A few months ago, Thomas Kwa put together a statement of a potential “holy grail” of Selection Theorems and put a prize on it:
The ultimate goal of John Wentworth’s sequence "Basic Foundations for Agent Models" is to prove a selection theorem of the form:
- Premise (as stated by John): “a system steers far-away parts of the world into a relatively-small chunk of their state space”
- Desired conclusion: The system is very likely (probability approaching 1 with increasing model size / optimization power / whatever) consequentialist, in that it has an internal world-model and search process. Note that this is a structural rather than behavioral property.
John has not yet proved such a result and it would be a major advance in the selection theorems agenda. I also find it plausible that someone without specific context could do meaningful work here. As such, I’ll offer a $5000 bounty to anyone who finds a precise theorem statement and beats John to the full proof (or disproof + proof of a well-motivated weaker statement). This bounty will decrease to zero as the sequence is completed and over the next ~12 months. Partial contributions will be rewarded proportionally.
I’ll call this the Agent-Like Structure Problem for purposes of this post (though I’ll flag that other researchers might prefer a different formulation of the agent-like structure problem). For some background on why we might expect a theorem like this, see What’s General-Purpose Search, And Why Might We Expect To See It In Trained ML Systems?.
Since Thomas’ prize announcement, I’ve had a couple other people ask me about potential prize problems. Such people usually want me to judge submissions for their prize, which is a big ask - good alignment problems are usually not fully formalized, which means judging will inevitably involve explaining to people how their “solution” isn’t really solving the intended problem. That’s a lot of stressful work.
The goal of this post is to explain the Agent-Like Structure Problem (as I see it) in enough detail that I’d be willing-in-principle to judge submissions for a prize on the problem (see final section for terms and conditions). In particular, I’ll talk about various ways in which I expect people will solve the wrong problem.
What Do We Want To Show?
Here’s Thomas’ statement of the problem again:
- Premise (as stated by John): “a system steers far-away parts of the world into a relatively-small chunk of their state space”
- Desired conclusion: The system is very likely (probability approaching 1 with increasing model size / optimization power / whatever) consequentialist, in that it has an internal world-model and search process.
[EDIT: I didn't realize until after writing the post that Thomas' description left out robustness; it should say “a system robustly steers far-away parts of the world into a relatively-small chunk of their state space”. Thankyou Thane for highlighting that.]
The Basic Foundations For Agent Models sequence (especially Utility Maximization = Description Length Minimization and Optimization at a Distance), along with the Telephone Theorem post, gives some good background on the intended meaning of “far-away parts of the world” and “steering into a relatively-small chunk of state space”. The prototypical picture there is of an environment represented as a big graphical model, with some subgraph distinguished as the “system”. Far-away-ness is then formulated in terms of nested Markov blankets. Also see the Compression section of What's General Purpose Search... for a rough idea of where I expect the "probability approaching 1 with increasing model size / optimization power / whatever" part to fit in; that part is mainly to allow compression arguments.
(A potential solution to the problem would not necessarily need to use the probabilistic graphical model framework to represent the system/environment; I’m using it as a prototypical picture rather than a strict desiderata. More on that later.)
But what do we mean by the system “having an internal world-model and search process”?
Let’s start with the search process. There’s a common misconception that “search” is about enumerating possible actions and evaluating their consequences; that’s not what we’re talking about here. (I’d call that “brute-force search”.) When I talk about a “search process”, I mean something which:
- Takes in a problem or goal specification (from a fairly broad range of possible problems/goals)
- … and returns a plan/solution which solves the problem or scores well on the goal
The key is that this “API” summarizes the entire interaction between the search-process-subsystem and the rest of the system. There’s an implicit claim of modularity here: the search process subsystem is mostly isolated from the rest of the system, and interacts only via a problem/goal specification going in, and a plan/solution going out. The problem/goal specification and plan/solution together form a Markov blanket separating the search process from the rest of the system/environment. That’s what makes the search process a “structural” feature of the system.
Next, the world model. As with the search process, it should be a subsystem which interacts with the rest of the system/environment only via a specific API, although it’s less clear what that API should be. Conceptually, it should be a data structure representing the world. Some likely parts of the API of that data structure:
- The world model takes in observations (and probably updates its internal state accordingly)
- The search process should be able to run queries on the world model. Exactly what these queries look like is a wide-open question.
- The problem/goal passed to the search process likely itself involves some pointer(s) into the world model data structure (e.g. goals expressed over latent variables in the world model)
Note that, for both the search process and the world model, the Markov blanket around the subsystem is probably statistical - e.g. cosmic rays may occasionally flip bits in my brain’s world model (thereby violating the Markov blanket), but that effect should be “random noise” in some sense, not providing any informative signal from outside the blanket. So some causal effects can sometimes violate the blanket, so long as the statistical information violating the blanket is approximately zero.
Some More Desiderata
A potential solution to the problem would not necessarily need to use the probabilistic graphical model framework to represent the system/environment, but the framework does need to be expressive enough to plausibly represent our everyday world. For instance, a solution which assumes the environment is an MDP (i.e. no hidden state) would not cut it. Neither would a solution which assumes the environment is a state machine with less-than-exponentially-many states. On the other hand, the framework doesn’t necessarily need to be able to handle e.g. quantum mechanics neatly; it’s perfectly fine to ignore things which aren’t central to humans’ everyday lives.
Similarly, a potential solution framework should be expressive enough to talk about neural nets or biological organisms in principle, without some kind of exponential blow-up. So for instance, if we’re using state machines as a model, the theory had better play very well with exponentially large state spaces.
Anticipated Failure Modes For Solution Attempts
(This section may be expanded in the future.)
Behavioral Equivalence
First up, behavior equivalence gets no credit. Standard coherence theorems or the Good Regulator theorem, for instance, all get zero credit because they only show behavioral equivalence. We’re interested in internal structure here; thus all the talk about Markov blankets.
Disproof Has A Higher Bar Than Proof
One particularly common failure mode I expect to see is that someone models the system/environment as arbitrary programs, something something Rice’s Theorem, and therefore the claim is disproven. But this argument does not actually make me think it’s less likely that the claim actually applies in practice, because neither real world agents nor real world environments are arbitrary programs, and also they have to formulate the claim in a kinda specific way in order to make it fit Rice’s Theorem.
More generally: any attempted proof/disproof will need to use a particular framework for the system/environment, and will need to formulate the hand-wavy parts of the claim in some precise way. In order to be useful, a proof can use any framework which plausibly applies to the real world. A disproof, on the other hand, needs to rule out all possible frameworks which plausibly apply to the real world. In that sense, the bar for disproof is higher than for proof.
How could a disproof rule out all possible frameworks? Gödel’s Incompleteness Theorem is a good example. It was stated for a particular framework for arithmetic (Peano arithmetic IIRC), but the proof carries over in an obvious way to any other sufficiently-expressive arithmetic system.
Environment Restrictions
One especially relevant place where the bar for disproof is higher than for proof: assumptions on the structure of the environment. It is probably possible to “disprove” the claim by assuming some very general environment (like an arbitrary program, for instance), much like we can “prove” that learning is impossible because it takes exponentially many data points to learn <very general class of functions>.
The real world has lots of nice structure to it, so any potential “disproof” needs to hold even when we restrict the environment to realistic kinds of nice structure - like e.g. a spacetime causal structure, Planck volume, finite speed of information propagation, and physical laws which are symmetric in space and time.
Info for Prize Organizers
That completes the object-level post. I’ll wrap up with some meta-info for people who might want to put a prize on this problem.
You are of course welcome to judge submissions yourself. Indeed, I encourage that. If you want me to judge submissions for your prize, then I have two main conditions:
- The prize announcement should link this post and borrow liberally from it, especially emphasizing that I expect the problem to be misinterpreted in various ways which this post discusses.
- Conditional on getting more than ~4 submissions, someone who is not me should prefilter submissions, and check for anything which clearly matches one of the pitfalls mentioned in this post.
The main goal is to avoid me needing to deal with a flood of bright-eyed young people who did not understand what the problem was, who had grand dreams of $X and the glory of winning the Agent-Like Structure Problem Prize, and are simultaneously crushed and confused when their brilliant solution is turned down.
I think I'm probably missing the point here somehow and/or that this will be perceived as not helpful. Like, my conceptions of what you mean, and what the purpose of the theorem would be, are both vague.
But I'll note down some thoughts.
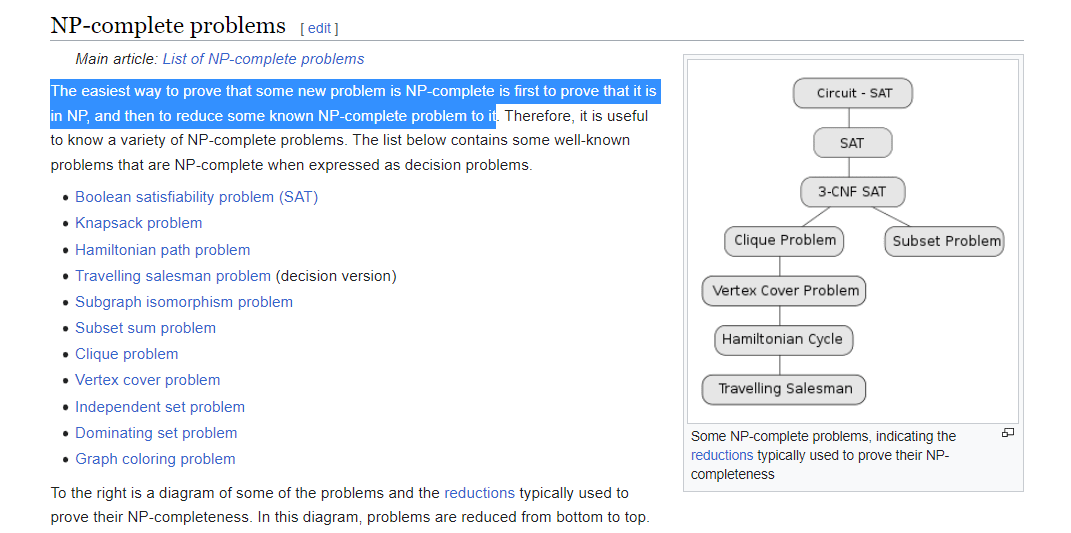
Problems can often be converted into other problems. This can be for both the top-level problem and recursively for sub-problems. One example of this is how NP-completene problems by definition can be converted into other NP-problems in polynomial time:

And as humans we are fairly limited in terms of finding and leveraging abstractions like these. What we are able to do (in terms of converting tasks/problems into more "abstracted" tasks/problems) ≠ what's possible to do.
So then it's not necessarily necessary to be able to do search in a world model? Since very powerful optimizers maybe can get by while being restricted to searching within models that aren't world models (after having converted whatever it is they want to maximize into something more "abstract", or into a problem that corresponds to a different world/ontology - be that wholesale or in "chunks").
I was browsing your posts just now, partly to see if I could get a better idea of what you mean by the terms you use in this post. And I came across What's General-Purpose Search, And Why Might We Expect To See It In Trained ML Systems?, which seems to describe either the same phenomena as the what I'm trying to point to, or at least something similar/overlapping. And it's a good post too (it explains various things better than I can remember hearing/reading elsewhere). So that increases my already high odds that I'm missing the point somehow.
But, depending on what the theorem would be used for, the distinction I'm pointing to could maybe make an important difference:
For example, we may want to verify that certain capabilities are "aligned". Maybe we have AIs compete to make functions that do some specialized task as effectively/optimally as possible, as measured by various metrics.
Some specialized tasks may be tasks where we can test performance safely/robustly, while for other tasks we may only be able to do that for some subset of all possible outputs/predictions/proposals/etc. But we could for example have AIs compete to implement both of these functions with code that overlaps as little as possible[1].
For example, we may want functions to do is to predict human output (e.g. how humans would answer various questionnaires based on info about those humans). But we may not be able/willing to test the full range of predictions that such functions make (e.g., we may want to avoid exposing real humans to AGI-generated content). However, possible ways to implement such functions may have a lot of overlap with functions where we are able/willing to test the full range of predictions. And we may want to enforce restrictions/optimization-criteria such that it becomes hard to make functions that (1) get maximum score and (2) return wrong output outside of the range where we are able/willing to test/score output and (3) don't return wrong/suboptimal output inside of the range where we are able/willing to test/score output.
To be clear, I wouldn't expect world models to always/typically be abstracted/converted before search is done if what we select for simply is to have systems that do "the final task we are interested in" as effectively/optimally as possible, and we pretty much try to score/optimize/select for that thing in the most straightforward way we can (when "training" AIs / searching for AI-designs). But maybe there sometimes would be merit to actively trying to obtain/optimize systems that "abstract"/convert the model before search is done.
As well as optimizing for other optimization-criteria that incentivize for the task to be "abstracted"/converted (and most of the work to be done on models that have been "abstracted"/converted).