned down.